使用 Apache Sedona
作者:Avril Aysha
本文向您展示如何使用 Apache Sedona™。
Apache Sedona™ 是 Apache Spark™ 的一个开源扩展,用于处理地理空间数据。您可以使用 Sedona 使用熟悉的 Spark 数据帧处理地理空间数据。然后,您可以使用 Delta Lake 存储您的地理空间数据。Delta Lake 为您提供出色的数据跳过、可靠的 ACID 事务和更高效的集群存储。这些功能将使您的地理空间查询在 Delta Lake 中运行得更快。
让我们仔细看看 Apache Sedona 是什么,然后深入研究一个使用 Apache Sedona 和 Delta Lake 的实际示例。
什么是 Apache Sedona?
Apache Sedona 是一个开源的分布式计算系统,它扩展了 Apache Spark 以处理大规模地理空间数据。它向 Spark 添加了空间数据类型(如点、多边形和线)、范围查询和空间连接等空间函数以及空间索引。这使得大规模高效处理空间数据变得容易。
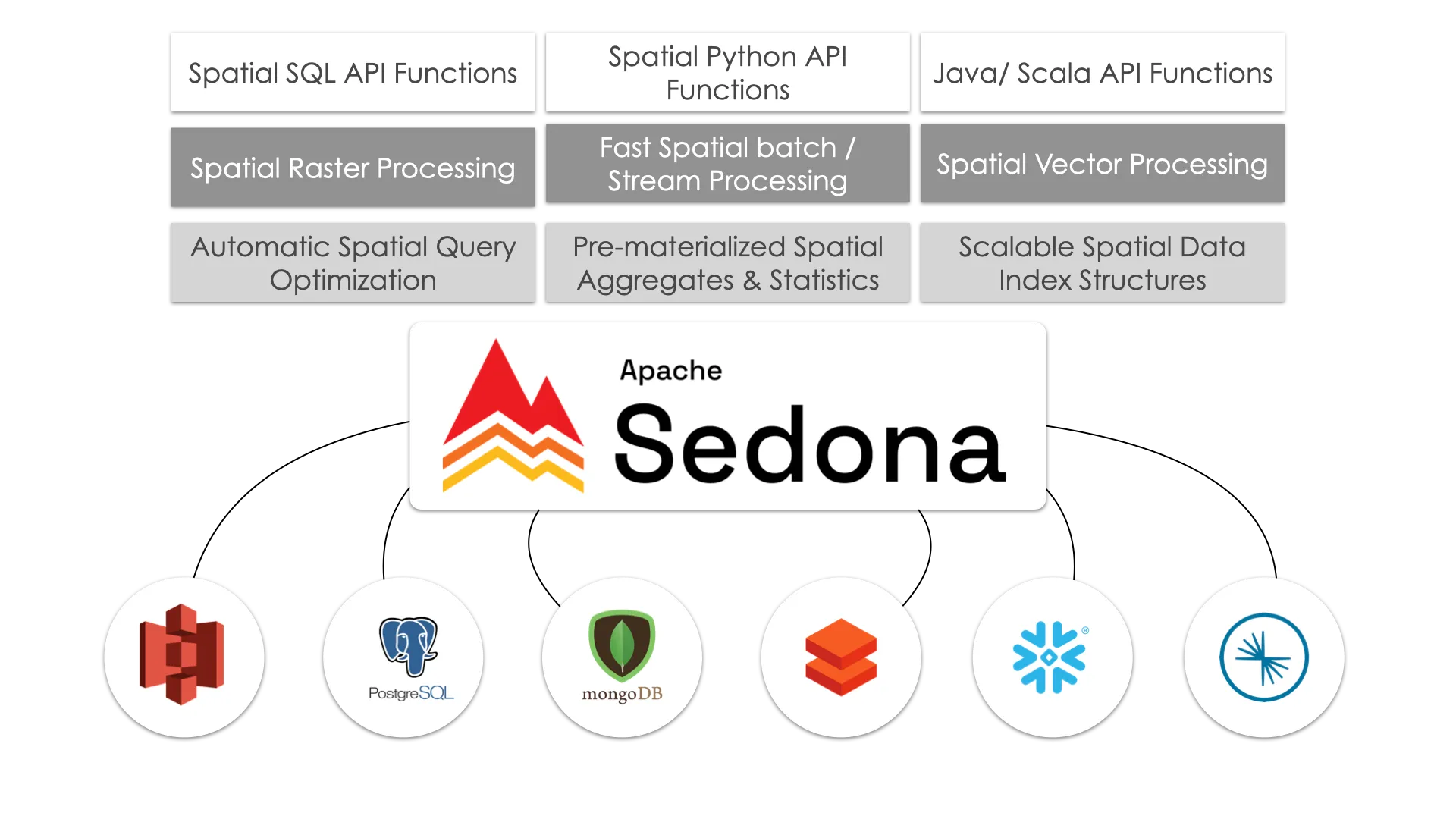
Apache Sedona 最初被称为 GeoSpark,直到 2020 年成为官方 Apache 项目。在底层,Sedona 保留了 GeoSpark 以其闻名的所有核心功能:在 Spark 上进行分布式空间数据处理、空间索引以及对空间数据类型和函数的支持。Sedona 现在还将其空间功能扩展到 Spark 之外的引擎,如 Apache Flink 和 Snowflake。
Apache Sedona 提供 Java、Scala、Python 和 R 的 API。本文将使用 Python 实现。
使用 Apache Sedona 和 Delta Lake
让我们构建一个示例工作流来展示如何使用 Apache Sedona 和 Delta Lake。我们将使用来自 Overture Maps 的数据,这是一个大型开源地理空间数据集。
安装和设置
要安装 Apache Sedona,只需运行
pip install apache-sedona您还需要将两个 JAR 文件添加到您的 Spark 会话中,以使 Sedona 正常工作
org.apache.sedona:sedona-spark-shaded-3.5_2.13:1.6.1org.datasyslab:geotools-wrapper:1.6.0-28.2
您可以手动安装这些 JAR,或者像我们将在下一节中那样将它们添加到您的 Spark 会话中。
以下是一些需要注意的重要事项
- 如果您使用 Spark 版本 >= 3.4,请使用 Spark 对应的 major.minor 版本,例如
sedona-spark-shaded-3.4_2.12:1.6.1。对于 Spark <3.4,您可以使用sedona-spark-shaded-3.0…- 如果您在 IDE 或 Jupyter Notebook 中工作,请使用
sedona-sparkJAR 的unshaded版本:'org.apache.sedona:sedona-spark-3.5_2.12:1.6.1。- 如果您要处理存储在 Amazon S3 中的文件,那么您还需要安装一些 JAR 并设置一些额外的配置。您可以在 S3 上的 Delta Lake 文章中遵循精确的说明来完成此操作。
创建 Sedona 会话
创建 Sedona 会话与创建 Spark 会话非常相似。要使用 Delta Lake,我们必须分两步完成此操作
- 创建具有所有必需 Delta Lake 依赖项的常规 Spark 会话
- 从此 Spark 会话创建 Sedona 会话
首先导入 Spark、Sedona 和 Delta Lake
import pyspark
from delta import *
from sedona.spark import *然后创建一个具有所需配置和用于 Delta Lake、Sedona 和 S3 访问的额外 JAR 的 Spark 会话
conf = (
pyspark.conf.SparkConf()
.set(
"spark.sql.catalog.spark_catalog",
"org.apache.spark.sql.delta.catalog.DeltaCatalog",
)
.set("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.set("spark.sql.shuffle.partitions", "4")
.set("spark.hadoop.fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider")
.set("fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider")
.setMaster("local[*]") # replace the * with your desired number of cores. * for use all.
)
extra_packages = [
'org.apache.sedona:sedona-spark-3.5_2.12:1.6.1',
'org.datasyslab:geotools-wrapper:1.6.0-28.2',
"org.apache.hadoop:hadoop-aws:3.3.4",
"org.apache.hadoop:hadoop-common:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
]
builder = pyspark.sql.SparkSession.builder.appName("GEO_APP").config(conf=conf)
spark = configure_spark_with_delta_pip(
builder, extra_packages=extra_packages
).getOrCreate()接下来,将此 Spark 会话传递给 Sedona 以创建 Sedona 会话。这将使您能够访问空间 DataFrame 和函数。
sedona = SedonaContext.create(spark)很好。您现在已准备好开始大规模处理地理空间数据。
访问地理空间数据
在本教程中,我们将使用 Overture 数据集的 Wherobots 版本。此版本的数据集以 GeoParquet 存储,并通过空间邻近度进行聚类,以实现高效的过滤器下推性能。
让我们指向 Wherobots S3 存储桶
data = (
"s3a://wherobots-examples/data/overturemaps-us-west-2/release/2023-07-26-alpha.0/"
)然后使用此数据创建一个 Sedona 空间数据帧。有关数据集和主题的更多信息,请参阅 Overture 文档。
> df = sedona.read.format("geoparquet").load(data + "theme=places/type=place")
> df.count()
59175720数据已成功加载。此数据集中有超过 5900 万个地点。
您可以使用 printSchema 方法检查元数据
> df.printSchema()
root
|-- id: string (nullable = true)
|-- updatetime: string (nullable = true)
|-- version: integer (nullable = true)
|-- names: map (nullable = true)
| |-- key: string
| |-- value: array (valueContainsNull = true)
| | |-- element: map (containsNull = true)
| | | |-- key: string
| | | |-- value: string (valueContainsNull = true)
|-- categories: struct (nullable = true)
| |-- main: string (nullable = true)
| |-- alternate: array (nullable = true)
| | |-- element: string (containsNull = true)
|-- confidence: double (nullable = true)
|-- websites: array (nullable = true)
| |-- element: string (containsNull = true)
|-- socials: array (nullable = true)
| |-- element: string (containsNull = true)
|-- emails: array (nullable = true)
| |-- element: string (containsNull = true)
|-- phones: array (nullable = true)
| |-- element: string (containsNull = true)
|-- brand: struct (nullable = true)
| |-- names: map (nullable = true)
| | |-- key: string
| | |-- value: array (valueContainsNull = true)
| | | |-- element: map (containsNull = true)
| | | | |-- key: string
| | | | |-- value: string (valueContainsNull = true)
| |-- wikidata: string (nullable = true)
|-- addresses: array (nullable = true)
| |-- element: map (containsNull = true)
| | |-- key: string
| | |-- value: string (valueContainsNull = true)
|-- sources: array (nullable = true)
| |-- element: map (containsNull = true)
| | |-- key: string
| | |-- value: string (valueContainsNull = true)
|-- bbox: struct (nullable = true)
| |-- minx: double (nullable = true)
| |-- maxx: double (nullable = true)
| |-- miny: double (nullable = true)
| |-- maxy: double (nullable = true)
|-- geometry: geometry (nullable = true)
|-- geohash: string (nullable = true)如您所见,Sedona 识别 Geometry 列中的 geometry 数据类型。这意味着我们可以运行空间查询。
让我们试一个。
运行空间查询
让我们运行一个空间查询,以查找加利福尼亚州所有已注册的地点。
我们将定义一个描述加利福尼亚地理空间坐标的边界框多边形,然后运行空间过滤器以查找其中包含的地点。您可以在 此 Github gist 中找到其他美国州的边界。
首先,定义加利福尼亚州边界多边形
spatial_filter = "POLYGON((-124.4009 41.9983,-123.6237 42.0024,-123.1526 42.0126,-122.0073 42.0075,-121.2369 41.9962,-119.9982 41.9983,-120.0037 39.0021,-117.9575 37.5555,-116.3699 36.3594,-114.6368 35.0075,-114.6382 34.9659,-114.6286 34.9107,-114.6382 34.8758,-114.5970 34.8454,-114.5682 34.7890,-114.4968 34.7269,-114.4501 34.6648,-114.4597 34.6581,-114.4322 34.5869,-114.3787 34.5235,-114.3869 34.4601,-114.3361 34.4500,-114.3031 34.4375,-114.2674 34.4024,-114.1864 34.3559,-114.1383 34.3049,-114.1315 34.2561,-114.1651 34.2595,-114.2249 34.2044,-114.2221 34.1914,-114.2908 34.1720,-114.3237 34.1368,-114.3622 34.1186,-114.4089 34.1118,-114.4363 34.0856,-114.4336 34.0276,-114.4652 34.0117,-114.5119 33.9582,-114.5366 33.9308,-114.5091 33.9058,-114.5256 33.8613,-114.5215 33.8248,-114.5050 33.7597,-114.4940 33.7083,-114.5284 33.6832,-114.5242 33.6363,-114.5393 33.5895,-114.5242 33.5528,-114.5586 33.5311,-114.5778 33.5070,-114.6245 33.4418,-114.6506 33.4142,-114.7055 33.4039,-114.6973 33.3546,-114.7302 33.3041,-114.7206 33.2858,-114.6808 33.2754,-114.6698 33.2582,-114.6904 33.2467,-114.6794 33.1720,-114.7083 33.0904,-114.6918 33.0858,-114.6629 33.0328,-114.6451 33.0501,-114.6286 33.0305,-114.5888 33.0282,-114.5750 33.0351,-114.5174 33.0328,-114.4913 32.9718,-114.4775 32.9764,-114.4844 32.9372,-114.4679 32.8427,-114.5091 32.8161,-114.5311 32.7850,-114.5284 32.7573,-114.5641 32.7503,-114.6162 32.7353,-114.6986 32.7480,-114.7220 32.7191,-115.1944 32.6868,-117.3395 32.5121,-117.4823 32.7838,-117.5977 33.0501,-117.6814 33.2341,-118.0591 33.4578,-118.6290 33.5403,-118.7073 33.7928,-119.3706 33.9582,-120.0050 34.1925,-120.7164 34.2561,-120.9128 34.5360,-120.8427 34.9749,-121.1325 35.2131,-121.3220 35.5255,-121.8013 35.9691,-122.1446 36.2808,-122.1721 36.7268,-122.6871 37.2227,-122.8903 37.7783,-123.2378 37.8965,-123.3202 38.3449,-123.8338 38.7423,-123.9793 38.9946,-124.0329 39.3088,-124.0823 39.7642,-124.5314 40.1663,-124.6509 40.4658,-124.3144 41.0110,-124.3419 41.2386,-124.4545 41.7170,-124.4009 41.9983,-124.4009 41.9983))"现在运行空间查询
df_filter = df.filter(
"ST_Contains(ST_GeomFromWKT('" + spatial_filter + "'), geometry) = true"
)最后,让我们计算加利福尼亚州的地点数量
> %%time
> df_filter.count()
CPU times: user 27.1 ms, sys: 14.2 ms, total: 41.3 ms
Wall time: 2min 37s
1168645干得好!Sedona 已高效地处理了整个 5900 万行数据集并执行了空间查询。此示例在 Macbook Pro M1 机器的所有 8 个集群上运行。性能将因集群大小/规格、网络连接等而异。
将地理空间数据存储在 Delta Lake 中
现在您可以将过滤后的数据写入 Delta Lake 表中
df_filter.write.format("delta").save("tmp/places_california")您可以使用 Sedona 在下游读取过滤后的数据
df = sedona.read.format("delta").load("data/places_california")使用 Delta Lake 的好处
与 GeoParquet 等常见地理空间格式相比,Delta Lake 为您提供高级数据跳过和集群功能。液体集群对于地理空间索引特别有用,因为它将空间相关数据存储在一起。这将大大加快您的空间查询,并避免了对复杂且耗时的手动分区策略的需求。
以下是一些出色的 Delta Lake 功能,它们将使您的地理空间工作流程更好
- ACID 事务,实现生产级可靠性
- 更高效的 DML 事务
- 更快的查询优化
- 变更数据捕获 (Change data feed)
- 更高效的元数据处理
- 可以在不重写整个表的情况下进行少量数据更改(例如重命名或删除列)
阅读 GeoParquet 文章以获取更详细的比较。
使用 Delta Lake 和 Apache Sedona
本文解释了如何使用 Apache Sedona 和 Delta Lake 处理大规模地理空间数据。Sedona 为您提供具有空间函数的分布式集群计算,因此您可以使用熟悉的 Spark 数据帧大规模分析空间数据。Delta Lake 为您的空间数据提供快速数据跳过、可靠的 ACID 事务和更好的存储效率。将这些工具结合使用,使大规模处理地理空间数据更轻松、更快速。