Delta Kernel:客户型分析的颠覆者
Delta Lake 为数据管理提供了坚实的基础,具备 ACID 合规性、模式演进和事务一致性。它使组织能够创建具有单一事实来源的统一分析平台,从而改善治理并减少运营开销。
然而,由于性能要求严苛,某些工作负载在移植到数据湖环境时面临特别大的挑战。客户型分析就是其中之一,它要求亚秒级的查询响应和高并发性。在本博客中,我们将探讨如何利用 Delta Kernel 和开源查询引擎 StarRocks 快速集成 Delta Lake,从而使直接在开放数据格式上进行客户型分析成为可能。
挑战:与 Delta Lake 集成
Delta Lake 功能强大,但与查询引擎集成却面临巨大挑战。
复杂的协议
Delta Lake 的事务日志和元数据格式错综复杂。查询引擎必须解析 Delta 日志才能正确读取或写入数据,Delta 日志会跟踪更改、模式和分区信息。随着删除向量或列映射等新功能的出现,跟上协议更新变得越来越复杂。
优化性能
高效查询 Delta Lake 不仅仅是读取 Parquet 文件。集成必须优化 I/O 操作,处理元数据缓存,并利用分区剪枝来最小化数据扫描。如果没有这些优化,查询性能可能会显着下降,尤其是在大规模部署时。
连接器碎片化
Delta Lake 的快速创新和删除向量和液态聚类等功能的引入显着提升了性能和灵活性。然而,这种创新速度给连接器带来了挑战。
每个新功能都要求连接器更新其实现,从而导致碎片化。客户越来越难以预测哪些连接器支持哪些功能,从而导致用户体验不一致。这种延迟采用可能会阻碍客户在其生态系统中充分利用 Delta Lake 的最新进展。
Delta Kernel 登场
Delta Kernel 是一个颠覆者。它是一个轻量级库,抽象了与 Delta Lake 交互的复杂性,提供了用于元数据处理、模式读取和事务日志处理的 API。Delta Kernel 提供了稳定的 API,可简化基本操作,例如:
- 元数据处理:无缝访问和解释表模式、分区和协议详细信息。
- 统计信息收集:提取文件级统计信息,使查询优化器能够做出明智的决策以进行高效的查询规划。
- 事务日志处理:重放 Delta 的原子事务日志,以计算表的最新快照,确保一致性和正确性。
StarRocks 如何通过 Delta Kernel 集成 Delta Lake
如果您还不熟悉 StarRocks,以下是您需要了解的内容。StarRocks 采用分布式架构设计,针对在开放数据湖仓上运行面向客户的工作负载进行了优化,其核心组件包括:
-
前端(FE):
- 负责查询解析、计划生成和元数据管理。它充当大脑,协调多个节点上的查询执行。
-
计算节点(CN)
- 处理数据缓存、检索和分布式查询计划的执行。它是提供快速可扩展数据处理的肌肉。
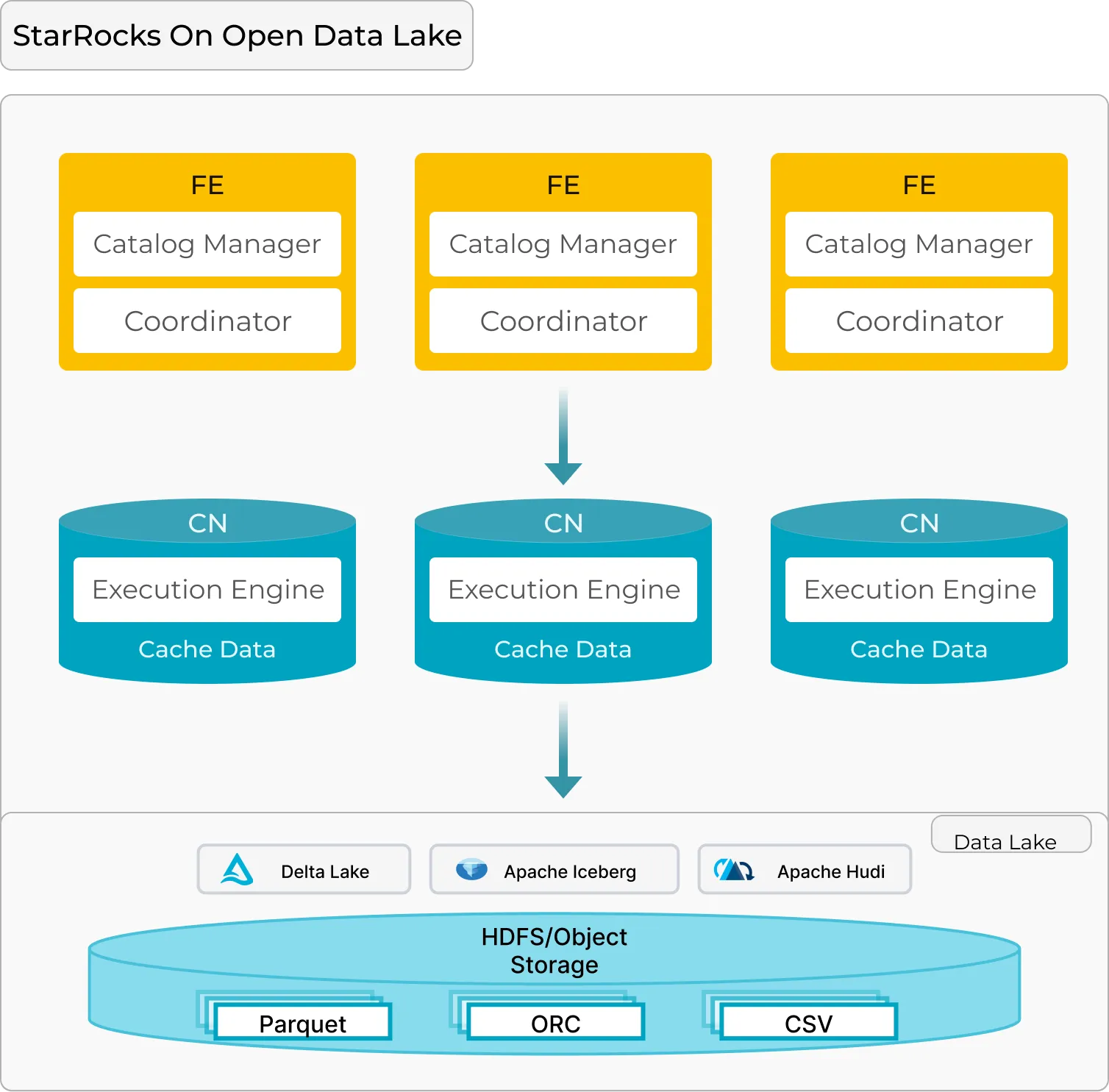
这种 FE + CN MPP 架构简单而有效,使 StarRocks 能够轻松扩展,同时提供高性能,非常适合在大容量数据上进行分析。
Delta Kernel 在 StarRocks FE 中的核心功能
StarRocks 主要通过其前端(FE)与 Delta Lake 集成,其中 Delta Kernel 在处理元数据、优化查询和管理扫描范围方面发挥着关键作用。
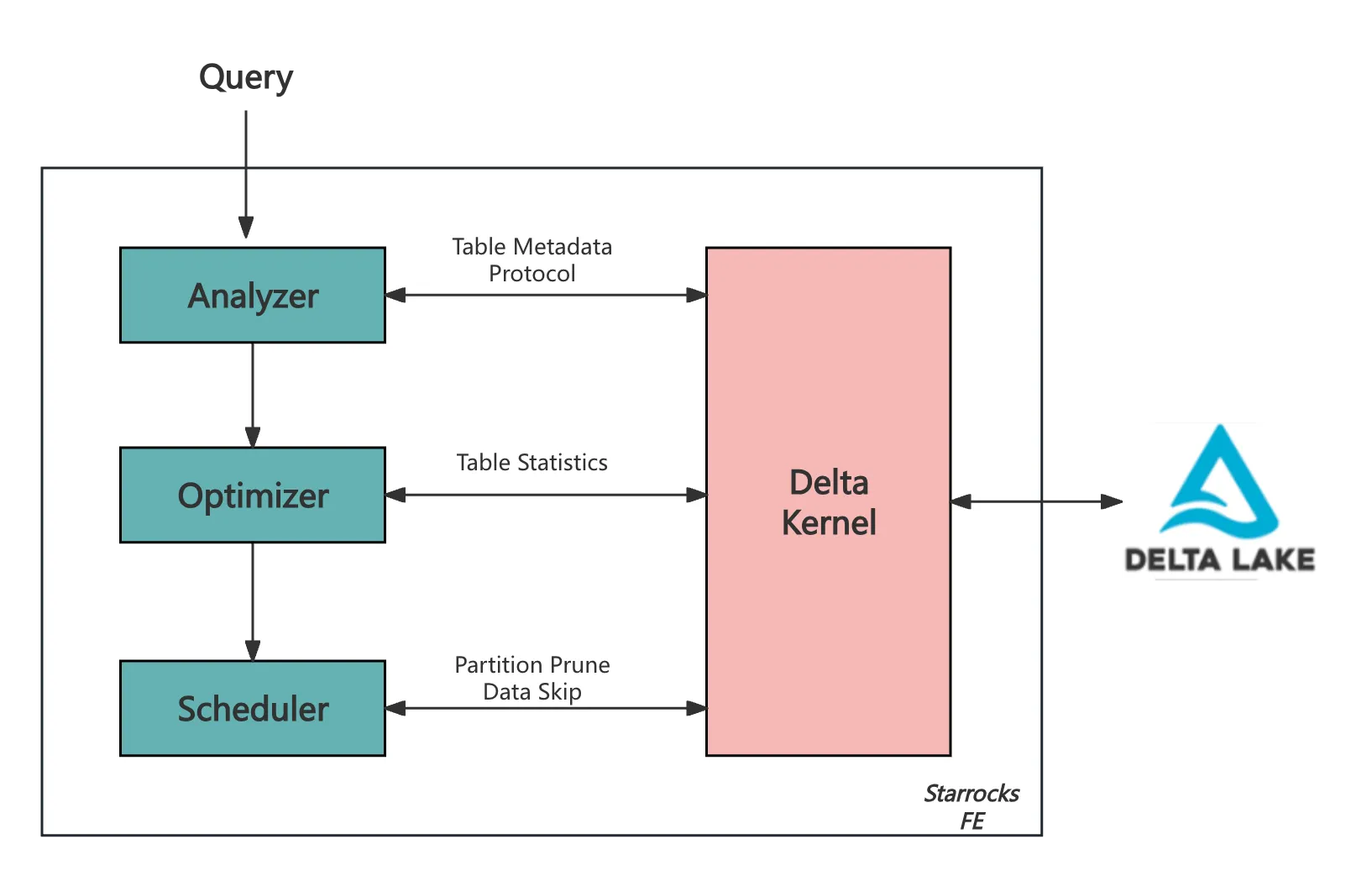
元数据和协议检索
Delta Kernel 检索表的元数据,包括模式、分区列和配置,并确保与 Delta Lake 不断演进的功能集兼容。作为此过程的一部分,它读取 Delta Lake 协议以确定:
minReaderVersion:正确解释表所需的最低读取器版本。readerFeatures:正确数据处理必须支持的特定功能。
用于查询优化的统计信息检索
Delta Kernel 提供文件级统计信息,这有助于 StarRocks 的基于成本的优化器(CBO)选择最有效的查询执行计划。
扫描范围管理
Delta Kernel 是简化 StarRocks FE 中扫描范围生成的关键,它有效地抽象了 Delta Lake 表格式的复杂性。
- 分区剪枝:使用分区谓词排除不必要的分区。
- 数据跳过:利用文件级元数据跳过不相关的数据文件。
- 增量调度:FE 中的调度器使用 Delta Kernel 的迭代器分批获取扫描范围,并增量分发给 CN 节点执行。
这种设计意味着下游计算节点(CN)无需了解表格式或其特定实现。
面向客户的分析优化
Delta Kernel 提供了一组引擎 API 来促进数据访问和支持自定义功能。这些 API 包含以下默认实现:
- 读取 JSON 和 Parquet 文件。
- 评估这些 API 读取的数据上的表达式。
StarRocks 在这些默认实现的基础上进行构建,以更好地服务于面向客户的分析,引入了缓存机制,最大程度地减少了冗余文件读取:
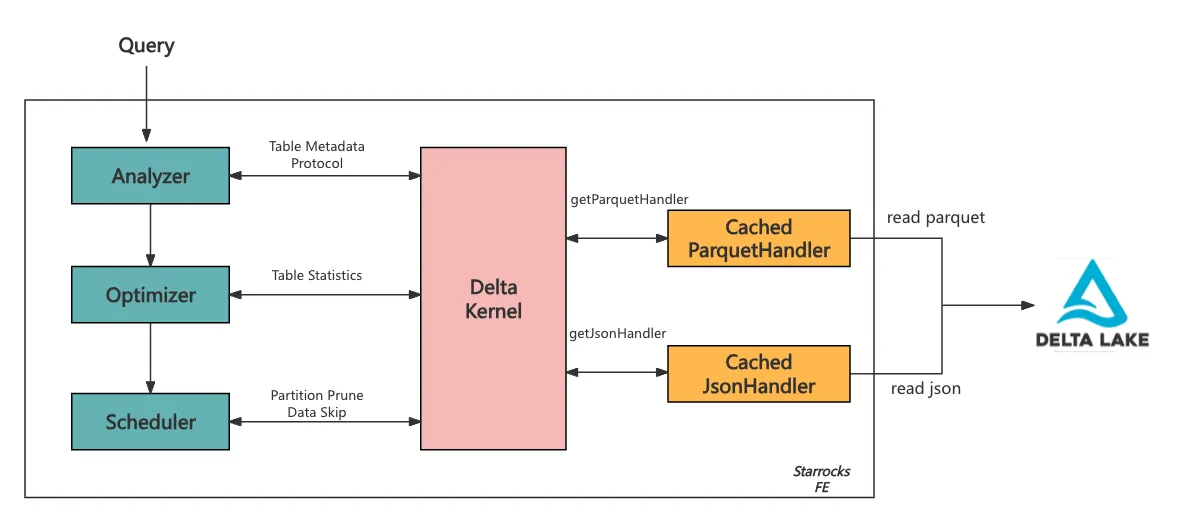
缓存读取的自定义处理程序
- 实现了 CachedParquetHandler 和 CachedJsonHandler,用于在读取 Parquet 或 JSON 文件之前检查缓存。
- 如果文件存在于缓存中,则直接返回其数据,避免了访问和重新处理文件的需要。
- 如果文件不在缓存中,则从 Delta 日志中获取,处理后存储在缓存中以供将来查询使用。
- 缓存采用基于超时设置和 FE 内存限制的逐出策略运行,确保高效利用资源,同时保持频繁访问的数据随时可用。
这些优化通过避免冗余读取 Parquet/JSON 文件并最大程度地减少 FE 中与元数据相关的开销,从而降低查询延迟,确保高并发工作负载的响应速度。
当前能力
目前,StarRocks 的 Delta Lake 连接器支持:
-
广泛的数据类型覆盖:
- 处理 INT、STRING 和 FLOAT 等核心数据类型,并正在开发 MAP 和 STRUCT 等复杂类型。
-
数据跳过:
- 根据 Parquet 文件统计信息和 Delta 事务日志高效跳过不相关的数据,大幅缩短扫描时间。
-
高级表功能:
- 支持事务一致性和分区表。
- 支持删除向量。
立即试用 StarRocks 和 Delta Lake
StarRocks + Delta Lake 为湖仓上的客户型分析提供了强大的组合,具有以下主要优势:
- 高性能查询执行:StarRocks 用 C++ 编写,并进行了 SIMD 优化,持续提供亚秒级查询延迟,并支持高并发性以应对严苛的工作负载。
- 与开放格式无缝集成:使用 Delta Kernel,StarRocks 能够直接在 Delta Lake 上进行快速、可靠的分析,消除了数据摄取并改善了数据治理。
结合 Delta Lake 强大的数据管理功能和 StarRocks 高性能查询引擎,这种架构提供了两全其美的优势——统一的数据治理和卓越的客户型分析性能。
如果您希望最大限度地利用湖仓的价值来处理严苛的工作负载,那么 StarRocks + Delta Lake 是值得考虑的解决方案。立即加入 Delta Lake Slack 和 StarRocks Slack 以了解更多信息。
 Sida Shen
Sida Shen