Delta Lake - 项目现状 - 第 2 部分
这是由两部分组成的博客系列的第 2 部分
第 I 部分:Delta Lake - 项目现状
第 II 部分:Delta Lake - 项目现状
未来是可互操作的
在我们关于项目现状的第一篇博客中,我们讨论了 Delta Lake 社区令人印象深刻的增长和活跃度,以及我们发布的功能创新,例如液体聚类(Liquid clustering)和删除向量(Deletion Vectors)。在第 2 部分中,我们将深入探讨该格式的一些独特功能,特别是互操作性和性能。
跨引擎、连接器和格式的互操作性
Delta UniForm:轻松实现所有格式之间的互操作性
组织在采用开放式数据湖仓时面临的关键挑战之一是为其数据选择最佳格式。在可用的选项中,Linux Foundation Delta Lake、Apache Iceberg 和Apache Hudi 都是出色的存储格式,它们支持数据民主化和互操作性。这些格式中的任何一种都比将数据放入专有格式要好。然而,选择单一存储格式进行标准化可能是一项艰巨的任务,这可能导致决策疲劳和对不可逆转后果的担忧。但如果你不必只选择一种呢?
2023 年,我们宣布了一项名为Delta Lake Universal Format (UniForm) 的新计划,它提供了一种简单、易于实现、无缝的表格式统一,而无需创建额外的数据副本或数据孤岛。UniForm 利用了 Delta Lake、Iceberg 和 Hudi 都基于Apache Parquet 数据文件这一事实。这些格式之间的主要区别在于元数据——所有三种格式的元数据都服务于相同的目的,并且包含重叠的信息集。在 Delta 表上启用后,UniForm 会自动写入其他格式的元数据(目前仅发布了 Iceberg,但我们的社区正在添加对 Hudi 的支持)。这允许您使用符合 Delta Lake 的引擎和符合 Iceberg 的引擎,而无需手动转换数据或以不同格式维护多个数据副本。
此外,您还可以一次性地将 Iceberg 表零拷贝、就地转换为 Delta 表。
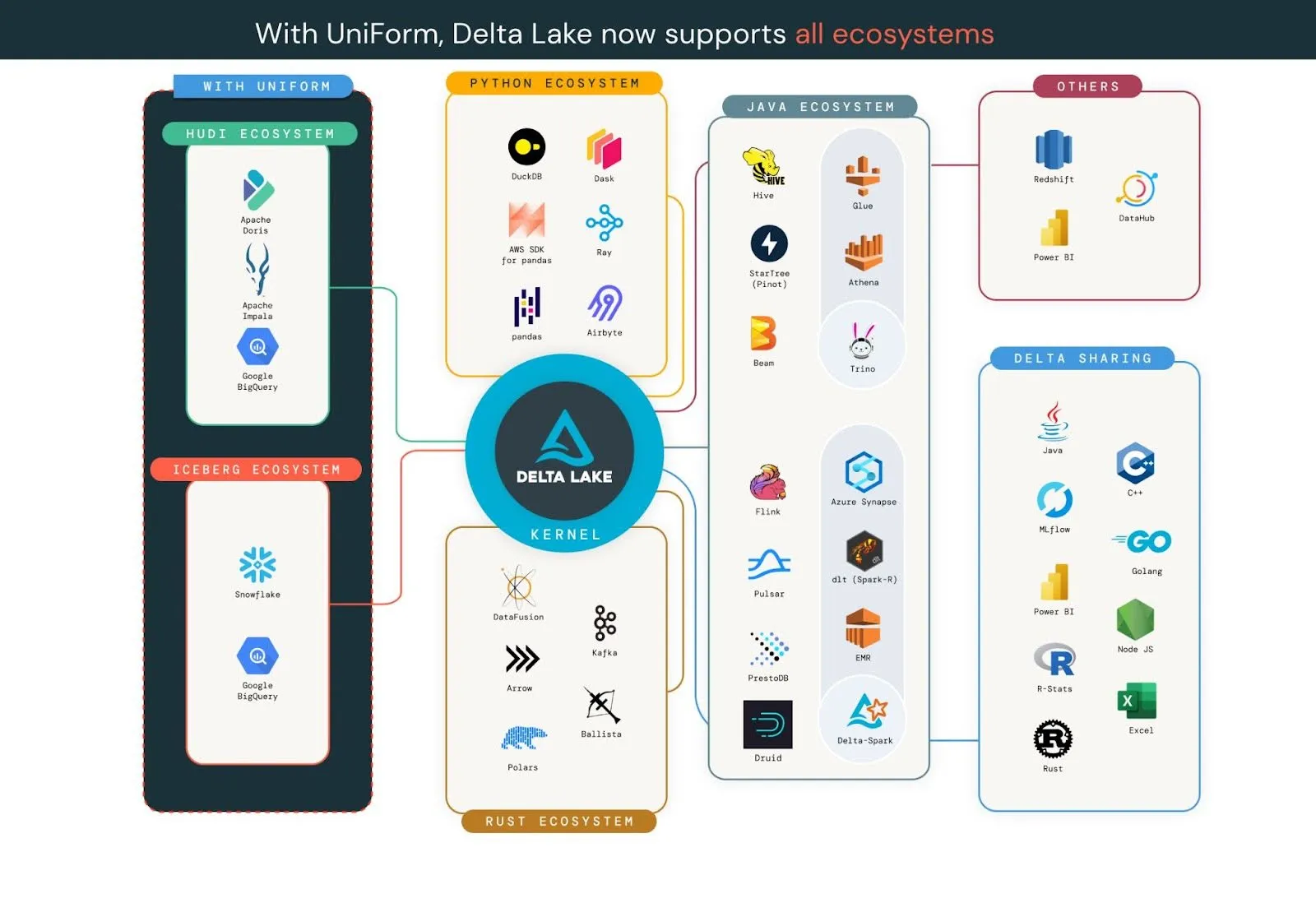
Delta Kernel:简化连接器生态系统
虽然我们正在以越来越快的速度向 Delta 格式添加协议功能,但我们必须确保所有系统都能继续在 Delta 表上运行。Delta 连接器生态系统已经很庞大,我们的目标是继续扩展和增强它们的所有功能,以便尽可能轻松地在数据堆栈的任何地方使用 Delta 表。然而,直到去年,连接器开发人员通常需要了解 Delta 协议的所有细节才能正确实现所有协议功能。这确实使得生态系统难以跟上创新步伐。根据社区反馈,2023 年,我们启动了一项名为Delta Kernel 的新计划。
Delta Kernel 项目的目标是简化构建和维护 Delta Lake 连接器的过程。Delta Kernel 是一个库,它将所有协议细节抽象为简单、稳定的 API。使用 Kernel 库构建的连接器只需更新到最新版本即可获得最新的 Delta 协议支持。Kernel 的两个主要特点是:
- 可插拔架构 - 尽管我们希望向连接器隐藏所有协议级别的细节,但我们不希望阻止任何引擎对其 Delta 连接器进行自定义。Kernel 提供了额外的 API,允许插入自定义组件实现。例如,Kernel 库为读取底层 Parquet 文件提供了开箱即用的“默认”实现。连接器可以选择使用它,或者用自己的引擎原生 Parquet 读取器替换它以获得更好的性能。这在简单性和可定制性之间提供了适当的平衡。
- 多语言支持 - 我们正在用两种语言构建 Delta Kernel:Java(适用于基于 JVM 的引擎)和Rust(适用于用 Rust、C、C++、Python 或任何通过 FFI 与 Rust 互操作的语言构建的引擎)。
2023 年 10 月发布的 Delta 3.0 中的 Java Kernel(Java Kernel 的第一个版本)已被Apache Druid 采用以提供 Delta Lake 读取支持。在Delta 3.1 中,Flink Sink 包含一个实验性的 Kernel 集成,在写入一个包含 700 万个文件的 11 PB 表时,它将 Flink 管道初始化时间缩短了 45 倍(即通过更快地获取表元数据)。随着即将到来的 Delta 3.2,Kernel 将支持时间旅行。欲了解更多信息,请参阅以下内容:
- 深入了解 Kernel 概念
- 2023 年数据 + AI 峰会演讲
- Delta Kernel Java 的用户指南和示例
- 对 Delta Kernel Java 做出贡献的易于上手的小型问题
虽然我们正在努力将所有现有协议功能支持添加到 Delta Kernel 中的全新实现中,但其余连接器仍在继续进行重大增强。以下是一些亮点:
-
Apache Flink - Apache Flink 的 Delta 连接器取得了重大改进。
- Delta Sink 现已投入生产,DoorDash 每周使用它向 Delta 表中摄取数 PB 的数据。
- 已向 Flink 添加了读取支持、SQL 支持和目录支持。
-
Trino - Delta Trino 连接器现在支持删除向量(Deletion Vectors)、列映射(Column Mapping)以及 Delta Lake 主规范中的其他关键功能。它还在所有方面都看到了性能改进。
-
Apache Druid - Apache Druid 29 已使用Delta Kernel添加了对 Delta Lake 的支持。
-
Delta Rust (delta-rs crate / deltalake PyPI) - 这个广受欢迎的项目(截至 2024 年 4 月 3 日,每月 PyPI 下载量超过 200 万次)添加了许多 API 改进:
- 支持常用操作 -
DELETE、UPDATE、MERGE、OPTIMIZE ZORDER、CONVERT TO DELTA - 支持表约束 - 写入将确保不违反表中定义的数据约束
- 支持模式演进
通过这些改进,您可以直接从 Rust 和 Python 应用程序对 Delta 表执行更高级的操作。
- 支持常用操作 -
-
在 GenAI 工具中支持 Delta - deltalake 现在为当前 #GenAI 世界中重要的 Python 库提供了多个新的实验性集成。
- Delta Torch for Pytorch(阅读博客)
- Delta Ray for Ray
- Delta Dask for Dask
-
Delta Sharing - Delta Sharing 通过一种新协议Delta Format Sharing,增加了对安全共享带有删除向量(Deletion Vectors)的表的支持。这项新功能与接收方共享 Delta 日志,使他们能够查询其表,最好使用 Delta Kernel。使用这种方法使共享协议能够适应 Delta 协议的任何未来发展。
-
Delta DotNet - 在 Delta Rust 上编写 .Net 绑定连接器。
-
Delta Go - 由 Rivian 贡献,这是一个完全用 Go 从头开始编写的新连接器。
开箱即用的性能
过去一年,另一个重点领域是开箱即用的性能。如上所述,带有删除向量的合并读取方法可以产生一些令人印象深刻的性能改进。
MERGE、UPDATE 和 DELETE 命令现在都支持删除向量,当您在 Delta 表上启用它时,会产生非常令人印象深刻的结果。
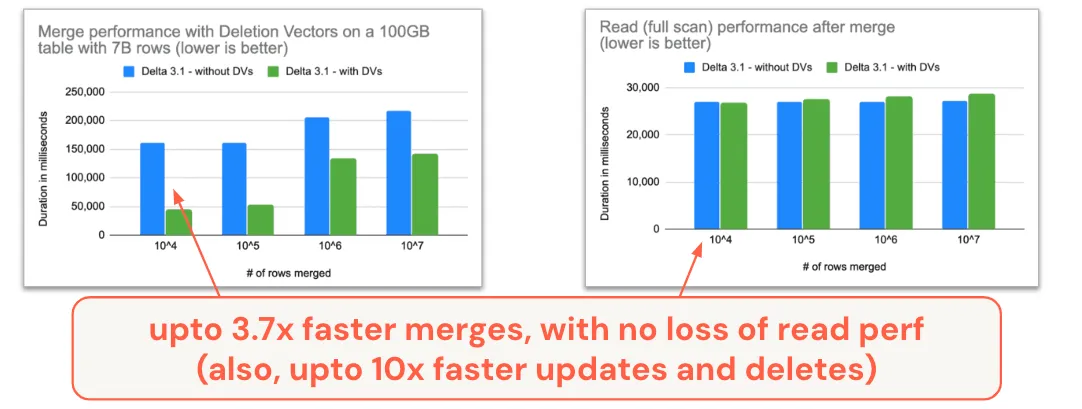
请注意,合并的提速并不会损害读取性能。传统观念和对其他格式的观察至今表明,“合并读取”方法会以牺牲读取速度为代价来加快写入速度,至少与写时复制相比是这样。通过我们的合并读取方法,您无需做出艰难的性能权衡选择;您可以启用删除向量而不会导致任何读取性能退化。
如果由于某种原因,您选择不启用删除向量,您仍然可以享受自Delta 3.0以来快 2 倍的合并速度。
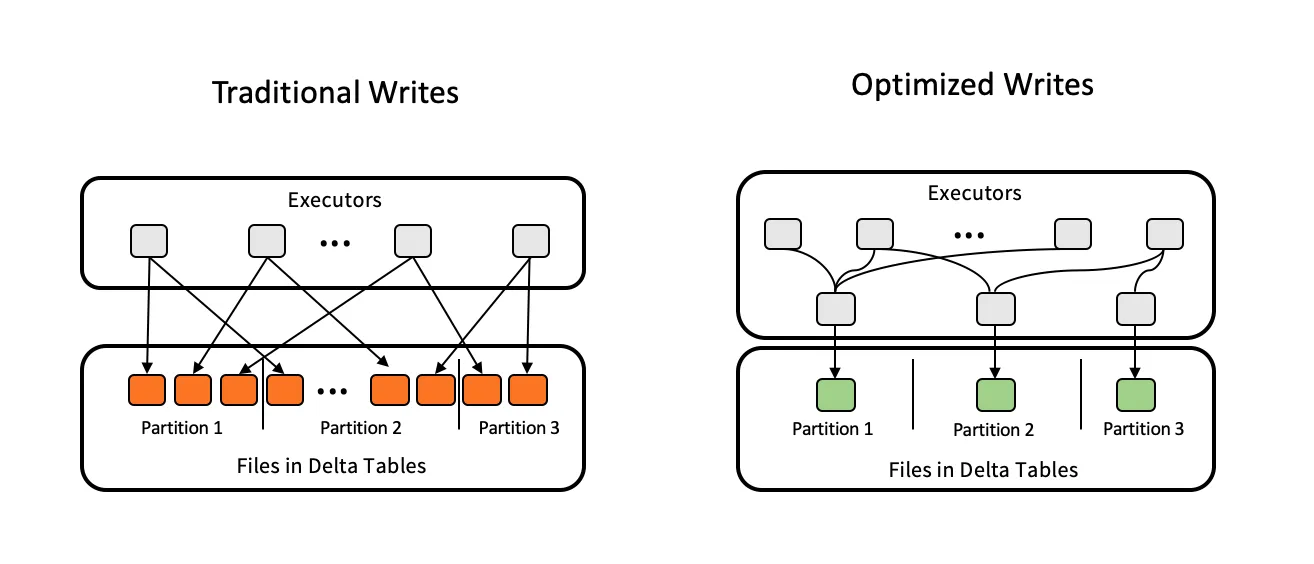
过去一年,开箱即用的读取性能也得到了提升,最近新增了优化写入和自动压缩功能。这两个功能都以略微不同的方式帮助解决了小文件问题。优化写入强制任何分布式 Delta on Spark 写入操作在写入文件之前使用数据混洗重新平衡数据。这个额外的步骤只会为写入操作增加微不足道的时间,但会显著减少写入小文件的机会,并有助于保持读取性能。在仅追加流数据摄取的情况下,每次写入只包含少量数据,优化写入只能做到这一点。这就是自动压缩提供额外性能保护的地方。自动压缩在每次写入后执行“迷你优化”操作,以压缩前一次写入后留下的小文件。这两个功能结合起来,可以提高开箱即用的读取性能。
对于大型表,看似简单的聚合查询(如 MIN 和 MAX)可能非常耗时。通过使用表元数据,这些操作变得更快,减少了对全表扫描的需求,并将性能提高了多达 100 倍。
展望未来:Delta 4.0
Delta Lake 的未来标志着致力于突破数据技术界限,同时确保我们不断壮大的社区易于使用和访问。我们计划进一步增强 Delta Lake 的功能,特别是在实时分析、机器学习集成和跨平台协作等领域。我们的目标是使 Delta Lake 不仅仅是一种存储格式,而是一个全面的数据管理解决方案,能够满足现代数据架构不断演变的需求。预计将看到与 GenAI 工具的更深入集成、更复杂的数据共享机制以及性能方面的进步,这些将重新定义数据处理的基准。
具体而言,我们非常期待的一个重大事件是预计今年发布的 Spark 4.0。这个主要版本将带来新的功能(例如 Spark Connect),这将进一步增强 Delta 生态系统的创新能力。如果您对预告片感兴趣,请查看我们最近的社区聚会,我们在其中讨论了 Delta 4.0 在 Spark 4.0 上的预期。要随时了解 Delta Lake 项目的最新信息,请通过我们的任何论坛加入我们的社区,包括GitHub、Slack、X、LinkedIn、YouTube和Google Groups。
我们很高兴能与我们的社区、合作伙伴和所有数据从业者一起继续这条道路,共同迈向一个数据比以往任何时候都更易于访问、更具可操作性和影响力的未来!