Delta Lake - 项目现状 - 第 1 部分
这是由两部分组成的博客系列文章的第 1 部分
第一部分:Delta Lake - 项目现状
第二部分:Delta Lake - 项目现状
Delta Lake 是一个由 Linux 基金会托管的项目,一直在突飞猛进地发展。为了庆祝该项目的成就,我们将发布一个关于 Delta Lake 的两部分系列文章。Delta Lake 的价值大于其各个部分的简单总和,因此我们没有提供每个发布版本的高光时刻,而是围绕项目核心的共同主题组织了本次回顾。在本系列的第一篇博文中,我们将讨论项目发布的社区、生态系统和功能创新。在第二部分中,我们将深入探讨项目关注的两个关键领域——互操作性和 Delta Lake 的开箱即用性能。
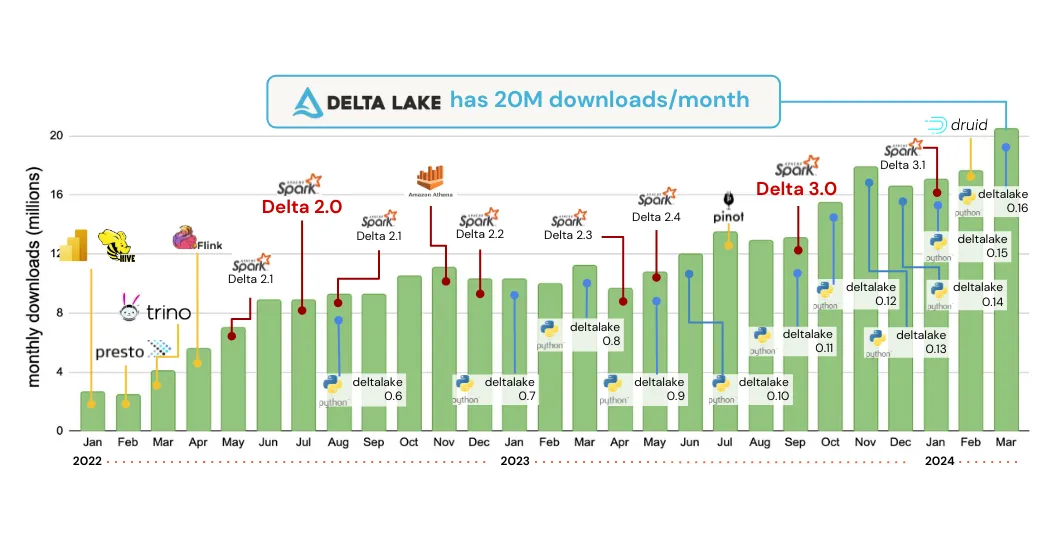
我们为该项目所取得的进展感到自豪,并希望重点介绍项目、社区和生态系统中的一些关键成就。Delta Lake 现在每月下载量已达到 2000 万!
社区
Delta Lake 项目的贡献者投入了大量精力来发展和维护一个健康的社区,并在多个平台上进行互动。与许多单一存储库项目不同,Delta Lake 包含 4 个以上的主流项目和 7 个以上正在孵化的项目,共有 500 多名贡献者在所有这些项目中开发代码。

社交媒体和社区参与
Delta Lake 在领英上的社区关注者已超过 40,000 人,仅在 2023 年就增加了 24,000 多名关注者。我们在领英上的存在已成为分享见解、连接专业人士和促进讨论的中心,并获得了超过 350 万次展示。这表明了我们内容的覆盖范围和影响力,反映了人们对 Lakehouse 架构和 Delta Lake 在塑造这一领域中作用的日益增长的兴趣。
同样,我们的社区 Slack 频道已成为一个活跃的社区,用于点对点支持、知识共享以及促进全球用户和贡献者之间的联系。在过去的 12 个月中,Slack 频道用户已增至 9,300 多人。
现场活动
去年,Delta Lake 为社区成员举办了十二场现场活动,让他们可以连接、学习和分享经验。这些活动包括技术研讨会和行业讨论,每场活动都培养了社区意识和协作精神。全年,Delta Lake 与 Denny Lee 讨论(D3L2)系列直播节目邀请了数据专家分享他们使用 Delta Lake 的旅程。在此处查看该系列节目。
2023 年,Delta Lake 举办了首次社区聚会,社区成员从项目维护者和核心贡献者那里获得了最新的项目更新。虚拟聚会允许社区成员进行开放讨论,并提供了更多参与 Delta Lake 的机会。在 YouTube 上查看社区聚会。每月系列节目 Delta Lake Deep Dives 也已推出,Delta Lake 维护者、贡献者或用户将重点介绍 Delta Lake 的一项功能或集成。在此处观看该系列节目。
行业会议
Delta Lake 参加了多个开源会议
- 北美开源峰会
- 由 Guenia Izquierdo Delgado 和 Sajith Appukuttan 主讲的《Delta Lake 入门》
- 欧洲开源峰会
- 由 Florian Valeye 主讲的《集成数据仓库和数据湖》
- 数据+AI 峰会
印刷品
Delta Lake:权威指南是 Delta Lake 社区中新手和经验丰富的从业者的绝佳资源。O'Reilly 的《Delta Lake:权威指南早期版本》的早期发布版本 4,由 Denny Lee、Prashanth Babu、Tristen Wentling 和 Scott Haines 撰写,可供审阅。完整书籍将于 2024 年晚些时候提供。
其他媒体报道
得益于 Linux 基金会和 Delta Lake 公司项目贡献者的支持,Delta Lake 已在 Business Insider、Yahoo Finance 和 VentureBeat 上亮相。
2024 年社区参与
我们将举办季度虚拟社区聚会,供社区成员了解项目、获取即将到来的路线图更新,并参与项目贡献。要了解更多信息并保持联系,请访问 Delta Lake 社区。
功能创新
我们首先从 Delta Lake 格式(即 Delta 协议)的基础创新开始。
删除向量(DV)
此功能将读时合并 (MOR) 范式引入 Delta。当更新或删除行时,我们不再急于重写包含待删除行的 Parquet 数据文件,而是在读取时简单地标记这些行以忽略。这种基于简单位图/向量(即“删除”向量)的读时过滤可以非常快。启用删除向量的表,删除、更新和合并操作可以快达 10 倍,而不会使后续读取变慢。这打破了其他格式在写入优化“读时合并”和读取优化“写时复制”方法之间进行性能权衡的传统趋势。现在您可以在不牺牲读取性能的情况下获得最快的更新性能。尽管 DV 最早于 2022 年提出,但在 2023 年,我们更新了 DELETE (Delta 2.4)、UPDATE (Delta 3.0) 和 MERGE (Delta 3.1) 操作以使用删除向量。有关更深入的理解,请参阅问题和设计,以及有关如何使用它的文档。
液态聚类
Hive 风格分区通常用于提高数据湖的读取性能,但如果您的列具有高基数、数据倾斜严重或数据变化频繁,则可能导致维护和性能问题。2022 年,Delta Lake 2.0 引入了 `OPTIMIZE ZORDER` 命令,允许通过多维聚类实现更好的数据布局。然而,它需要多次重新聚类数据,导致写入放大增加。2023 年,我们引入了一种名为 Liquid clustering 的新方法,可以解决 Zorder 的局限性。它具有 (i) 采用希尔伯特曲线实现更好的数据布局,比 Z 阶曲线跳过更多数据,(ii) Z-立方体实现增量聚类并减少写入放大,以及 (iii) 可插拔性,允许您插入最适合您数据的数据布局策略。虽然它仍处于预览阶段,但您可以使用 Delta 3.1 进行尝试。
V2 检查点和次要日志压缩
Delta 中的事务日志从一开始就被设计为将元数据视为“大数据”。任何拥有数百万文件(即 100TB 数据)的事务都可以分布式处理。数据需求持续增长,要求表进一步扩展到 PB 级别。事务日志(即表元数据)本身可以超过 10GB。V2 检查点和次要日志压缩是 Delta 3.0 中引入的两个新的日志优化,允许日志增量更新和更快读取,从而使单个表能够可靠地包含 1 亿以上文件(即 100PB 以上数据)。
行追踪
虽然变更数据 Feed (CDF) 提供了查询版本之间行级差异的能力,但它在写入期间需要额外的资源来显式保存行级变更信息。这种较高的开销是 CDF 需要用户显式启用的原因。行跟踪是一项新功能,它为每行数据提供唯一的标识符。这使得每行在更新和从一个文件合并到另一个文件时,都能以非常小的开销被精确跟踪。这允许在不影响写入性能的情况下识别行级变更。
列默认值
与流行的“生成列”功能类似,Delta 3.1 中引入的这项新功能允许在数据写入/更新未显式提供列值时自动插入默认值。这扩展了 Delta 的功能,使其能够支持比以往更多的数据仓库工作负载。
表功能
虽然它本身不是一个面向用户的功能,但它是协议中一个革命性的内部机制,为上述所有创新提供了动力。过去,我们(就像其他格式一样)使用协议版本,每个版本将多个新功能捆绑在一起。为了最大限度地减少读取同一表的各种引擎之间的兼容性问题,无法升级 Delta 表以一次启用一个功能。“表功能”将这种僵化的“版本”方法改进为更灵活的方法——每个表都可以根据需要启用/禁用单个功能(即,像删除向量这样的“功能”),并且引擎可以增量地添加对每个功能的支持。
Delta on Spark 已经支持创建、写入和读取具有上述功能的表,并且对引擎的支持正在通过 Delta Kernel 项目实现(将在本博客文章的第 2 部分进一步讨论)。此外,在过去 12 个月中,用户界面和操作方面也有了重大改进。
-
**有史以来最先进的 MERGE API** - 自 2019 年 Delta 0.3 中引入 MERGE 支持以来,我们一直在突破 MERGE 功能的界限。我们是第一个引入以下支持的开源格式
- 使用 `INSERT *` 和 `UPDATE SET *` 实现自动模式演进(Delta 0.6)
- 无限条件 `WHEN MATCHED` 和 `WHEN NOT MATCHED` 子句(Delta 1.0)
- 复杂类型支持(Delta 0.8 和 Delta 1.1)
-
在过去的一年里,我们一直在改进 API 和性能
- WHEN NOT MATCHED BY SOURCE 子句(Delta 2.3 中的 Scala 和 Delta 2.4 中的 SQL),它允许您在一个 MERGE 操作中执行更复杂的数据更新(而不是多个 UPDATE/DELETE/MERGE 操作)。
- 自动模式演进中任意列的支持(Delta 2.3)
- MERGE 中的幂等性,确保定期作业中的故障得到优雅处理(Delta 2.3)
- 即使没有删除向量,合并速度也快 2 倍(Delta 3.0)
-
Delta Uniform(Delta 3.0 中引入,Delta 3.1 中扩展)- 将 Delta 表读取为 Iceberg 表。更多内容将在本博客文章的第 2 部分中讨论。
-
**表克隆**(Delta 2.3)——这允许您将 Delta、Parquet 或 Iceberg 表快速“浅拷贝”到一个新表中进行实验。也就是说,只有事务日志会被复制到新的表位置;新的日志将引用原始表位置的数据文件。对新表中数据的任何修改都将在新的表位置创建新的数据文件,而原始表将保持不变。
-
**无时区时间戳支持**(Delta 2.4.0)——支持 Spark 3.3 中新增的数据类型。
-
**查询更改数据的 SQL 函数**(Delta 2.3)——一个新 SQL 函数 `tables_changes()`,当表上启用变更数据 Feed 时,该函数返回表中两个版本之间的行级差异。
请参阅所有发行说明以获取更多信息。
下一步是什么?
创新是 Delta Lake 项目的核心,更多更新即将推出,您可以在我们的路线图中看到。Delta Incubator 继续孵化新项目并将其提升为核心 Delta Lake,我们欢迎对生态系统做出进一步贡献。
查看项目现状第 2 部分,了解 Delta Lake 的互操作性和性能方法。