使用 Delta Lake VACUUM 命令删除旧文件
这篇博文解释了如何使用 Delta Lake vacuum 命令从存储中删除标记为删除的文件(又称“墓碑文件”)。对于逻辑删除文件的操作,Delta Lake 不会物理删除存储中的文件。你需要使用 vacuum 命令从存储中物理删除已被标记为删除且超过保留期的文件。
执行 vacuum 的主要好处是节省存储成本。Vacuum 不会加快查询速度,并且可能会限制你时间旅行到较早的 Delta 表版本的能力。你需要权衡每个表的成本/收益,以制定最佳的 vacuum 策略。有些表应经常进行 vacuum。其他表则不应进行 vacuum。
让我们从一个简单的示例开始,然后深入探讨一些边缘情况。然后,我们将研究 vacuum 的成本/收益,以便你权衡取舍并就如何最好地管理 Delta 表做出明智的决定。
如果你想在本地机器上运行这些示例,请参阅此 notebook。
Delta Lake vacuum 示例
让我们从创建 Delta 表开始
df = spark.createDataFrame([("bob", 3), ("sue", 5)]).toDF("first_name", "age")
df.repartition(1).write.format("delta").saveAsTable("some_people")注意:`repartition(1)` 用于输出单个文件,以使演示更清晰。
现在向 Delta 表追加更多数据
df = spark.createDataFrame([("ingrid", 58), ("luisa", 87)]).toDF("first_name", "age")
df.repartition(1).write.format("delta").mode("append").saveAsTable("some_people")这是 Delta 表的当前内容
spark.table("some_people").show()
+----------+---+
|first_name|age|
+----------+---+
| ingrid| 58|
| luisa| 87|
| bob| 3|
| sue| 5|
+----------+---+Delta 表目前由两个文件组成,当读取最新版本的 Delta 表时,这两个文件都将被使用。这两个文件都没有在 Delta 事务日志中标记为删除(又称“墓碑”),因此它们不会被 vacuum 操作删除。墓碑文件已在事务日志中标记为删除,但尚未从磁盘中物理删除。vacuum 命令只删除存储中已设置为墓碑的文件。
这是 Delta 表中当前的文件
some_people
├── _delta_log
│ ├── 00000000000000000000.json
│ └── 00000000000000000001.json
├── part-00000-0e9cf175-b53d-4a1f-b132-8f71eacee991-c000.snappy.parquet
└── part-00000-9ced4666-4b26-4516-95d0-6e27bc2448e7-c000.snappy.parquet让我们用一些新数据覆盖现有的 Delta 表,这将使现有数据成为墓碑。覆盖操作将所有现有数据在事务日志中标记为删除(又称“使所有现有文件成为墓碑”)。
df = spark.createDataFrame([("jordana", 26), ("fred", 25)]).toDF("first_name", "age")
df.repartition(1).write.format("delta").mode("overwrite").saveAsTable("some_people")这是覆盖操作后 Delta 表的内容
spark.table("some_people").show()
+----------+---+
|first_name|age|
+----------+---+
| jordana| 26|
| fred| 25|
+----------+---+如以下图像所示,覆盖操作已添加了一个新文件并使现有文件成为墓碑。
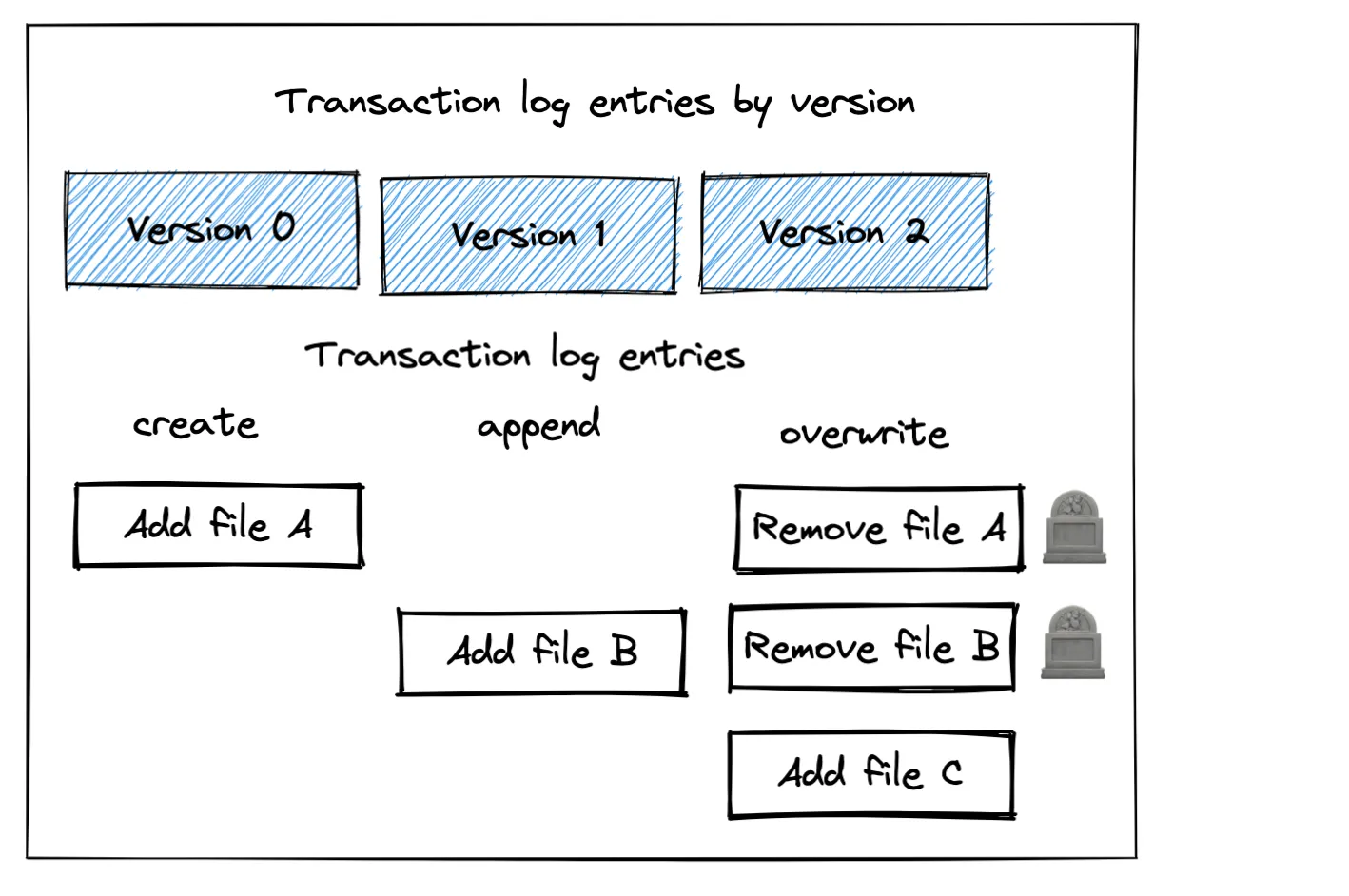
你可以看到所有三个文件仍然在存储中
spark-warehouse/some_people
├── _delta_log
│ ├── 00000000000000000000.json
│ ├── 00000000000000000001.json
│ └── 00000000000000000002.json
├── part-00000-0e9cf175-b53d-4a1f-b132-8f71eacee991-c000.snappy.parquet
├── part-00000-1009797a-564f-4b0c-8035-c45354018f21-c000.snappy.parquet
└── part-00000-9ced4666-4b26-4516-95d0-6e27bc2448e7-c000.snappy.parquet让我们以 `DRY RUN` 模式运行 vacuum 命令,以获取在运行 vacuum 时将从存储中删除的文件列表
spark.sql("VACUUM some_people DRY RUN")
这是返回的消息
在总共 1 个目录中找到 0 个文件和目录,这些文件和目录可以安全删除。
vacuum 命令实际上不会删除任何文件,因为墓碑文件未超过保留期,默认保留期为 7 天。
尝试将保留期设置为零小时,并获取将从存储中删除的文件列表。
spark.sql("VACUUM some_people RETAIN 0 HOURS DRY RUN")
这将返回一个异常,这是可取的,因为使用如此短的保留期进行 vacuum 可能很危险。通常不应将保留期设置为零——我们只是为了演示目的才这样做。Delta Lake 不希望你执行危险操作,除非你明确更新配置。这是你将收到的错误消息
IllegalArgumentException:要求失败:你确定要使用如此低的保留期来清除文件吗?
如果当前有写入器正在写入此表,则你的 Delta 表状态可能会损坏。
如果你确定此表上没有正在执行的操作(例如插入/更新/删除/优化),则可以通过设置以下项来关闭此检查:spark.databricks.delta.retentionDurationCheck.enabled = false
如果你不确定,请使用不小于“168 小时”的值。
以下是如何更新配置,以便你可以将保留期设置为零。
spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled", "false")
配置更新后,我们现在可以运行 vacuum 操作,并将保留期设置为零小时
spark.sql("VACUUM some_people RETAIN 0 HOURS").show(truncate=False)
此命令返回一个 DataFrame,显示已从存储中删除的文件。
- …/part-00000-0e9cf175-b53d-4a1f-b132-8f71eacee991-c000.snappy.parquet
- …//part-00000-9ced4666-4b26-4516-95d0-6e27bc2448e7-c000.snappy.parquet
列出文件以确认它们已从存储中删除
spark-warehouse/some_people
├── _delta_log
│ ├── 00000000000000000000.json
│ ├── 00000000000000000001.json
│ └── 00000000000000000002.json
└── part-00000-1009797a-564f-4b0c-8035-c45354018f21-c000.snappy.parquet这证实了 vacuum 命令已从存储中删除了文件。让我们来看看 vacuum 命令的一个限制,特别是它如何限制时间旅行的能力。
Vacuum 限制了时间旅行的能力
Vacuum 永远不会删除最新 Delta 表版本所依赖的文件,但它可以删除 Delta 表早期版本所依赖的墓碑文件。
检查 Delta 表的最新版本是否仍然可访问,即使在运行 vacuum 命令之后
spark.sql("SELECT * FROM some_people").show()
+----------+---+
|first_name|age|
+----------+---+
| jordana| 26|
| fred| 25|
+----------+---+最新版本仍然可访问,但旧版本无法访问,因为 vacuum 操作删除了 Delta 表版本 0 和 1 所需的文件。
让我们看看当你尝试读取 Delta 表的第 1 版时会发生什么。
spark.sql("SELECT * FROM some_people VERSION AS OF 1").show()
这是错误消息
ERROR Executor: Exception in task 0.0 in stage 237.0 (TID 113646)
java.io.FileNotFoundException:
File: .../some_people/part-00000-0e9cf175-b53d-4a1f-b132-8f71eacee991-c000.snappy.parquet does not exist
It is possible the underlying files have been updated. You can explicitly invalidate the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by recreating the Dataset/DataFrame involved.你无法读取 Delta 表的第一个版本,因为包含该版本数据的 Parquet 文件已从存储中物理删除。
Vacuum 显然会降低你时间旅行的能力。让我们看看尽管有这个缺点,你何时可能想要进行 vacuum。
Delta Lake vacuum 有助于节省存储成本
Delta 表可以保存在各种存储系统,例如 HDFS、AWS S3 或 Azure Blob Storage。这些存储系统通常需要付费。
如果你的 Delta 表包含大量不再需要的墓碑文件,因为你不需要时间旅行到保留期之外,那么你可以简单地对墓碑文件进行 vacuum,从而节省存储成本。
Vacuum 显然并非在所有情况下都可行。你可能需要保留墓碑文件以便进行时间旅行、满足法规要求或用于审计数据保留。Vacuum 是节省存储成本的好方法,但并非总是可取。
Delta Lake vacuum 不是性能优化
一些 Delta Lake 用户错误地认为对 Delta 表进行 vacuum 会帮助查询运行得更快。让我们深入了解 Delta Lake 如何运行查询,以更好地理解为什么它不会帮助查询运行时间。
当你查询 Delta 表时,查询引擎将首先解析事务日志以确定需要读取哪些文件,然后将为查询精选相关文件。让我们以 `SELECT * FROM some_people VERSION AS OF 2` 查询为例。
此查询将解析事务日志并找出需要读取哪些文件才能获取版本 2 中的所有数据。然后查询引擎将读取所需的文件以执行查询。
Delta Lake 只读取它需要的文件。存储中存在墓碑文件不会影响查询性能——墓碑文件 просто被忽略了。
这就是为什么对 Delta 表进行 vacuum 不会提高性能。Vacuum 只能帮助你节省存储成本。
Delta Lake 逻辑操作与物理操作
一些 Delta Lake 操作是逻辑操作,它们在事务日志中进行条目,但不会修改现有数据文件。Delta Lake 为覆盖事务对现有数据文件进行墓碑化就是逻辑操作的一个示例——文件被标记为删除,但它们并未实际删除。
物理操作实际上从存储中添加或删除数据文件。对 Delta 表进行 vacuum 就是物理操作的一个示例,因为文件实际上是从存储中删除的。
理解逻辑操作和物理操作之间的区别有助于你理解 Delta Lake 在底层如何执行不同类型的操作。
其他类型的 Delta Lake 事务会使文件成为墓碑
我们已经看到了 PySpark append 操作不会使文件成为墓碑,而 PySpark overwrite 事务会使 Delta 表中的所有现有文件成为墓碑。
以下是 Delta 表中其他会使文件成为墓碑的操作
- DELETE 操作以从 Delta 表中删除行
- UPDATE 操作以执行 upserts
- MERGE 操作,如本文所述,在一个事务中执行 DELETE 和 UPDATE 操作。
- OPTIMIZE 命令,它会删除小文件并将相同数据添加到更大的文件,如这里所述。
- Z ORDER 将相似数据共置在相同的文件中
结论
本文向你介绍了如何通过对 Delta 表进行 vacuum 来降低存储成本,以及它如何限制你时间旅行的能力。
你的表的最佳 vacuum 策略取决于你的业务需求。
- 假设你需要为了 GDPR 合规性而从表中物理删除行。你将需要执行删除操作,然后对表进行 vacuum,以确保墓碑文件已从存储中物理删除。
- 另一个表可能具有严格的审计要求,你可能需要为了数据保留目的而保留所有墓碑文件。此表不应进行 vacuum。
- 第三个表可能拥有需要在过去 3 个月的数据中进行时间旅行的数据科学家,但不能更长。对于此表,你可以设置 3 个月的保留期,并定期对墓碑文件进行 vacuum。
- 另一个表可能是仅追加的,因此它永远不会有任何墓碑文件。对于此表,vacuum 不会执行任何操作,因为没有墓碑文件需要从存储中物理删除。
你已在本文中了解了 vacuum 命令的工作原理和权衡,以便你可以正确清理 Delta 表中的旧文件。有关 vacuum 命令的更多详细信息以及高级用例的其他注意事项,请参阅 vacuum 文档。