带文件清单的高效 Delta Vacuum
背景
如今,Delta Lake 正在迅速成为一种非常流行的混合数据格式,在各种组织中得到广泛采用。这种普及程度涵盖了使用 Databricks 平台的组织以及利用其开源变体灵活性的组织。在 Grab,我们着手探索 Delta Lake 格式的实际应用,重点关注动态运营和业务分析场景。
其中一个运营案例是处理和分析来自 AWS S3 等云服务的大量日志,旨在进行安全监管和监控。这些日志由提供商通过“尽力而为”的方式交付,我们的 Spark 作业会将其写入按年、月、日、小时分区的 Delta 表。我们每天处理的原始日志数据约为 16TB,解析并保存到 Delta 表后将占用 2TB 存储空间。我们只在 Delta 表中保留 1 个月的数据,超过 1 个月的数据会移动到一个单独的 Parquet 表中,并在那里存档超过 6 个月。
鉴于日志的持续流动性、性质以及日志交付机制,这导致我们的 Delta 表中文件数量激增——这种情况导致 vacuum 操作耗费了大量时间(5-6 小时)。我们的团队选择实施一系列激进的优化;在可能的情况下写入更大的文件,并对相对较旧的分区运行 compaction 作业以创建更大的文件,从而最大限度地减少 Delta 日志中引用的实时文件。尽管进行了这些改进,我们仍只设法将 vacuum 时间缩短到 30-60 分钟。
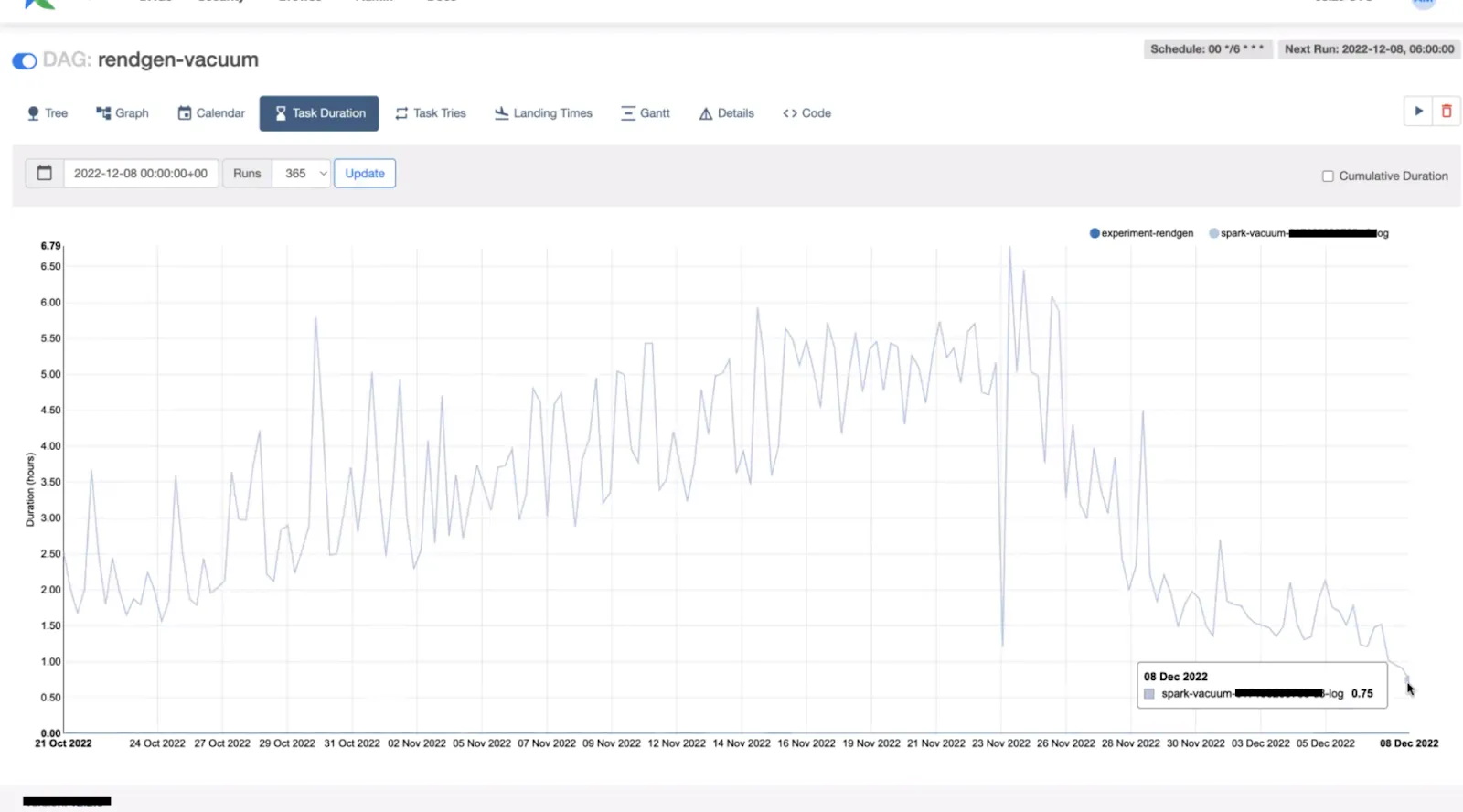
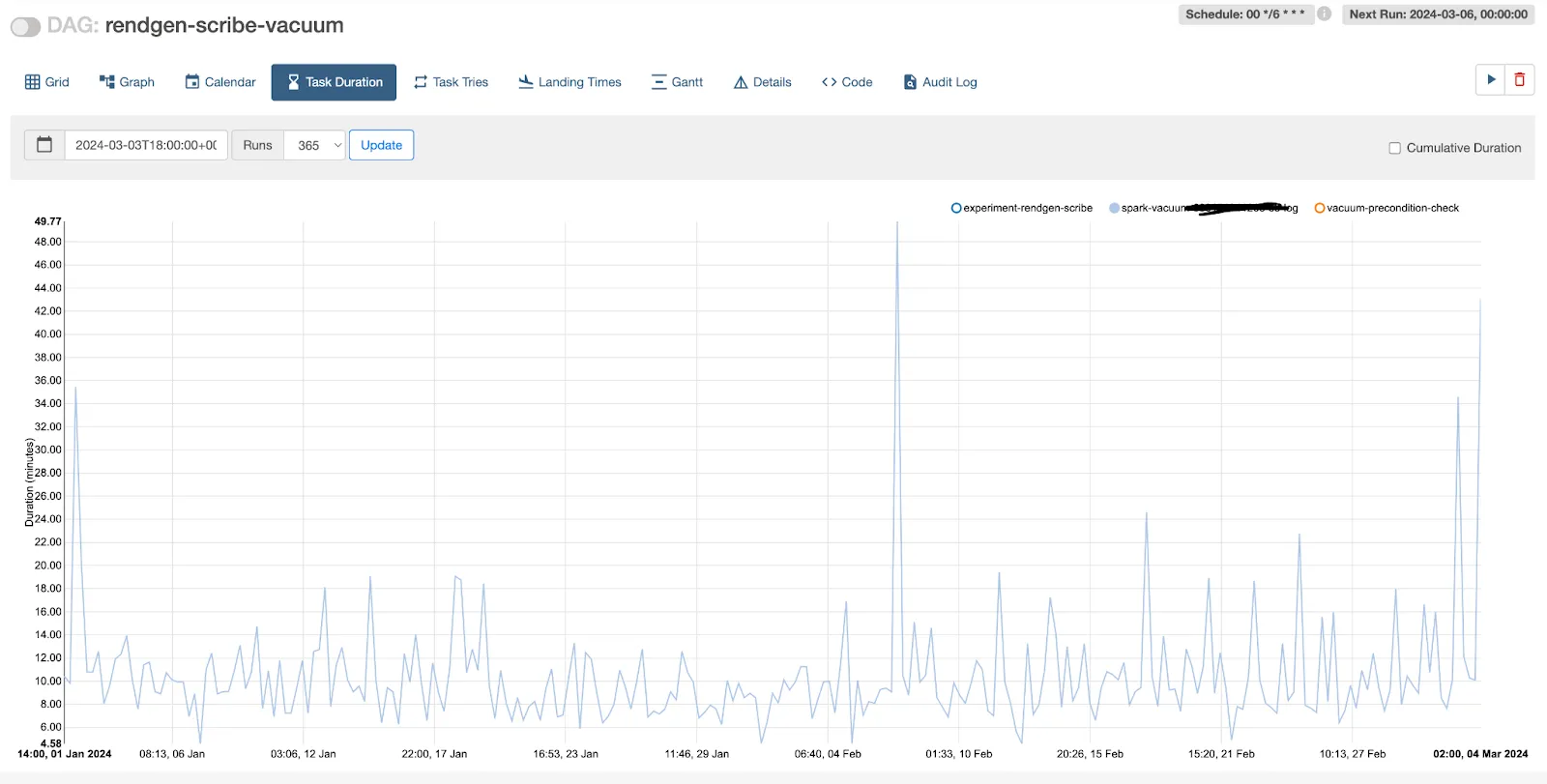
图片:大型表执行 vacuum 操作所需时间的示例
从上图中我们可以看到,当 Delta 表最初创建时,vacuum 时间惊人地增加;后来,当团队部署激进的 compaction、优化和 vacuum 操作时,我们设法将 vacuum 时间降至 30-60 分钟左右。
为什么它更慢?
标准 Delta vacuum 分为三个阶段。第一阶段涉及对 Delta Lake 表下的所有文件执行递归列表,同时消除某些隐藏文件和文件夹。在第二阶段,将 Delta 日志中主动引用的文件集与第一阶段收集的文件列表连接起来。任何在主动引用列表中没有匹配条目的文件都将被标记为删除。最后,在第三阶段,根据是否启用并行删除, identified for deletion 的文件会并行删除,或在 Spark 驱动程序上删除。
主要的瓶颈出现在递归文件列表操作中。此操作的并行性严重依赖于 Delta Lake 表内前两级目录的基数。在我们的实例中,考虑到我们的 Delta Lake 表按年、月、日和小时分区,并且保留期为一个月,我们面临着有效并行性不足的问题。此外,还出现了一个挑战。在负载较重的 S3 存储桶上,进行大量列表 API 调用既昂贵又耗时,从而影响了 vacuum 操作的效率。
随着时间的推移,分区数量会增加,但只有最近的分区会因作业重新运行、更正和延迟到达的事件而发生变化;较旧的分区保持相对不变。然而,当在大型分区表上激活 Vacuum 时,它会启动跨所有分区的 文件系统(或对象存储)列表操作。列表操作所需的时间可能因分区的大小和复杂性而异,从几分钟到几个小时不等。对于大型表,文件系统(或对象存储)扫描占 Vacuum 操作的最大部分。这主要是由于目录结构允许的并行性有限,以及对象存储上的 API 限制。随着表不断增长,扫描的持续时间也会增加,从而使 Vacuum 成为一个巨大的开销,尤其是在处理数百甚至数千个此类 Delta 表时
这种分区方案是数据组织和性能提升的有效策略,尽管它在 Vacuum 中也带来了自身的挑战。运营 PB 级湖仓(包含数十万个对象)的组织需要执行数百万次列表 API 调用。如此广泛的使用将导致与 API 本身以及进行这些调用的计算资源相关的成本。在 Delta Lake 社区内,有几个未解决的问题呼吁提供一种可以提供更具针对性的 vacuum 功能,特别是针对大型用户。
引入基于清单的 vacuum
所有主要的Amazon S3、Azure ADLS 和 Google GCS 等对象存储都支持一项名为清单列表的功能,它提供存储中所有文件/对象的列表以及一些元数据。此清单列表可与新的 vacuum 命令一起使用,以绕过列表操作。这种方法对于在 Lakehouse 中维护大量表而言,具有高性能、可扩展性且经济高效的优势。
这种基于清单的 vacuum 允许用户以 Delta 表或 Spark SQL 查询(具有预定义模式)的形式传递文件清单。此清单数据帧将取代文件列表中的数据帧,从而有效地使 vacuum 成为一个两阶段过程,只需通过与 Delta 日志进行比较来识别未引用的文件并进行实际删除。清单的模式如下:
| 列 | 数据类型 | 备注 |
| 路径 | StringType | 完全限定 URI |
| 长度 | LongType | 大小(以字节为单位) |
| isDir | BooleanType | 是否为目录 |
| modificationTime | LongType | 文件创建/修改时间(毫秒) |
如何使用?
现在用户可以使用可选的 USING INVENTORY 子句将文件清单作为 Delta 表或 Spark SQL 子查询传入。
VACUUM table_name [USING INVENTORY <reservoir-delta-table>] [RETAIN num HOURS] [DRY RUN]
eg:
VACUUM my_schema.my_table
using inventory delta.`s3://my-bucket/path/to/inventory_delta_table` RETAIN 24 HOURS
VACUUM table_name [USING INVENTORY (<reservoir-query>)] [RETAIN num HOURS] [DRY RUN]
eg:
VACUUM my_schema.my_table
using inventory (select 's3://'||bucket||'/'||key as path, length, isDir, modificationTime
from inventory.datalake_report
where bucket = 'my-datalake'
and table = 'my_schema.my_table'
)
RETAIN 24 HOURS我们如何使用它?
我们严重依赖 AWS S3 清单报告来做出关键运营决策,例如收费和存储成本优化。我们既定的管道将 AWS S3 Parquet 清单数据转换为 Delta 表。以下是此转换过程背后的逻辑
case class File(key:String, size: Long, MD5checksum: String)
case class Report(sourceBucket : String, destinationBucket: String,
version:String, creationTimestamp:String, fileFormat:String, fileSchema:String, files: Array[File])
private def getS3InventoryMetaDataFiles: Seq[String] = {
val fs = FileSystem.get(new URI("s3://datalake-metadata/inventory/"), spark.sparkContext.hadoopConfiguration)
buckets.map(bucket => s"s3://datalake-metadata/inventory/${bucket}/${bucket}/**/${date}T01-00Z/manifest.json")
.filter(p=>{
val filePaths = FileUtil.stat2Paths(fs.globStatus(new Path(p)))
if(filePaths.isEmpty) {
logWarning(s"No inventory files found for $p")
}
filePaths.nonEmpty
})
}
private[jobs] def getS3InventoryDataFiles: Seq[String] = {
spark.read
.option("wholetext", true)
.option("ignoreMissingFiles", "true")
.text(getS3InventoryMetaDataFiles: _*)
.flatMap(r => {
val manifest =
new Gson().fromJson(r.getAs[String]("value"), classOf[Report])
manifest.files.map(f =>
s"""s3://${manifest.destinationBucket
.replace("arn:aws:s3:::", "")}/${f.key}""")
})
.collect()
}
val inventoryData = spark.read
.option("ignoreMissingFiles", "true")
.parquet(this.getS3InventoryDataFiles: _*)
.selectExpr(
"bucket",
"key",
"cast(last_modified_date as long)*1000 as modificationTime", //to millis
"storage_class",
"get_table(bucket, key) as table",
"cast(size as long) as length",
s"case when cast(size as long)==0 THEN True when cast(size as long) > 0 THEN False ELSE NULL END as isDir",
"intelligent_tiering_access_tier as intelligent_access_tier",
"encryption_status",
s"'$date' as inventory_date"
)
inventoryData.write
.format("delta")
.mode("overwrite")
.partitionBy("bucket")
.option("partitionOverwriteMode", "dynamic")
.saveAsTable(s"${jobArgs.schema}.${jobArgs.table}")这个管道每天运行并生成清单 Delta 表。然后我们配置了一个日常作业,使用这个 Delta 表作为清单查找机制,对选定的表运行 vacuum。
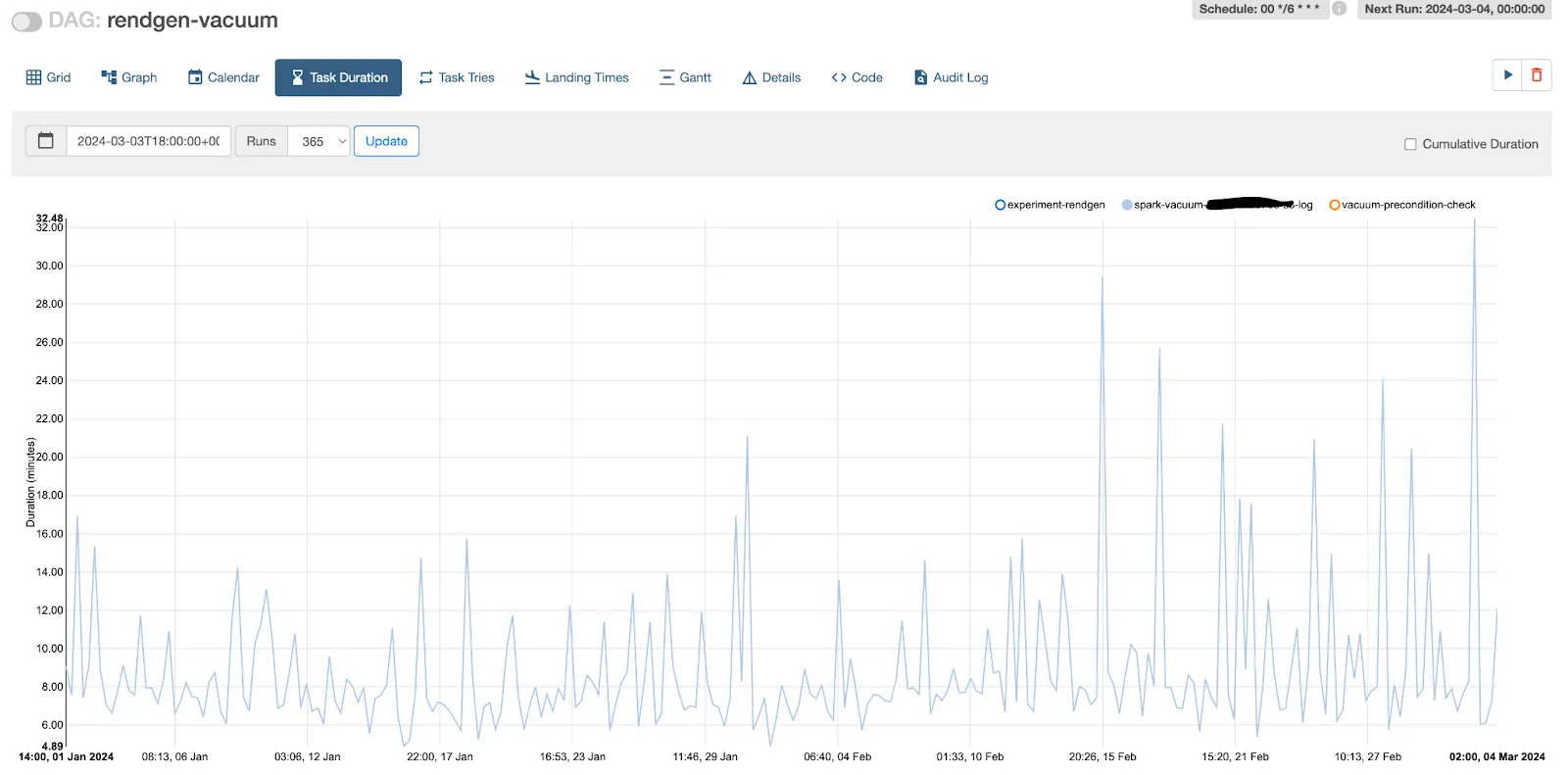
在使用基于清单的 vacuum 后,我们成功将运行时间从 30-60 分钟缩短到不到 5 分钟
优点
- 使用清单获取表结构内所有文件的列表比使用列表 API 调用便宜约 44%(基于 AWS S3 百万对象的定价)
- 由于我们使用的是预计算列表而不是实时列表,Vacuum 执行运行时间大大缩短,这也转化为计算时间的节省。过去我们每 6 小时对每个表运行一次 Vacuum 作业,而使用此功能后,我们能够在一个作业中高效地对多个表运行 Vacuum,每个表的文件删除只需 1-2 分钟。频率也减少到每天一次。
之前
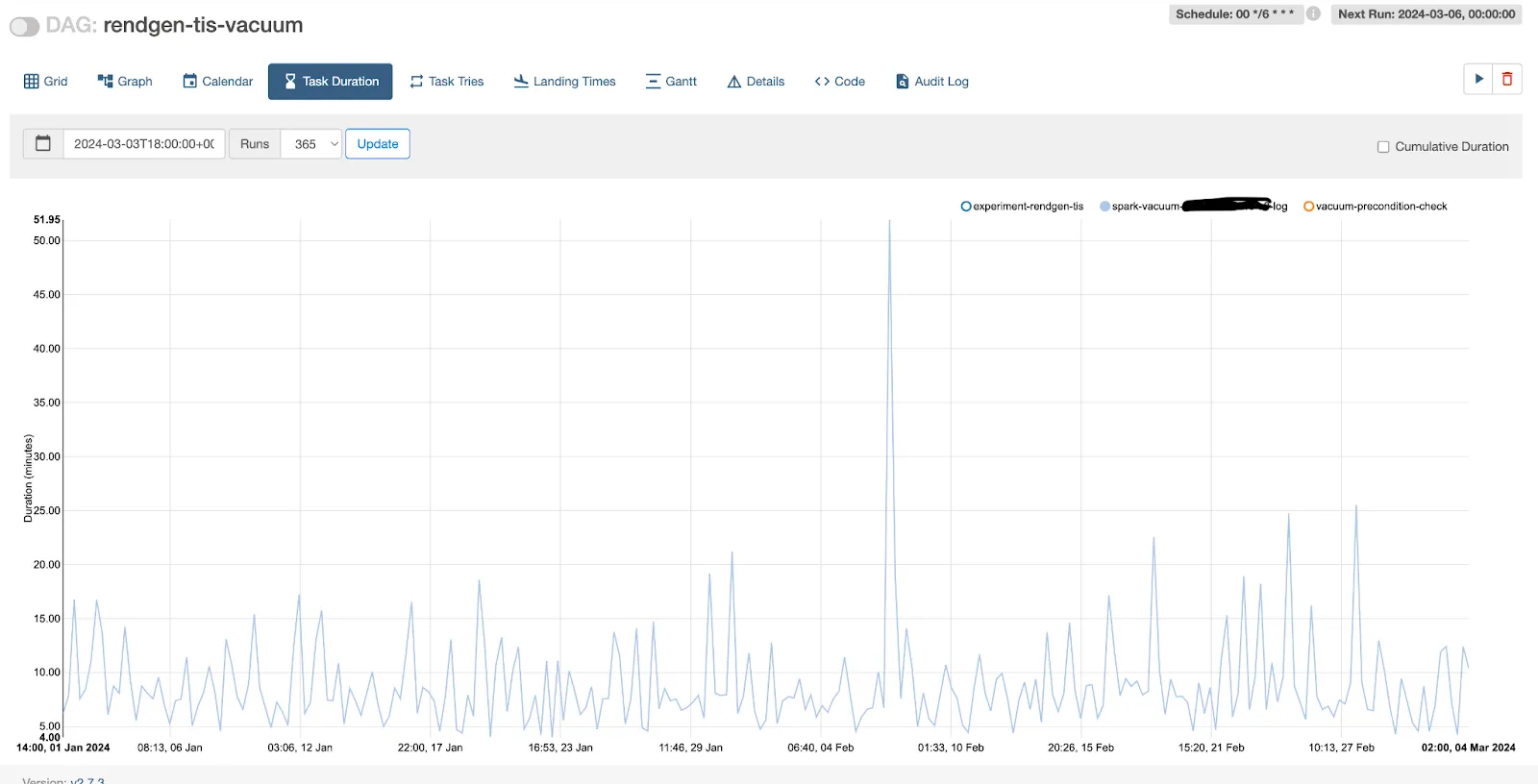
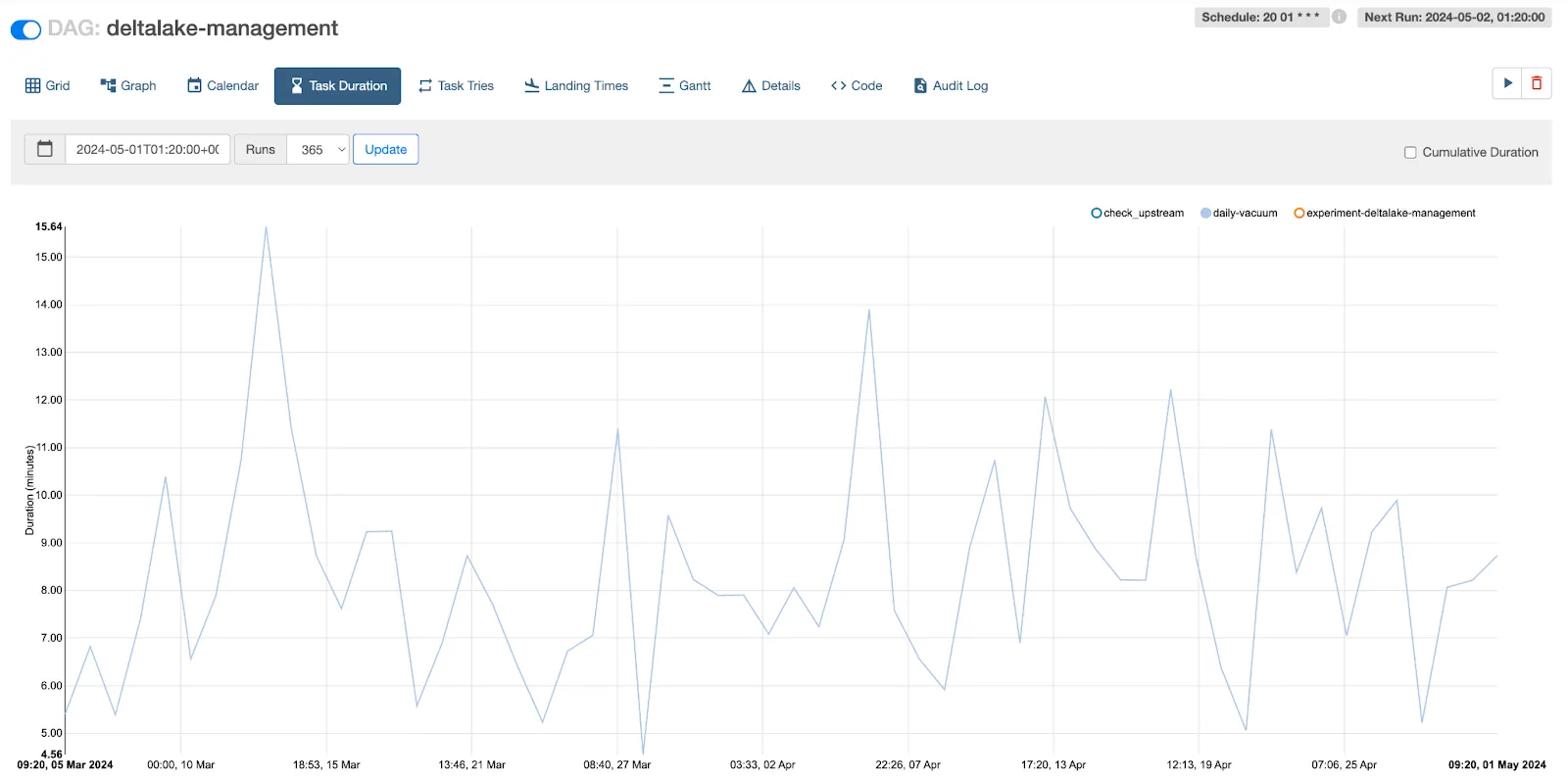
之后
我们运行单个作业来清理所有 3 个表,并将频率减少到 24 小时(从 6 小时减少)
成本分析
对于一个相当大的特定表,在切换后每天运行 vacuum,我们每天节省约 30-40 美元。这些节省仅包括计算和 EBS 成本。S3 API 成本还将有额外的节省。
然而,由于 vacuum 成本较高,许多其他表的 vacuum 操作执行频率较低。这项改进鼓励我们更频繁地进行 vacuum,从而节省存储和 API 成本。
总结
使用 Delta 3.1、优化的写入器和自动优化功能,以及在 Delta 3.2 中发布的基于清单的 Delta vacuum 功能,帮助我们显著降低了维护大型 Delta 表管道的成本。