S3 上的 Delta Lake
作者:Avril Aysha
本文向您展示如何将 Delta Lake 与 AWS S3 对象存储配合使用。
Delta Lake 是一种出色的存储格式,可实现可靠、快速的数据存储。它提供 ACID 事务、可扩展元数据处理、高性能查询优化、模式强制和时间旅行等功能。凭借这些功能,您可以在数据湖之上构建高性能的湖仓架构。
S3 是在云中存储数据对象的常用位置。S3 上的存储成本低廉,访问效率高,尤其适用于批处理工作负载。许多组织使用 S3 构建数据湖,例如使用 Parquet 文件。
本文将向您展示如何从 S3 读取和写入 Delta 表。我们将介绍使用 Spark 和 Polars 的代码示例。
您将学习
- 为什么 Delta Lake 是 S3 工作负载的绝佳选择
- 如何配置 Spark 会话以使用 Delta Lake 正确访问 S3
- 如何设置 Python 环境以使用 Delta Lake 正确访问 S3
让我们开始吧!🪂
为什么 Delta Lake 对 S3 很有用
云对象存储在列出文件时速度较慢。当您处理大量数据时,这可能会成为一个严重问题。Delta Lake 使您在对象存储中查询数据的效率大大提高。
基于云的文件系统使用平面命名空间而不是分层文件系统。这意味着没有真正的目录。目录通过将前缀附加到对象键来模拟。列表操作要求引擎扫描 *所有* 文件并根据这些前缀进行筛选。
基于云的文件系统还会施加 API 速率限制。这意味着您必须进行许多 API 调用才能列出文件。这两个因素结合在一起会导致在列出许多文件时出现瓶颈。
假设您有一个存储在 S3 数据湖中的表。此表中的数据分散在目录中的许多文件中。要在此表上运行查询,您的引擎首先需要列出所有文件,然后筛选出相关文件。在 S3 上,LIST 操作限制为 1000 个对象。如果您的表有数百万个文件,这将导致高延迟和较慢的查询。
Delta Lake 将所有文件路径存储在单独的事务日志中。这样可以避免昂贵的文件列表操作。您的引擎只需执行一个操作即可获取查询所需的所有相关文件路径。这效率更高。
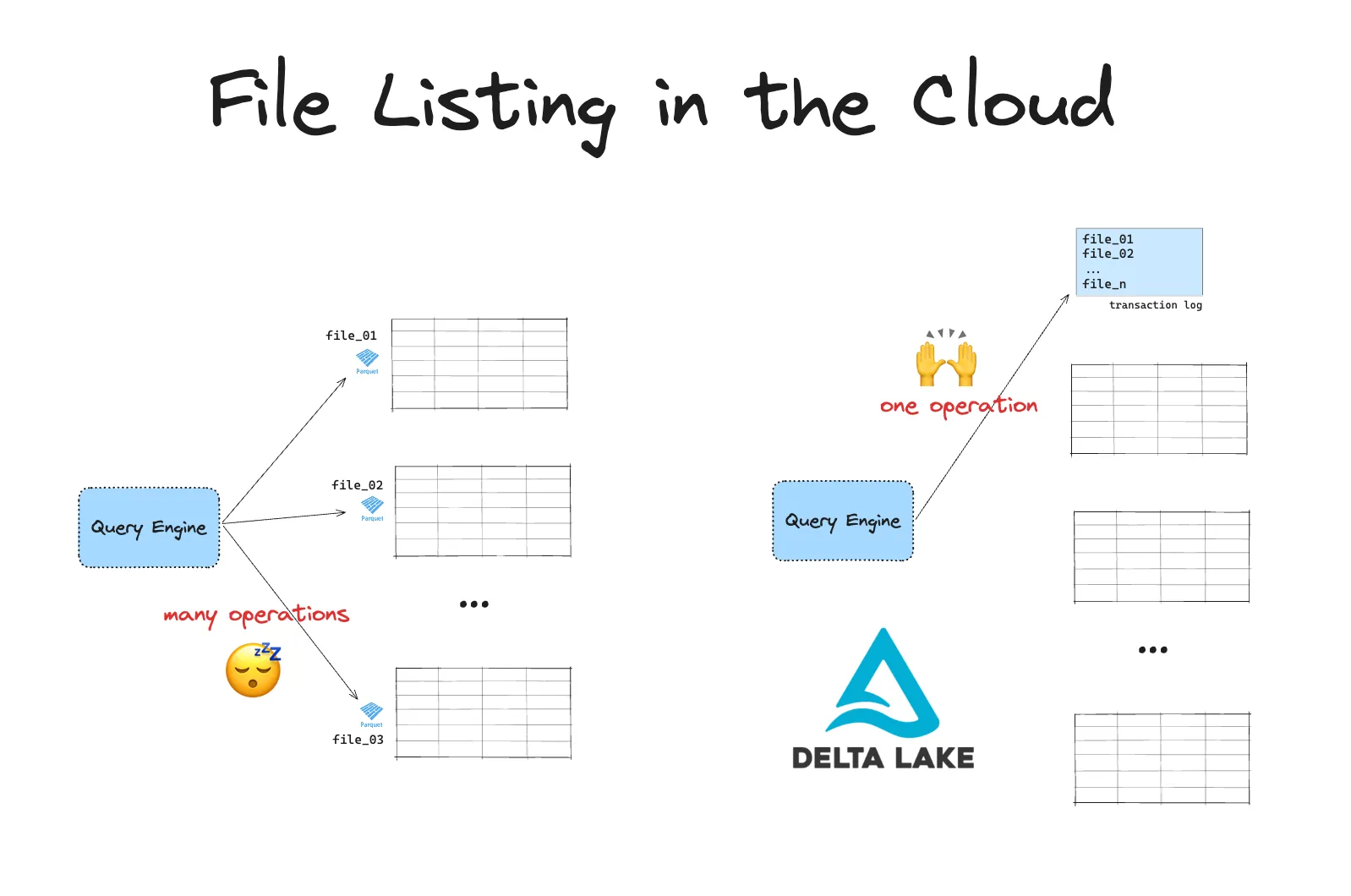
与 S3 上的数据湖相比,Delta Lake 还有许多其他优点。您可以在 Delta Lake 与数据湖 博客中阅读有关它们的更多信息。
如何在 S3 上使用 Delta Lake
许多查询引擎支持在 S3 上读写 Delta Lake。
例如,您可以使用 Spark 读取 Delta Lake 表,如下所示
df = spark.read.format("delta").load(path/to/delta)您可以使用 Spark 写入数据到 Delta Lake 表,如下所示
df.write.format("delta").save(path/to/delta)一些查询引擎需要一些额外的配置步骤才能开始使用 Delta Lake。以下两节将引导您了解如何使用 Spark(使用 delta-spark)和 Python 引擎(使用 python-deltalake)在 S3 上使用 Delta Lake。
让我们来看一个在 S3 上使用 Spark 引擎的 Delta Lake 示例。
S3 上的 Delta Lake 与 Spark
您的 Spark 会话将需要额外配置才能读/写 Delta Lake 表。具体来说,您需要安装依赖 JAR 以引用、连接和验证 AWS S3。
这些依赖项需要仔细手动指定。并非所有版本的依赖项都能协同工作。
换句话说,您不能简单地启动一个基本的 Spark 会话并使用它来读写 Delta 表
import pyspark
from delta import *
builder = (
pyspark.sql.SparkSession.builder.master("local[4]")
.appName("parallel")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config(
"spark.sql.catalog.spark_catalog",
"org.apache.spark.sql.delta.catalog.DeltaCatalog",
)
)
spark = configure_spark_with_delta_pip(builder).getOrCreate()
df = spark.read.format("delta").load("s3a://bucket/delta-table")
这将报错
Py4JJavaError: An error occurred while calling o35.parquet.
: org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme "s3"并产生一个看起来像这样的长堆栈跟踪
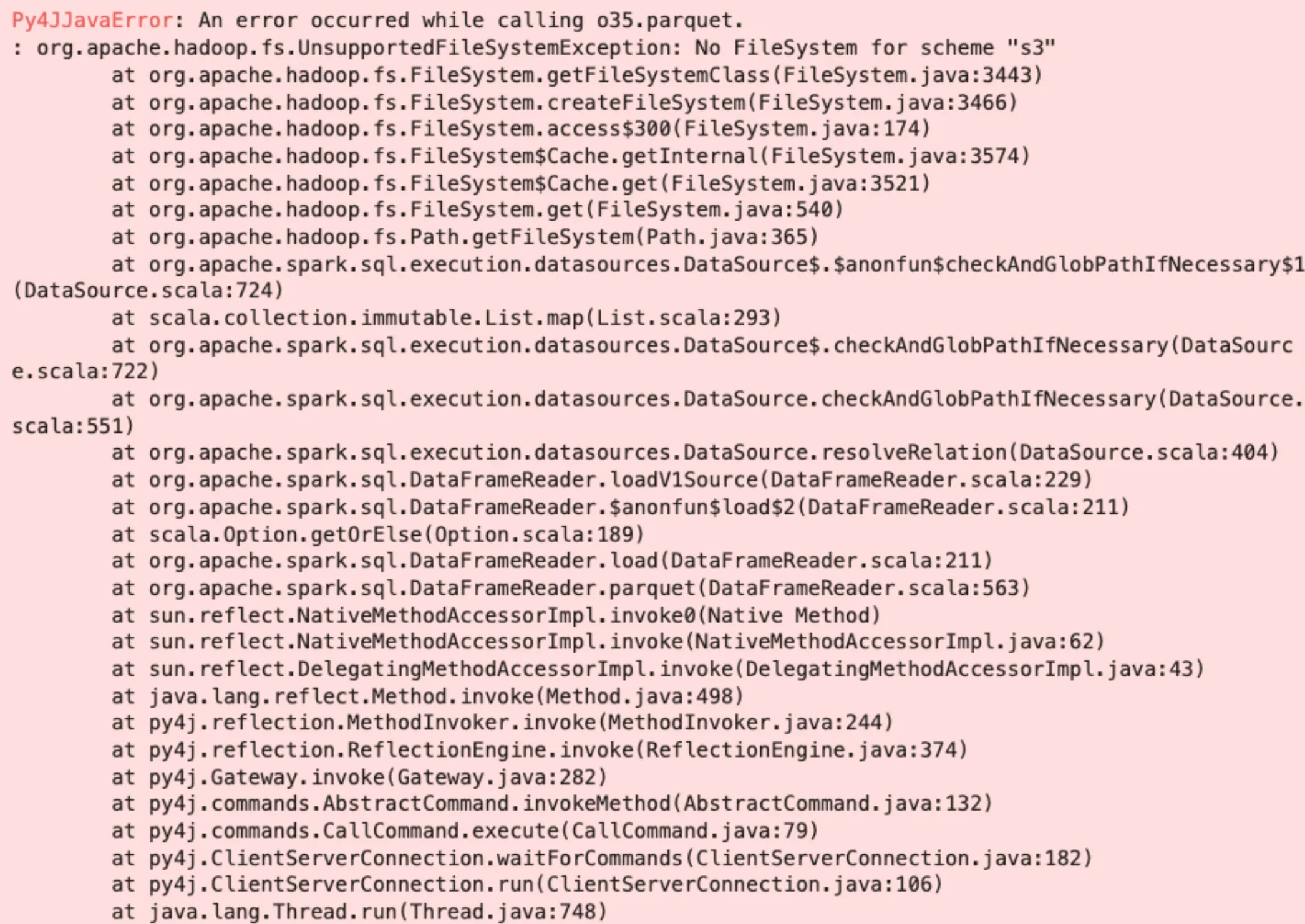
此错误告诉您,您的 Spark 会话不知道如何处理对 S3 文件系统的引用。您需要将以下 JAR 添加到您的 Spark 会话中
- hadoop-aws
- hadoop-common
- aws-java-sdk-bundle
按照以下步骤配置您的 Spark 会话,以读写 Delta 表到 S3
-
安装最新版本的 Spark
-
获取匹配版本的 `hadoop-aws` 和 `hadoop-common` JAR。
一般规则是:Spark x.y.z —> hadoop-aws/common x.y.z。对于 Spark 3.5.0,请使用 hadoop-aws/common 3.3.4(最新版本)
为了确保您获得正确的 hadoop-aws 和 hadoop-common 版本号,您可以在安装 Spark 的任何位置从终端运行以下命令。您需要匹配 `hadoop-client-runtime` 的版本号cd pyspark/jars && ls -l | grep hadoop
…
-rw-rw-r-- 4 avriiil staff 30085504 4 Oct 2023 hadoop-client-runtime-3.3.4.jar
…- 获取匹配版本的 `aws-java-sdk-bundle`,请参阅此处兼容版本。
- 将这 3 个依赖 JAR 添加到您的 Spark 会话构建器中。
您可能习惯于通过使用类似以下内容将 JAR 添加到您的 Spark 配置对象中来完成此操作:\
builder = (
pyspark.sql.SparkSession.builder.master("local[4]")
.appName("s3-write")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config(
"spark.sql.catalog.spark_catalog",
"org.apache.spark.sql.delta.catalog.DeltaCatalog",
)
.config(
"spark.jars.packages",
"org.apache.hadoop:hadoop-aws:3.3.4, org.apache.hadoop:aws-java-sdk-bundle:1.12.262, org.apache.hadoop:hadoop-common:3.3.4",
)
.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
.config("spark.hadoop.fs.s3a.access.key", access_key)
.config("spark.hadoop.fs.s3a.secret.key", secret_key)
) But the `jars.packages` configs will get overridden by the `configure_spark_with_delta_pip` utility function.
Instead, use the extra_packages kwarg option to the `configure_spark_with_delta_pip` function:conf = (
pyspark.conf.SparkConf()
.setAppName("MY_APP")
.set(
"spark.sql.catalog.spark_catalog",
"org.apache.spark.sql.delta.catalog.DeltaCatalog",
)
.set("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.set("spark.hadoop.fs.s3a.access.key", access_key)
.set("spark.hadoop.fs.s3a.secret.key", secret_key)
.set("spark.sql.shuffle.partitions", "4")
.setMaster(
"local[*]"
) # replace the * with your desired number of cores. * for use all.
)
extra_packages = [
"org.apache.hadoop:hadoop-aws:3.3.4",
"org.apache.hadoop:hadoop-common:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
]
builder = pyspark.sql.SparkSession.builder.appName("MyApp").config(conf=conf)
spark = configure_spark_with_delta_pip(
builder, extra_packages=extra_packages
).getOrCreate()- 启动您的 Spark 会话。您可以使用 `spark.sparkContext.getConf().getAll()` 确认已安装正确的 JAR
- 使用一些测试数据创建数据框。
`import pandas as pd`
df = pd.DataFrame({'x': [1, 2, 3]})
df = spark.createDataFrame(df)- 将数据写入 S3 上的 Delta 表。
s3_path = "s3a://avriiil/delta-test-spark"
df.write.format("delta").save(s3_path)请注意,Spark 对 S3 的引用需要前缀 `s3a`。
单集群与多集群支持
默认情况下,Spark 会话将在单集群模式下运行。
在此默认模式下,您可以使用 Delta Lake 从多个集群并行*读取*,但任何并行写入都必须源自单个 Spark 驱动程序,Delta Lake 才能提供事务保证。这是因为 S3 目前不提供互斥。无法确保只有一个写入器能够创建文件,这可能导致数据损坏。
您可以通过显式配置 Delta Lake 使用 LogStore 来启用多集群并发写入支持。在这种情况下,DynamoDB 将用于保证 S3 不提供的互斥。在多集群写入博客文章中阅读更多信息。
接下来,让我们看一个在 S3 上使用 python-deltalake 查询引擎(例如 Polars)的 Delta Lake 示例。
S3 上的 Delta Lake 与 delta-rs
使用 `delta-rs` 实现 Delta Lake 的引擎不需要安装额外的依赖项即可将 Delta 表写入 S3。您确实需要正确配置您的 AWS 访问凭据。
许多 Python 引擎使用 boto3 连接到 AWS。此库支持从本地 `.aws/config` 或 `.aws/creds` 文件自动读取凭据。
例如,如果您在本地运行并在本地 `.aws/config` 或 `.aws/creds` 文件中包含正确的凭据,那么您可以使用 pandas 这样将 Parquet 文件写入 S3
import pandas as pd
df = pd.DataFrame({'x': [1, 2, 3]})
df.to_parquet("s3://avriiil/parquet-test-pandas")`delta-rs` 写入器不使用 `boto3`,因此不支持从您的 `.aws/config` 或 `.aws/creds` 文件中获取凭据。如果您习惯于使用 Polars、pandas 或 Dask 等 Python 引擎的写入器,这可能意味着您的工作流程会发生一些小变化。
您可以通过使用以下方式显式传递您的 AWS 凭据
- `storage_options` kwarg
- 环境变量
- 如果使用 EC2 实例,则为 EC2 元数据
- AWS 配置文件
让我们通过 Polars 的一个示例来了解。相同的逻辑适用于其他 Python 引擎,例如 Pandas、Daft、Dask 等。
按照以下步骤在 S3 上使用 Delta Lake 与 Polars
-
安装 Polars 和 deltalake。
例如,使用
pip install polars deltalake -
使用一些测试数据创建数据框。
df = pl.DataFrame({'x': [1, 2, 3]}) -
正确设置您的 `storage_options`。
storage_options = {
"AWS_REGION":<region_name>,
'AWS_ACCESS_KEY_ID': <key_id>,
'AWS_SECRET_ACCESS_KEY': <access_key>,
'AWS_S3_LOCKING_PROVIDER': 'dynamodb',
'DELTA_DYNAMO_TABLE_NAME': 'delta_log',
}-
使用 `storage_options` kwarg 将数据写入 Delta 表。
df.write_delta( "s3://bucket/delta_table", storage_options=storage_options, )
就像 Spark 实现一样,`delta-rs` 使用 DynamoDB 来保证安全的并发写入。如果由于某种原因您不想使用 DynamoDB 作为锁定机制,您可以选择将 `AWS_S3_ALLOW_UNSAFE_RENAME` 变量设置为 `true` 以启用 S3 不安全写入。
S3 上的 Delta Lake:安全的并发写入
当将 Delta 表写入 S3 时,您需要一个锁定提供程序来确保安全的并发写入。这是因为 S3 不保证互斥。
锁定提供程序保证只有一个写入器能够创建相同的文件。这可以防止损坏或冲突的数据。
您可以将 DynamoDB 表用作锁定提供程序,以实现安全的并发写入。
在终端中运行以下代码以创建 DynamoDB 表,该表将充当您的锁定提供程序。
aws dynamodb create-table \
--table-name delta_log \
--attribute-definitions AttributeName=tablePath,AttributeType=S AttributeName=fileName,AttributeType=S \
--key-schema AttributeName=tablePath,KeyType=HASH AttributeName=fileName,KeyType=RANGE \
--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5delta-spark 默认支持来自单个集群的安全并发写入。多集群写入需要额外配置。有关这两种情况的更多详细信息,请参阅上面的“S3 上的 Delta Lake 与 Spark”部分。
delta-rs 支持安全的并发写入。您将需要一个 DynamoDB 表。如果您不想使用 DynamoDB 表,则可以禁用安全的并发写入保证。有关更多详细信息,请参阅“S3 上的 Delta Lake 与 delta-rs”部分。
S3 上的 Delta Lake:所需权限
您需要拥有对存储数据的 S3 存储桶中对象的获取、放置和删除权限。请注意,即使您只是追加到 Delta Lake,您也必须被允许删除对象,因为日志文件夹中存在使用后删除的临时文件。
在 AWS S3 中,您需要以下权限
- s3
- s3
- s3
在 DynamoDB 中,您需要以下权限
- dynamodb
- dynamodb
- dynamodb
- dynamodb
在 S3 上使用 Delta Lake
您可以从 AWS S3 云对象存储中读写 Delta Lake 表。
通过避免昂贵的文件列表操作,将 Delta Lake 与 S3 结合使用是加快云对象查询速度的好方法。
您可以使用许多不同的查询引擎将 Delta Lake 与 S3 结合使用。其中一些引擎需要一些额外的配置才能启动并运行。
无论您选择使用哪种查询引擎,都将受益于 Delta Lake 的核心性能和可靠性功能,例如查询优化、高效的元数据处理和事务保证。