使用 Delta Lake 扩展图数据处理:一个真实用例的经验教训
Adobe Experience Platform 包含一套分析、社交、广告、媒体优化、目标定位、Web 体验管理、旅程编排和内容管理产品。
Adobe 实时客户数据平台 (CDP) 团队统一收集来自不同接触点的客户数据,以创建单一客户视图。
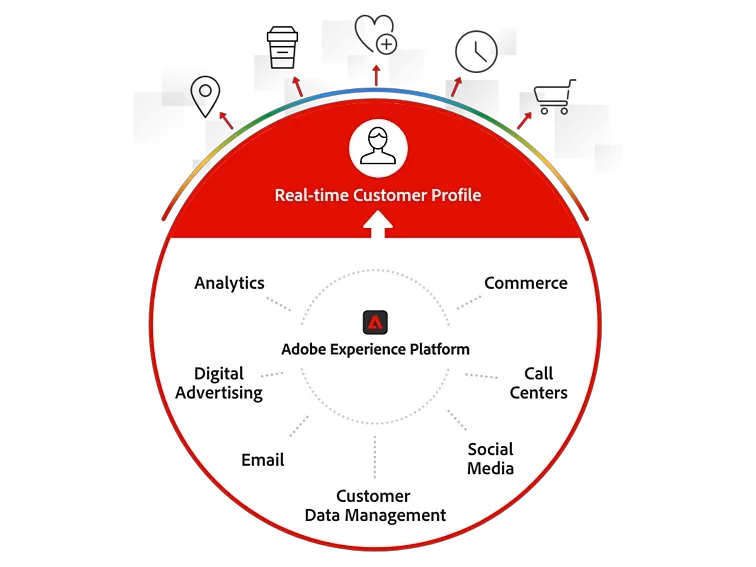
在数据驱动的决策制定世界中,大型 SaaS 公司在高效处理和分析图数据方面面临独特的挑战。作为一家 SaaS 公司,我们亲身经历了处理来自多个来源(每个来源都有自己的模式)的图数据以及对单个记录执行数千次查询的复杂性。为了应对这些挑战,我们着手寻找一个可扩展且多功能的数据存储解决方案。
在这篇博客文章中,我们将分享我们使用 Delta Lake 和 Apache Spark 扩展图数据处理的真实用例的经验和教训。我们将讨论从 NoSQL 数据库迁移到 Delta Lake 的复杂性、我们实施的自定义解决方案以及在此过程中获得的意想不到的性能优势。
挑战和对自定义解决方案的需求
在我们公司,我们管理着大量来自不同来源(包括 JSON、客户网络指标和 Avro)的图数据,每个来源都有其独特的模式。
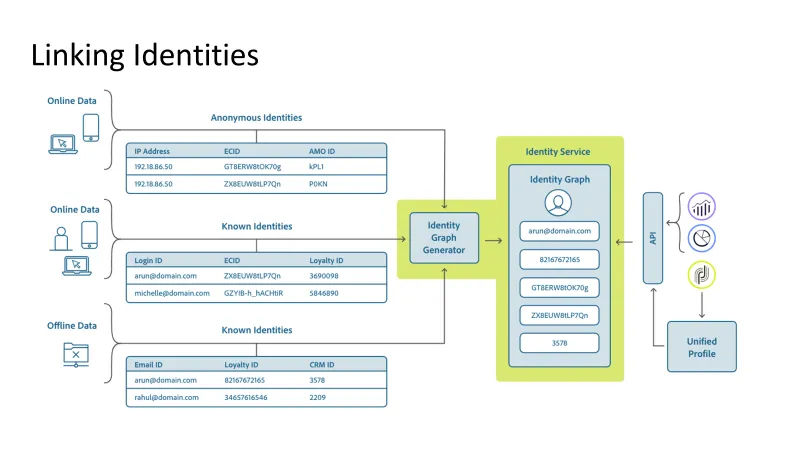
随着数据量的增长,我们现有的 NoSQL 数据库已达到其极限,导致并发写入期间延迟增加和资源争用。此外,我们的用例不仅需要低延迟的点查找,还需要用于复杂查询的高吞吐量批量扫描。我们有两种主要的访问模式:点查找,我们只想返回一行或少量不同的行;批量扫描,我们根据搜索条件查询数据。
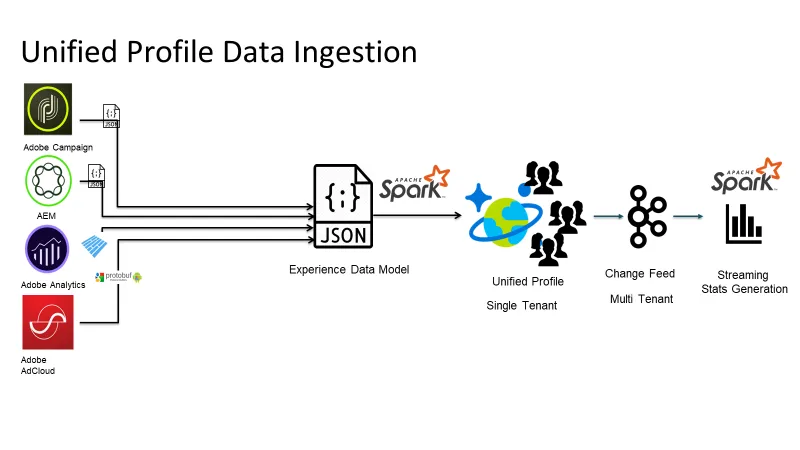
我们面临多重挑战
- 并发冲突:处理来自多个来源的并发写入是首要问题。我们需要确保数据保持一致,并且不会因失败的写入尝试而浪费资源。
- 变更数据捕获 (CDC):从 NoSQL 数据库迁移到 Delta Lake 需要逐步切换,因为我们现有的系统正在为多个客户端提供服务并产生可观的收入。
- 更新频率:当更新过于频繁时,会导致文件存储元数据问题。当你在很短的时间内进行大量写入时,你可能会生成许多小文件。每次写入这个小文件时,随着你不断进行更新,它可能会触发写时复制,这又会触发该文件的完全重写。
- 模式演变:图数据通常带有嵌套和演变的模式。我们需要一个能够处理这些模式更改的解决方案,而无需大量自定义用户定义函数 (UDF)。
- 性能优化:我们的性能要求包括快速数据摄取、高效读取吞吐量以及存储和计算资源的成本效益。
通过锁克服并发性
为了解决并发挑战,我们在 Delta Lake 中实施了两级锁定策略。我们的方法涉及使用星级读写锁和数据集级锁对数据集进行锁定。每个源都被分配了一个特定的锁,在任何写入器执行写入操作之前,它都必须获取相应的锁。这显著改善了延迟和资源利用率,确保只有成功获取所需锁的写入器才能执行写入操作。
自定义变更数据捕获 (CDC)
从 NoSQL 数据库到 Delta Lake 的逐步迁移是一个关键过程。为了实现这一点,我们开发了一个自定义变更数据捕获 (CDC) 机制。我们没有依赖数据库发出的更改事件,而是实现了应用程序级 CDC。每个写入事件的确认都会在相应主题上触发 CDC 消息。CDC 主题馈送到结构化流式应用程序,填充多租户暂存表。此暂存表用作时间缓冲队列,确保将数据高效且可扩展地填充到原始表或 Delta Lake 术语中的“青铜”表。
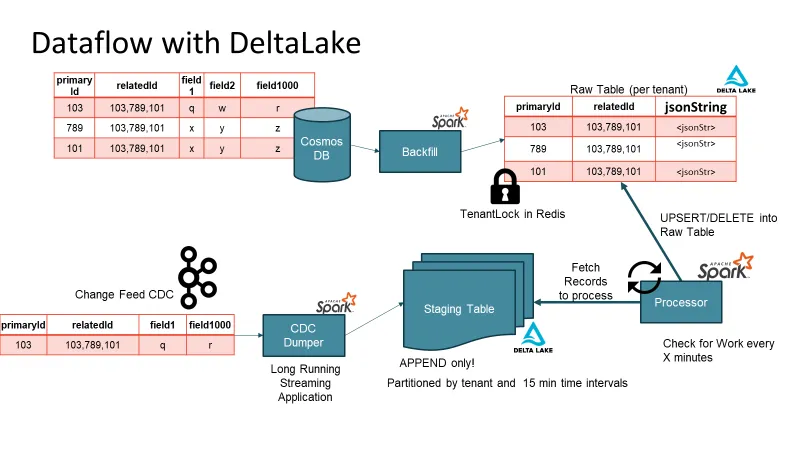
更新频率解决方案:暂存表取胜
通过实施暂存表,你不会读取小块数据。使用暂存表,你还可以解决多次写入的问题。暂存表处于仅追加模式,因此写入时没有冲突。批量写入从暂存表读取更大的数据块,并充当时间感知的消息缓冲区。
模式演变:JSON 字符串表示的力量
我们面临的关键挑战之一是处理不断演变的嵌套模式。尽管 Delta Lake 通过嵌套模式演变支持解决了这个问题,但我们暂时利用 JSON 字符串表示来实现模式灵活性。JSON 字符串使我们能够处理不同的数据模式,而无需为每个租户维护大量 UDF。这种方法使我们能够使用现有的 JSON 补丁库无缝处理更新、插入和复杂的补丁操作。
性能优势和经验教训
在迁移过程中,我们观察到 Delta Lake 带来了意想不到的性能优势。以 JSON 字符串形式存储的数据的压缩率显著提高,大大减少了存储需求。Delta Lake 的读取性能优于以前的 NoSQL 数据库,即使是部分投影 JSON 字符串表示也是如此。此外,Delta Lake 中优化写入的使用在高效缓冲写入和最大限度地减少小文件数量方面至关重要。
利用表属性
Delta Lake 在解决数据处理的几个挑战方面发挥了关键作用。自动伸缩、自动优化和 Z-ordering 等功能极大地促进了我们的成功。我们利用 Delta Lake 的表属性来微调我们的存储,例如禁用某些列上的数据跳过以避免不必要的统计信息构建。
尽管 Delta Lake 没有原生的生命周期 (TTL) 功能,但我们能够通过定义源级 TTL 来实现数据 TTL。我们在分区键级别上实现了高效的读取端软 TTL,这是安全的,因为我们根据配置动态生成 TTL 谓词。硬 TTL 是通过在获取锁后每天执行一次真实删除来实现的,这使我们能够在工作日期间不降低写入速度。
性能指标和规模
我们的真实用例涉及将两拍字节的活跃查询数据从 NoSQL 数据库迁移到 Delta Lake。我们目前为各种租户管理着超过五千个 Delta 表,每个表每天生成数百万条记录。整个系统每天处理近 2500 亿条跨区域消息,每天影响 Delta 表上近 3 万亿次更改。
结论
为大型 SaaS 公司扩展图数据处理需要深思熟虑的方法和强大的数据存储解决方案。Delta Lake 被证明完美符合我们的需求,提供并发控制、高效的 CDC 和模式演变支持。利用 JSON 字符串表示使我们能够轻松处理不断演变的模式,从而带来令人惊讶的性能优势。
随着我们继续微调和优化我们的 Delta Lake 实现,我们相信它将仍然是我们数据处理基础设施的支柱,使我们能够更快、更高效地做出数据驱动的决策。我们希望我们的经验和教训能够激励其他数据工程师和分析师探索 Delta Lake 的功能及其解决大规模复杂数据处理挑战的潜力。