释放 Delta Lake 3.0+ 的强大功能:推出带有 Delta 内核的全新 StarTree 连接器
在快速发展的数据管理领域,紧跟最新进展是保持竞争优势的关键。随着 Delta Lake 的最新更新,我们的许多客户都表达了利用这些新功能的强烈兴趣。为了满足这一需求,我们很高兴推出一款基于 Delta 内核库 构建的全新连接器,它为 StarTree 的托管 Apache Pinot 服务用户提供无缝集成和增强功能。
这项令人兴奋的开发是 StarTree 团队与开源 Delta Lake 社区密切合作的结果。我们的共同目标是提供一个强大而灵活的连接器,以满足客户不断变化的需求。借助此连接器,企业可以有效地构建一个用于数据处理和实时查询的强大分析框架,同时确保数据一致性和可用性。用户可以利用 Apache Pinot 和 Delta Lake 的强大功能,通过实时分析应对动态市场条件并推动创新。此次合作彰显了我们对持续改进和创新的承诺,确保我们的用户能够使用数据管理生态系统中最好的工具。
Delta Lake 3.0+ 中的激动人心的新功能
如果您正在使用 Delta Lake 或考虑尝试使用它,那么自 Delta Lake 3.0 发布以来,最新功能有很多值得期待的地方。以下是一些最酷的新增功能:
- Delta Lake UniForm (3.1):Delta UniForm 使您可以轻松地将 Apache Iceberg 和 Apache Hudi 等不同数据格式与 Delta Lake 一起使用,所有这些都来自相同的 Parquet 数据。它为每个人提供了数据的实时视图,而无需额外的副本或转换。
- Delta 内核 (在 3.2 中更新):Delta 内核通过提供易于使用的 API 简化了 Delta Lake 的使用。开发人员可以使用简单的 API 调用构建连接器,内核会处理所有复杂的细节以为您提供正确的数据。
- 删除向量 (3.2):删除向量是一种处理已删除数据的智能方式。它不是重写整个 Parquet 文件,而是将行标记为删除。这使得删除、更新和合并操作更快、更高效。
- Liquid Clustering (在 3.1 中预览):Liquid Clustering 改进了数据组织方式,以加快查询速度。它允许您更改数据聚类方式,而无需重写所有内容,从而在您的分析需求变化时更容易保持数据布局优化。
但这还不是全部!Delta Lake 3.0 及更高版本还对合并、更新和删除操作进行了大幅性能改进。这些增强功能使数据处理更快、更高效,这对任何使用 Delta Lake 的人来说都是个好消息。
StarTree 连接器目前不支持的一个功能是列映射。在发生架构更改(包括列名更改)的情况下,客户将能够利用 StarTree 中的回填功能重建表以反映正确的架构。
什么是 Delta 内核?
Delta 内核是一组旨在简化 Delta 连接器构建的新库。借助 Delta 内核,开发人员可以从 Delta 表读取和写入,而无需了解复杂的 Delta 协议详细信息。相反,他们可以使用稳定的 API 调用,内核会处理所有特定于协议的逻辑以传递正确的行数据。
在 Delta 内核之前,开发人员必须自己管理日志文件和数据文件,并弄清楚数据是如何随时间变化的。现在,Delta 内核在内部处理所有这些复杂性,从而使构建可靠的 Delta 连接器变得更加容易和快捷。
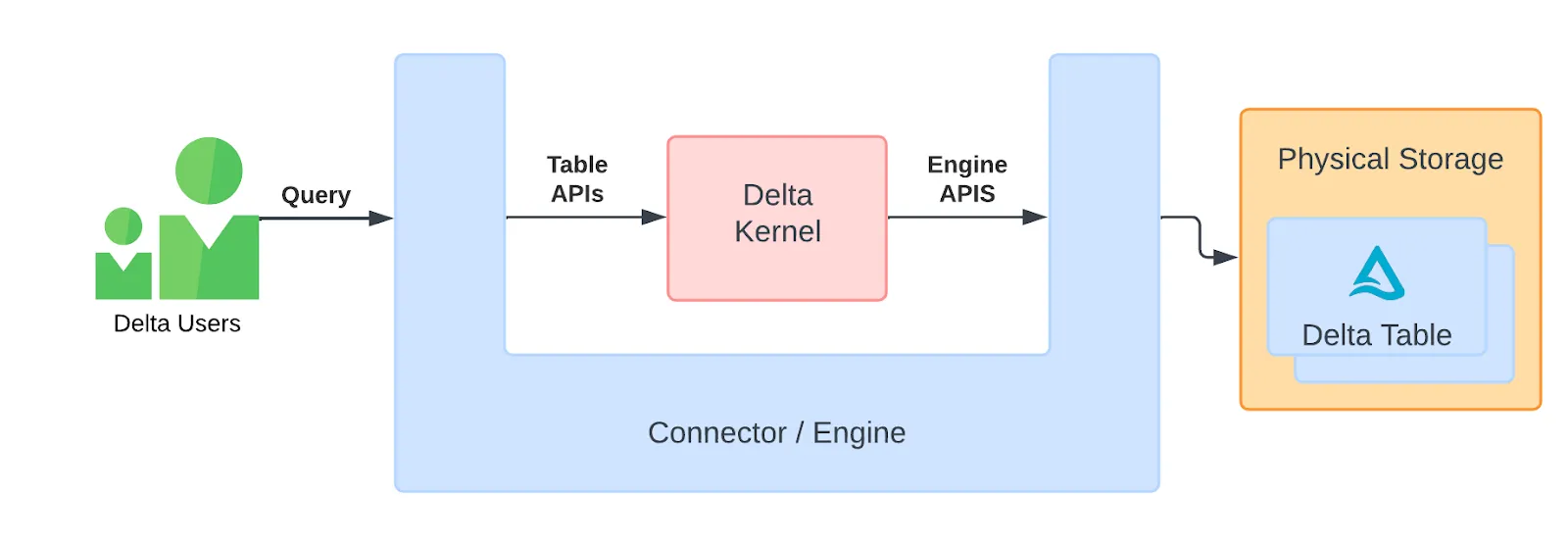
有关 Delta 内核项目起源的详细文章,请查看 什么是 Delta 内核博客。
StarTree:面向用户分析的实时服务层
虽然 Apache Spark™ 在数据处理和临时分析方面表现出色,但它不是面向用户分析用例的理想选择。面向用户的分析需要极低的查询延迟和非常高的每秒查询次数 (QPS),这在使用基于对象存储的数据平台时可能难以实现。
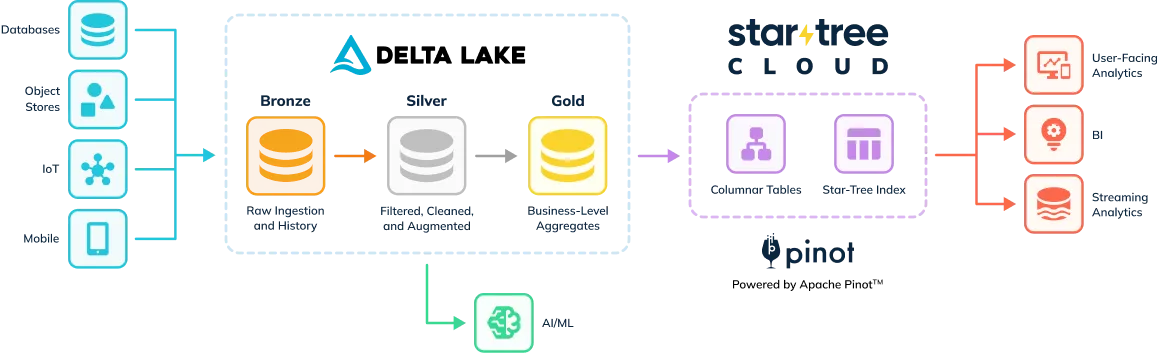
例如,一家金融服务公司可能会收集交易、行为和客户数据。随后,他们将遵循奖章架构创建 Bronze、Silver 和 Gold Delta Lake 表。即使使用 Gold 表,由于对响应能力的担忧以及允许更多用户查询此数据相关的高成本,此数据通常也仅供少数分析师使用。
StarTree 由 Apache Pinot 提供支持,旨在为大规模数据集提供低延迟、高吞吐量的查询功能。它广泛用于需要实时分析和快速数据探索的用例,其中高 QPS 率下的低延迟至关重要。StarTree 使企业能够创建面向用户的分析应用程序,通过利用列式存储、可插拔索引和分布式处理技术(例如使用多阶段查询引擎进行查询时连接),以极低的延迟查询服务数万用户。
为什么将新连接器用于 StarTree 和 Delta Lake?
使用 StarTree 进行面向用户分析的客户可以使用托管连接器轻松地将其 Delta Lake Gold 表集成到 StarTree 中。这种强大的集成确保数据在 Delta Lake 和 StarTree 之间顺畅流动,支持各种数据操作。无论是添加新数据、更新现有数据还是删除数据,这些更改都会自动无缝地反映在 StarTree 中。这种自动同步消除了手动干预的需要,使企业能够在面向用户的分析应用程序中保持实时数据准确性和完整性。
除了无缝集成之外,StarTree 还提供全面的回填解决方案,以便在数据管道发生更改时更新 Apache Pinot 中的表。这包括处理模式演变,这对于随着时间的推移数据结构演变时保持分析的一致性和准确性至关重要。回填解决方案确保对数据管道的任何修改都会自动应用于 Apache Pinot 中的现有表。
此功能在动态数据环境中尤其有价值,其中数据模型经常更改以适应新的业务需求或提高数据质量。借助 StarTree 的回填解决方案,企业可以确保其实时分析保持最新状态并反映最新数据,而无需复杂的手动更新或长时间停机。这使得组织能够保持持续、可靠的分析性能,即使其数据管道不断发展。
用户现在可以放心地依靠 StarTree 中的表来支持面向用户的分析应用程序和需要低延迟、高并发的其他用例。这意味着需要实时数据访问和快速查询响应的应用程序可以使用 StarTree 强大的基础设施表现出色。无论是用于财务分析的交互式仪表板、面向客户的分析门户,还是任何需要以最小延迟处理每秒数千个查询的应用程序,StarTree 都能胜任。
同时,AI/ML 工作负载和临时数据探索任务将继续在 Delta Lake 中存储的原始和处理数据的副本上高效运行。这种关注点分离使每个系统都能在其最擅长的方面表现出色:Delta Lake 用于全面的数据处理和转换,StarTree 用于提供快速、实时的分析。
此架构旨在灵活且无中断,使用户能够轻松地将 StarTree 集成到其现有数据管道中。通过将 StarTree 插入到当前设置中,用户可以增强其数据基础设施,使其具备极低延迟查询和高吞吐量的能力,而无需彻底改造整个系统。这种集成使企业能够保持其现有工作流和数据处理例程,同时显著提高其面向用户应用程序的性能。
结论
将 StarTree 与 Delta Lake 集成,将形成一个强大的分析解决方案,可满足数据处理和实时分析需求。Delta Lake 以其强大的数据处理能力和对临时分析的支持而闻名,使其成为处理大量历史数据的理想选择。另一方面,Apache Pinot 旨在提供低延迟、高吞吐量的查询性能,这对于实时分析应用程序至关重要。
这种无缝集成确保数据保持一致且随时可用,使企业能够利用两个平台的优势。通过 Delta Lake 管理大量数据处理任务,以及 Apache Pinot 处理实时查询,组织可以实现一个全面的分析框架,以解决各种用例。
“Delta 内核项目旨在加速与 Delta Lake 生态系统的集成。我很高兴看到 StarTree 将 Delta 内核用于其实时分析解决方案。”——Tathagata Das,Databricks Delta Lake 技术主管
通过利用 Apache Pinot 和 Delta Lake 的综合功能,企业可以充分发挥其数据的潜力,增强其应对动态市场条件和通过实时分析推动创新的能力。