使用 Delta Lake 通用格式 (UniForm) 和 Apache XTable 统一开放表格式
Delta Lake 通用格式 (UniForm) 和 Apache XTable™(孵化中)已证明用户可以构建一个不依赖于表格式的开放数据湖仓。这两个完全开源的工具使用户能够写入一份数据,并使其可供下游任何引擎访问。客户端可以将 UniForm 读取为 Delta Lake、Apache Iceberg,现在通过与 XTable 的合作,还可以读取为 Apache Hudi。通过通用支持,您可以在所有 3 个开放表格式生态系统之间无缝互操作,提供数据灵活性,以便为您的 ETL、ML、BI 和分析工作负载选择正确的工具。在本博客中,我们将介绍:
- 为什么用户选择互操作
- 使用 UniForm 和 XTable 构建格式无关的湖仓
- Delta Lake 和 XTable 社区如何协作
解锁所有 3 个开放生态系统
公司已完全采用开放数据湖仓架构。在对高管进行的全球研究中,麻省理工学院技术评论发现 74% 的公司已采用湖仓架构。仅 Delta Lake 就有超过 10,000 家公司在生产中使用,其中包括超过 60% 的财富 500 强企业。组织选择开放表格式是因为它们提供了在单个数据副本上使用任何引擎的自由。尽管所有开放表格式都比专有格式提供更大的灵活性,但湖仓生态系统是碎片化的。对于其架构跨越多个生态系统的组织来说,选择单一格式通常是不现实的。
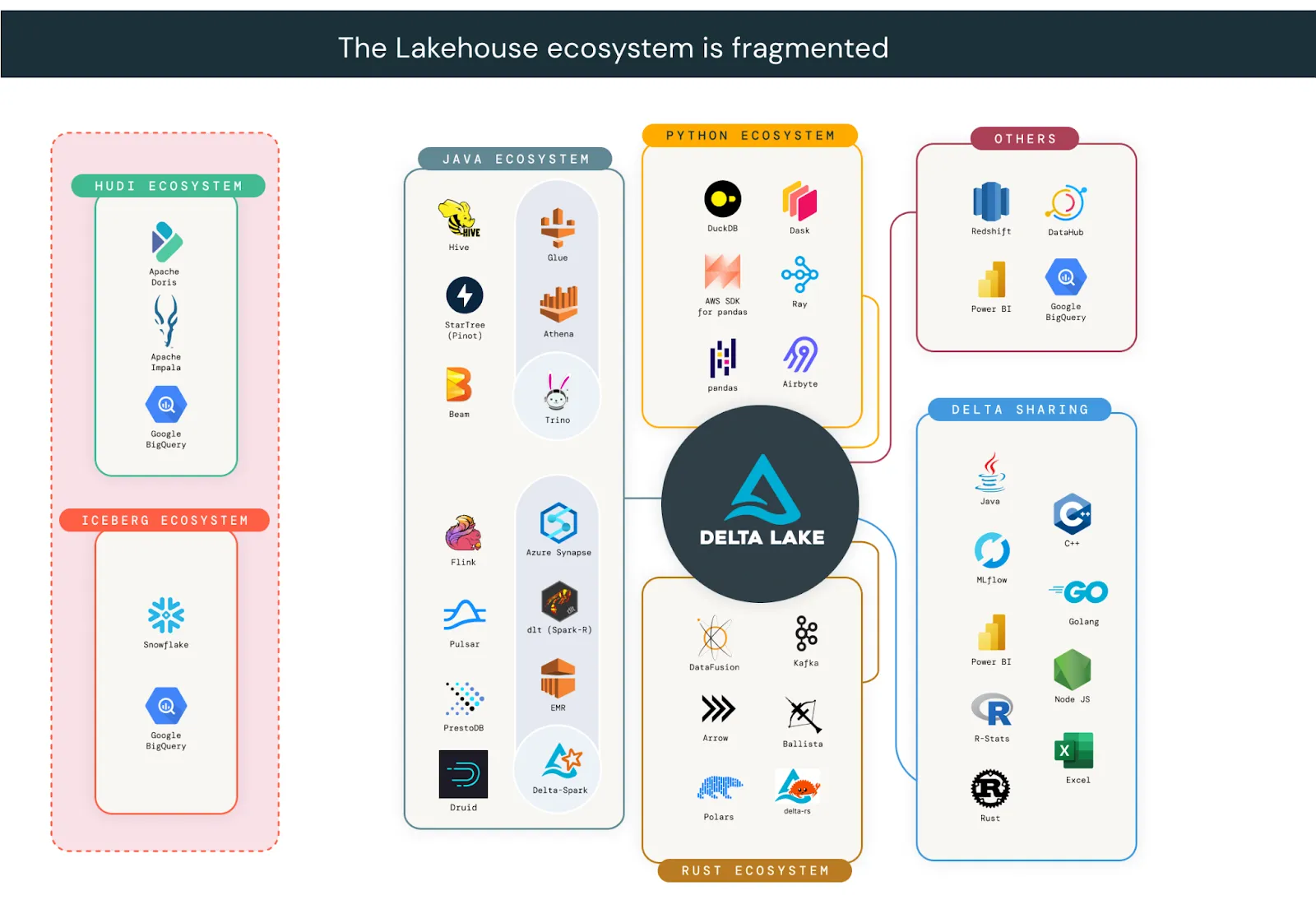
UniForm 和 XTable 正在积极合作,帮助组织构建不受任何单一生态系统限制的架构。这些工具利用了 Delta Lake、Iceberg 和 Hudi 都由基于 Apache Parquet 数据文件的元数据层组成的事实。在微软和谷歌的支持下,XTable 在源格式和目标格式之间转换元数据,同时维护单个数据文件副本。秉持共同目标,XTable 成员在 Delta Lake 仓库中合并了一个 PR,为 UniForm 添加了 Hudi 支持。通过开放源代码社区的合作,Delta Lake 表现在可以通过所有 3 个生态系统中的客户端读取!下一节将展示组织使用 UniForm 和 XTable 的常见用例。
基于 Delta Lake UniForm 和 XTable 的湖仓
自 Delta 3.0 发布以来,UniForm 已证明与流行的 Iceberg 读取客户端兼容。一个常见的 UniForm 用例是使用 Databricks 进行 ETL,并连接到下游的 Snowflake 进行 BI 和分析工作负载。以前,组织必须将 Databricks 写入的 Delta Lake 表复制到 Snowflake 的内部格式。使用 UniForm,您可以在 Snowflake 中像读取 Iceberg 一样读取 Delta。首先,通过设置以下表属性在 Delta Lake 表上启用 Iceberg 支持

启用 UniForm 后,当您写入 Delta Lake 表时,Iceberg 元数据将与 DeltaLog 一起自动生成,并与 Parquet 文件 colocated。在 Snowflake 中,您可以使用 Iceberg 目录集成读取 UniForm。
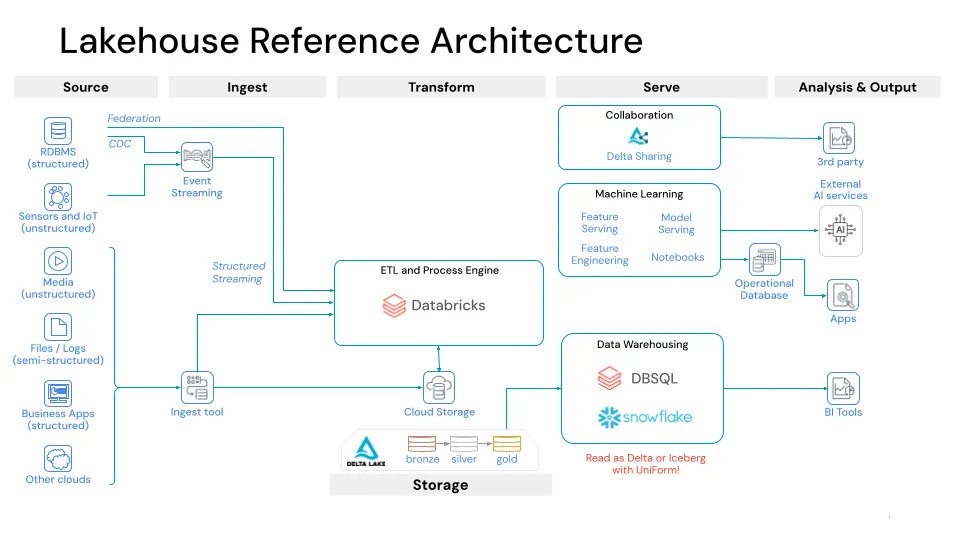
自去年 12 月 Apache 孵化以来,XTable 已经获得了 700 多个 GitHub 星标,并吸引了包括微软、谷歌、Onehouse、Databricks、Snowflake、沃尔玛、Dremio、Adobe 和 Cloudera 在内的众多贡献者、导师和用户。借助 Apache XTable,您可以从任何格式写入,并以全方位方式将其转换为任何其他格式。无论您选择 Delta Lake、Iceberg 还是 Hudi 作为您的主要格式,您都可以在它们之间无缝互操作。XTable 社区的一个常见用例是用户选择 Apache Hudi 使用其独特的记录级索引进行低延迟写入,但仍希望在仅支持 Iceberg 的 Snowflake 中读取。
在底层,Apache XTable 执行轻量级增量元数据转换,其方式与 Delta Lake UniForm 类似。不读取或重写任何实际数据文件,只转换元数据。XTable 提供了一个可移植的运行时,以实现部署和操作的灵活性。有关完整的演练,请参阅文档,但简而言之,它就像这个两步过程一样简单:
- 使用源格式和目标格式以及表的文件的位置设置 config.yaml 文件。
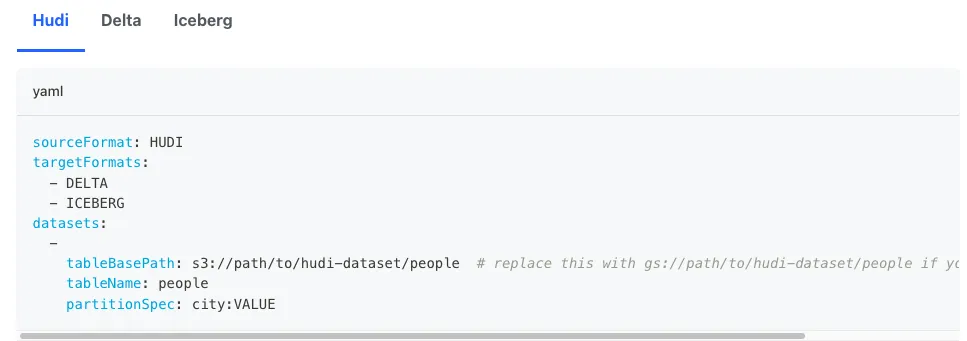
- 执行 JAR 命令以进行转换

您可以执行转换的方法包括:
- 配置 XTable 在每次提交后从 Spark 写入器运行
- 使用 Airflow 等工具安排 XTable 异步按时间间隔运行
- 部署 Lambda 函数或类似服务以按需调用 XTable 转换
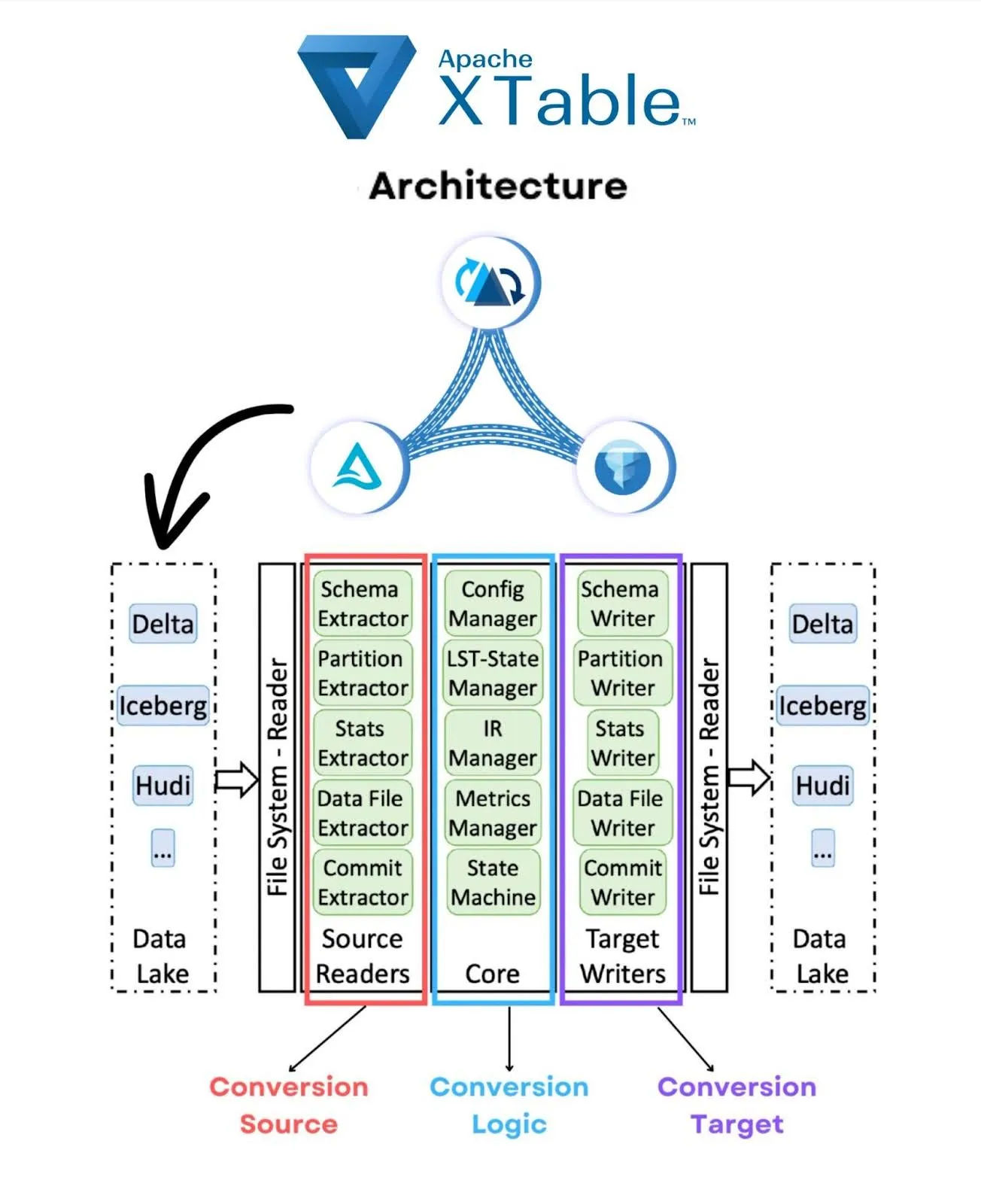
有关 Apache XTable 内部架构的完整详细信息,请阅读 Github readme。下面是一个图表,帮助总结核心组件:
选择开放,而非存储战争
尽管存在几个相互竞争的开放湖仓项目,但所有项目共同努力支持集体数据社区至关重要。随着越来越多的组织采用湖仓架构,Delta Lake、Apache Hudi 和 Apache Iceberg 社区将继续发展,并吸引具有独特需求和偏好的用户和贡献者。随着组织对使用多种表格式的需求日益增长,构建互操作性桥梁至关重要。这将确保分裂不会减缓整个开发社区的创新。
我们的团队认识到共享代码的力量,并相信我们的项目应该相互支持互操作性。欢迎参与并为 Delta Lake 和 XTable 社区做出贡献
| Apache XTable | Delta Lake | |
| Github | apache/incubator-xtable | delta-io/delta |
| 官网 | xtable.apache.org | delta.io |
| 文档 | XTable | Delta Lake |
| 社区列表 | 开发邮件列表 | Google 群组,Slack |
| 社交媒体 | Linkedin,Twitter | Linkedin,YouTube,Spotify |