Delta Lake vs. Parquet 对比
本文解释了 Delta Lake 和 Parquet 表之间的区别,以及为什么 Delta Lake 几乎总是实际用例中更好的选择。Delta Lake 拥有 Parquet 表的所有优点,以及许多其他对数据从业者至关重要的功能。因此,使用 Delta Lake 而非 Parquet 表几乎总是有利的。
当数据存储在单个文件中时,Parquet 表还可以,但当数据存储在许多文件中时,管理起来很困难,而且速度不必要地慢。Delta Lake 使管理多个 Parquet 文件中的数据变得容易。
让我们比较一下 Parquet 表和 Delta 表的基本结构,以便更好地理解 Delta Lake 的优势。
Parquet 文件的基本特性
Parquet 是一种不可变、二进制、列式文件格式,与 CSV 等基于行的格式相比具有多项优势。以下是 Parquet 文件与 CSV 相比的核心优势:
- Parquet 文件的列式特性允许查询引擎选择单个列。对于基于行的文件格式,查询引擎必须读取所有列,即使是与查询无关的列。
- Parquet 文件在元数据中包含 schema 信息,因此查询引擎无需推断 schema / 用户在读取数据时无需手动指定 schema。
- 像 Parquet 文件这样的列式文件格式比基于行的文件格式更易于压缩。
- Parquet 文件以行组存储数据。每个行组都包含每个列的最小/最大统计信息。Parquet 允许查询引擎针对特定查询跳过整个行组,这在读取数据时可以大幅提高性能。
- Parquet 文件是不可变的,这阻止了手动更新源数据的反模式。
请参阅此视频,了解 Parquet 优于 CSV 的五个原因,以获取更多信息。
您可以将小型数据集保存在单个 Parquet 文件中,而不会出现可用性问题。对于小型数据集,单个 Parquet 文件通常比 CSV 文件为用户提供更好的数据分析体验。
然而,数据从业者通常拥有跨多个 Parquet 文件分割的大型数据集。管理多个 Parquet 文件并不理想。
将数据存储在多个 Parquet 文件中的挑战
Parquet 表由数据存储中的文件组成。以下是一堆 Parquet 文件在磁盘上的样子。
some_folder/
file1.parquet
file2.parquet
…
fileN.parquet单个 Parquet 文件的许多可用性优势也延伸到了 Parquet 数据湖——在一个 Parquet 文件或多个 Parquet 文件上进行列剪枝都很容易。
以下是使用 Parquet 表的一些挑战:
- Parquet 数据湖没有 ACID 事务
- 从 Parquet 表中删除行并不容易
- 没有 DML 事务
- 没有变更数据源
- 文件列表开销缓慢
- 昂贵的页脚读取以收集文件跳过统计信息
- 无法在不重写整个表的情况下重命名、重新排序或删除列
- 还有更多
Delta Lake 使 Parquet 表的管理更轻松、更快速。Delta Lake 还经过优化,可防止您损坏数据表。让我们看看 Delta Lake 的结构,以了解它如何提供这些功能。
Delta Lake 的基本结构
Delta Lake 将元数据存储在事务日志中,并将表数据存储在 Parquet 文件中。以下是 Delta 表的内容。
some_folder/
_delta_log
00.json
01.json
…
n.json
file1.parquet
file2.parquet
…
fileN.parquet以下是 Delta 表的视觉表示
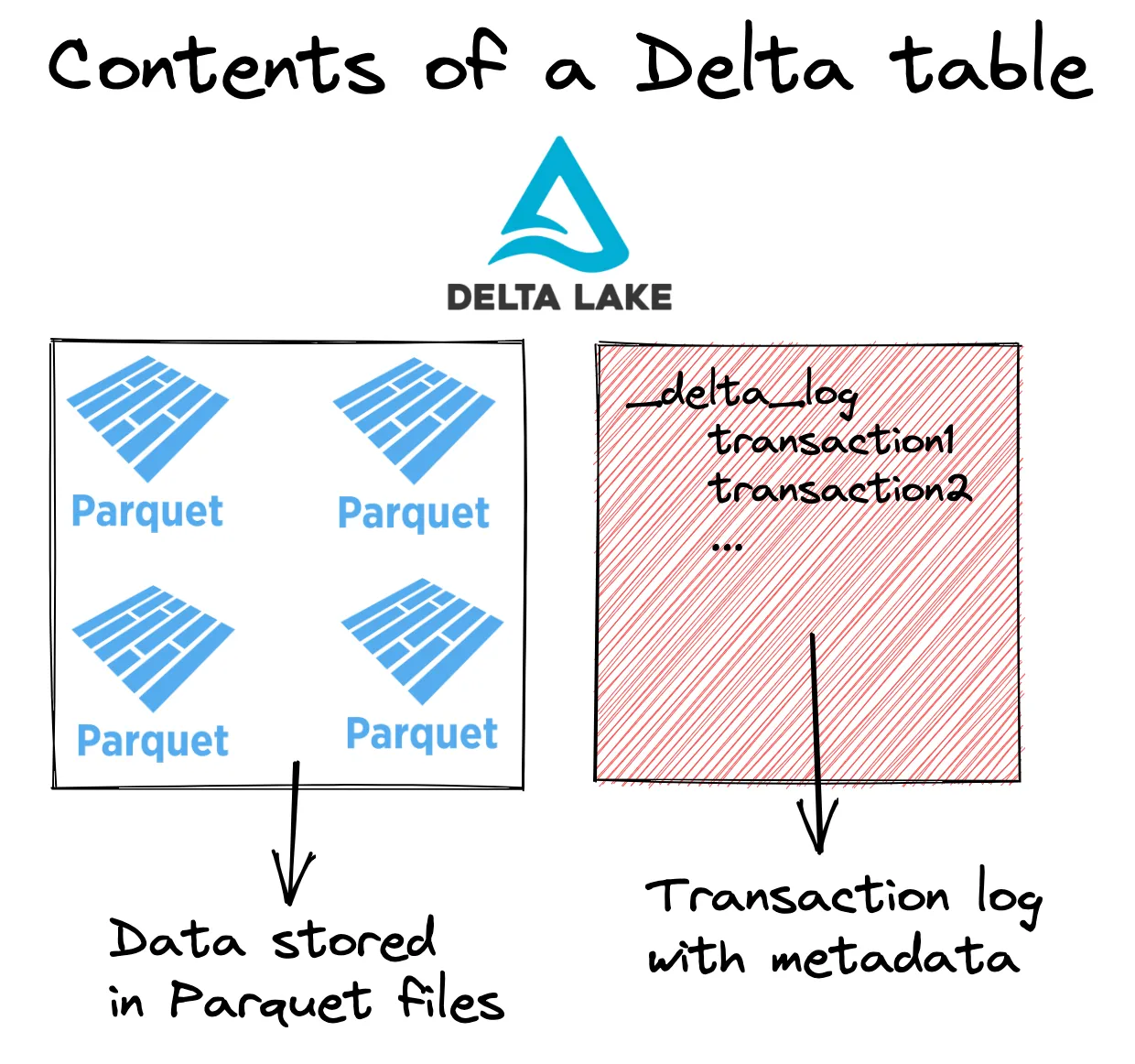
您可以通过查看协议来查看完整的 Delta Lake 规范。让我们看看 Delta Lake 如何加快文件列表操作。
Delta Lake vs. Parquet:文件列表
当您想要读取 Parquet 数据湖时,必须执行文件列表操作,然后读取所有数据。在列出所有文件之前,您无法读取数据。请参见下图:
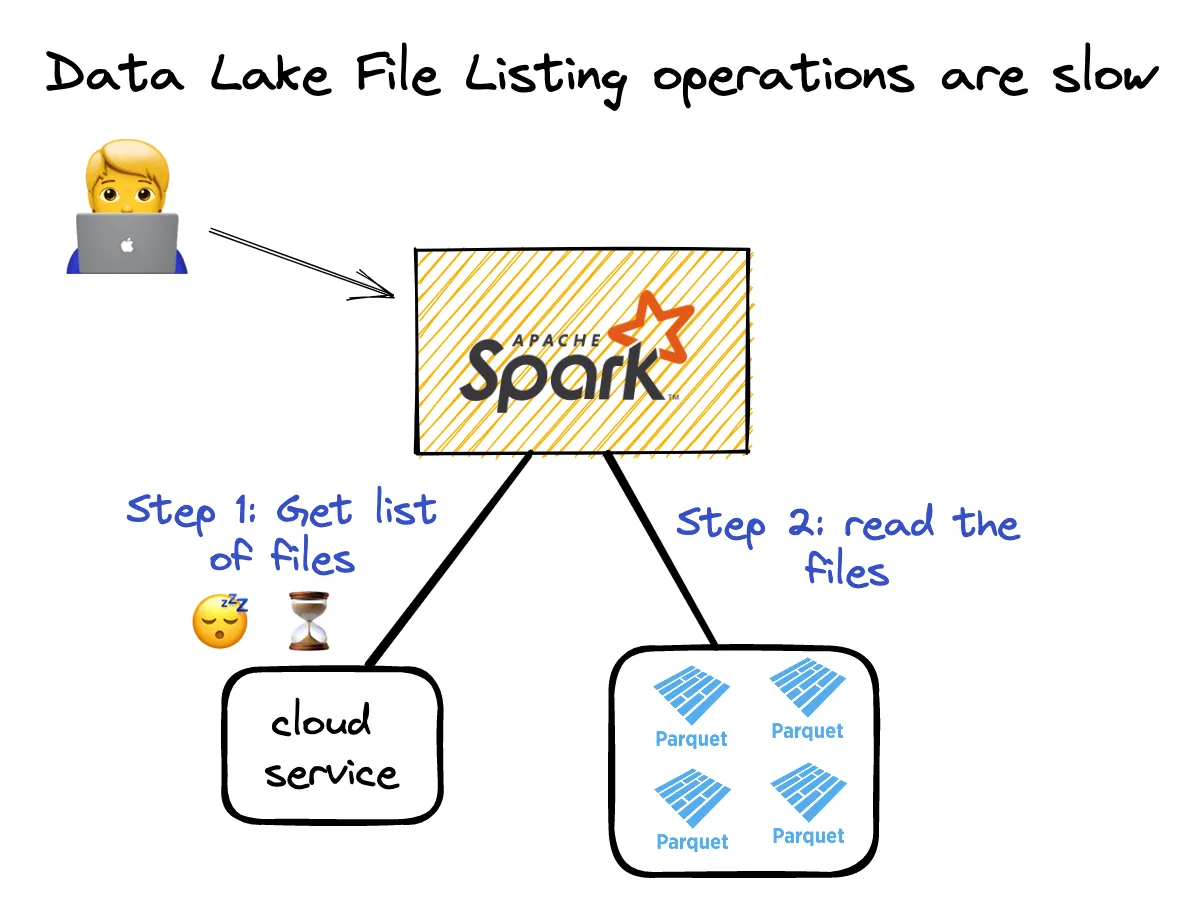
在 UNIX 文件系统上,列出文件的成本不是很高。对于云中的数据,文件列表操作较慢。基于云的文件系统是键/值对象存储,与类 UNIX 文件系统不同。键值存储在列出文件时速度较慢。
Delta Lake 将 Parquet 文件的路径存储在事务日志中,以避免执行昂贵的文件列表操作。Delta Lake 无需列出云对象存储中的所有 Parquet 文件来获取其路径。它只需在事务日志中查找文件路径即可。
云对象存储不擅长列出嵌套在目录中的文件。在基于云的系统中,使用 Hive 风格分区存储的文件可能需要数分钟或数小时才能完成文件列表操作。
最好依靠事务日志来获取表中文件的路径,而不是执行文件列表操作。
Delta Lake vs. Parquet:小文件问题
增量更新的大数据系统会创建大量小文件。当增量更新频繁发生且针对 Hive 分区数据集时,小文件问题尤为突出。
当读取包含许多小文件的数据集时,数据处理引擎的性能不佳。您通常希望文件大小在 64MB 到 1GB 之间。您不希望有需要过多 I/O 开销的微小 1KB 文件。
数据从业者通常希望通过一个称为“小文件压缩”或“bin-packing”的过程将小文件压缩成更大的文件。
假设您有一个包含 10,000 个小文件的数据集,查询速度很慢。您可以将这 10,000 个小文件压缩成一个包含 100 个大小合适文件的数据集。
如果您使用的是普通的 Parquet 数据湖,您需要自己编写小文件压缩代码。使用 Delta Lake,您只需运行 OPTIMIZE 命令,Delta Lake 就会为您处理小文件压缩。
ETL 管道通常会处理新文件。对于普通的 Parquet 数据湖,有两种类型的新文件:新数据和压缩成更大文件的旧数据。您不希望下游系统重新处理已处理的旧数据。Delta Lake 有一个 data_change=False 标志,允许下游系统区分新数据和仅是现有数据压缩版本的新文件。Delta Lake 对于生产 ETL 管道来说要好得多。
Delta Lake 使小文件压缩比普通的 Parquet 表更容易。请参阅这篇关于使用 OPTIMIZE 进行小文件压缩的博客文章,了解更多信息。
Delta Lake vs. Parquet:ACID 事务
数据库支持事务,与不支持事务的数据系统相比,这可以防止大量数据错误。
Parquet 表不支持事务,因此它们很容易损坏。假设您正在向现有 Parquet 数据湖追加大量数据,并且集群在写入操作中途崩溃。那么,您的表中将有几个部分写入的 Parquet 文件。
部分写入的文件将破坏任何后续的读取操作。计算引擎将尝试读取损坏的文件并报错。您需要手动识别所有损坏的文件并删除它们来修复您的数据湖。损坏的表通常会破坏组织中的许多数据系统,并且需要紧急热修复——这可不好玩。
Delta Lake 支持事务,因此您绝不会因为中途出错的写入操作而损坏 Delta Lake。如果集群在写入 Delta 表时崩溃,Delta Lake 将简单地忽略部分写入的文件,并且后续读取不会中断。事务还有许多其他好处,这只是其中一个例子。
Delta Lake vs. Parquet:列剪枝
如果您能向计算集群发送更少的数据,查询运行速度就会更快。基于列的文件格式允许您从表中精选特定列,而基于行的文件格式需要将所有列发送到集群。
Delta Lake 和 Parquet 都是列式的,因此您可以通过列剪枝(又称列投影)从数据集中精选特定列。列剪枝对于 Delta Lake 相比 Parquet 并不是优势,因为它们都支持此功能。Delta Lake 在底层将数据存储在 Parquet 文件中。
然而,对于存储在 CSV 或 JSON 等基于行的文件格式中的数据,列剪枝是不可能的,因此这对于 Delta Lake 相比基于行的文件格式来说是一个显著的性能优势。
Delta Lake vs. Parquet:文件跳过
Delta 表将有关底层 Parquet 文件的元数据信息存储在事务日志中。读取 Delta 表的事务日志并找出可以跳过的文件非常快。
Parquet 文件将行组的元数据存储在页脚中,但获取所有页脚并为整个表构建文件级元数据很慢。它需要文件列表操作,我们已经讨论过文件列表可能很慢。
Parquet 不支持文件级跳过,但支持行组过滤。
Delta Lake vs. Parquet:谓词下推过滤
Parquet 文件在页脚中包含元数据统计信息,数据处理引擎可以利用这些统计信息来更高效地运行查询。
向计算集群发送更少的数据是加快查询运行速度的好方法。您可以通过向引擎发送更少的列或行数据来实现这一点。
Parquet 文件页脚还包含文件中每个列的最小/最大统计信息(最小/最大统计信息实际上是针对每个行组进行跟踪的,但我们为了简化起见)。根据查询,您可以跳过整个行组。例如,假设您正在运行一个过滤操作,并希望查找所有 col4=65 的值。如果有一个 Parquet 文件,其最大 col4 值为 34,您就知道该文件不包含与您的查询相关的任何数据。您可以完全跳过它。
数据跳过的效率取决于您可以使用查询跳过多少文件。但这种策略可以提供 10 倍 - 100 倍或更高的速度增益——这至关重要。
当您读取单个 Parquet 文件时,Parquet 文件页脚中包含元数据是没问题的。如果您有 10,000 个文件,您不希望必须读取所有文件页脚,收集整个数据湖的统计信息,然后运行查询。那开销太大了。
Delta Lake 将元数据统计信息存储在事务日志中,因此查询引擎无需在运行查询之前读取所有单个文件并收集统计信息。从事务日志中获取统计信息效率更高。
Delta Lake Z 排序索引
当相似数据共存时,跳过操作效率更高。
Data & AI Summit 上的演讲《为什么 Delta Lake 是 pandas 分析的最佳存储格式》展示了在 Delta 表中进行 Z 排序可以显著缩短查询运行时间。
在 Delta 表中对数据进行 Z 排序很容易。在 Parquet 表中对数据进行 Z 排序并不容易。请参阅关于Delta Lake Z 排序的博客文章以了解更多信息。
Delta Lake vs. Parquet:重命名列
Parquet 文件是不可变的,因此您无法修改文件以更新列名。如果您想更改列名,需要将其读入 DataFrame,更改名称,然后重写整个文件。重命名列可能是一项昂贵的计算。
Delta Lake 抽象了物理列名和逻辑列名的概念。物理列名是 Parquet 文件中实际的列名。逻辑列名是人们引用列时使用的列名。
Delta Lake 允许用户通过更改逻辑列名快速重命名列,这是一种纯元数据操作。这只是 Delta 事务日志中的一个简单条目。
没有快速的方法可以更新 Parquet 表的列名。您需要读取所有数据,重命名列,然后重写所有数据。这对于大型数据集来说很慢。
Delta Lake vs. Parquet:删除列
Delta Lake 还允许您快速删除列。您可以向 Delta 事务日志添加一个条目,并指示 Delta 在未来的操作中忽略这些列——这是一种纯元数据操作。
Parquet 表要求您读取所有数据,使用查询引擎删除列,然后重写所有数据。对于一个相对较小的操作来说,这是一项大规模的计算。
有关如何从 Delta 表中删除列的更多信息,请参阅此博客文章。
Delta Lake vs. Parquet:Schema 强制执行
您通常希望允许追加与现有表 schema 匹配的 DataFrame,并拒绝追加与 schema 不匹配的 DataFrame。
对于 Parquet 表,您需要手动编写此 schema 强制代码。默认情况下,您可以将任何 schema 的 DataFrame 追加到 Parquet 表中(除非它们在 metastore 中注册并通过 metastore 提供 schema 强制执行)。
Delta Lake 具有内置的 schema 强制执行功能,这可以帮助您避免可能损坏 Delta Lake 的代价高昂的错误。有关 schema 强制执行的更多信息,请参阅此文章。
您还可以绕过 Delta 表中的 schema 强制执行,并随时间更改表的 schema。
Delta Lake vs. Parquet:Schema 演进
有时,您希望向 Delta Lake 添加额外的列。也许您依赖某个数据供应商,他们的数据源中添加了新列。您不希望重写所有现有数据并添加一个空列,以便向表中添加新列。您希望有点 schema 灵活性。您只希望写入带有额外列的新数据,并保持所有现有数据不变。
Delta Lake 允许 schema 演进,因此您可以无缝地向数据集中添加新列,而无需运行大型计算。这是另一个在实际数据应用中常用的便捷功能。有关 schema 演进的更多信息,请参阅此博客文章。
如果将 schema 不匹配的 DataFrame 追加到 Parquet 表中。在这种情况下,您每次读取表时都必须记住设置一个特定选项,以确保结果准确。查询引擎通常在确定 Parquet 表的 schema 时会走捷径。它们查看一个文件的 schema,然后假设所有其他文件都具有相同的 schema。
当您手动设置标志时,引擎会查阅 Parquet 表中所有文件的 schema,以确定整个表的 schema。检查所有文件的 schema 在计算上更昂贵,因此默认情况下不设置。Delta Lake schema 演进优于 Parquet 所提供的。
Delta Lake vs. Parquet:检查约束
您还可以对列应用自定义 SQL 检查,以确保追加到表中的数据符合指定的格式。
仅仅检查字符串列的 schema 可能不足够。您可能还希望确保字符串匹配特定的正则表达式模式,并且列不包含 NULL 值。
Parquet 表不支持 Delta Lake 那样的检查约束。请参阅这篇关于Delta Lake 约束和检查的博客文章以了解更多信息。
Delta Lake vs. Parquet:版本化数据
Delta 表可以有许多版本,用户可以轻松地在不同版本之间“时间旅行”。版本化数据对于监管要求、审计目的、实验和回滚错误非常有用。
版本化数据还会影响引擎执行某些事务的方式。例如,当您“覆盖”Delta 表时,您不会从存储中物理删除文件。您只是将现有文件标记为已删除,但实际上并未删除它们。这称为“逻辑删除”。
Parquet 表不支持版本化数据。当您从 Parquet 表中删除数据时,您实际上是从存储中删除它,这称为“物理删除”。
逻辑数据操作更好,因为它们更安全,并且允许撤销错误。如果您覆盖了 Parquet 表,这是一个不可逆转的错误(除非有单独的机制备份数据)。在 Delta 表中,撤销覆盖事务很容易。
请参阅这篇关于为什么 PySpark 的 append 和 overwrite 操作在 Delta Lake 中比 Parquet 表更安全的博客文章以了解更多信息。
Delta Lake vs. Parquet:时间旅行
版本化数据还允许您轻松地在 Delta Lake 的不同版本之间切换,这称为时间旅行。
时间旅行在各种情况下都很有用,如Delta Lake 时间旅行文章中详细描述的。Parquet 表不支持时间旅行。
Delta Lake 需要保留一些数据版本以支持时间旅行,如果您不需要历史数据版本,这会增加不必要的存储成本。Delta Lake 让您可以轻松地选择性删除这些旧文件。
Delta Lake vacuum 命令
您可以使用 Delta Lake vacuum 命令删除旧文件。例如,您可以将保留期设置为 30 天,然后运行 vacuum 命令,这将允许您删除所有超过 30 天的不必要数据。
当然,它不会删除所有超过 30 天的数据。如果 Delta Lake 当前版本中仍需要“旧”数据,它将不会被删除。
一旦运行 vacuum 命令,您就无法回滚到 Delta Lake 的早期版本。如果您将保留期设置为 7 天并执行了 vacuum 命令,您就无法时间旅行回 60 天前的 Delta Lake 版本。
有关Delta Lake VACUUM 命令的更多信息,请参阅此博客文章。
Delta Lake 回滚
Delta Lake 还让您可以轻松地将整个数据湖重置到早期版本。假设您在周三插入了一些数据,并发现它不正确。您可以轻松地将整个 Delta Lake 回滚到周二的状态,从而有效地撤销您在周三犯的所有错误。
如果您已经运行了 vacuum 命令,则无法将 Delta Lake 回滚到早于保留期的版本。这就是为什么在清理 Delta Lake 之前需要小心。
这篇关于如何使用 Restore 将 Delta Lake 表回滚到以前的版本的博客文章。
Delta Lake vs. Parquet:删除行
您可能希望能够从表中删除行,特别是为了遵守 GDPR 等监管要求。Delta Lake 可以轻松执行最小删除操作,而从 Parquet 数据湖中删除行并不容易。
假设有一个用户希望删除他们的账户并从您的系统中删除所有数据。您在表中存储了他们的一些数据。您的表有 50,000 个文件,而该特定客户的数据位于其中 10 个文件中。
Delta Lake 可以轻松运行删除命令,并将高效地重写这 10 个受影响的文件,而不包含客户数据。Delta Lake 还使编写一个标记已删除行的文件(删除向量)变得容易,这使得此操作运行得更快。
如果您有一个 Parquet 表,唯一方便的操作是读取所有数据,过滤掉该特定用户的数据,然后重写整个表。那将花费很长时间!
手动识别包含用户数据的 10 个文件并重写这些特定文件既繁琐又容易出错。这正是您希望委托给 Lakehouse 存储系统而不是自己执行的任务。
请查看如何从 Delta Lake 表中删除行的博客文章以了解更多信息。另外,请务必查看Delta Lake 删除向量博客文章,了解删除操作如何运行得更快。
Delta Lake vs. Parquet:合并事务
Delta Lake 提供了强大的合并命令,允许您更新行、执行 upsert、构建缓慢变化的维度表等。
Delta Lake 使得执行合并命令变得容易,并且像删除命令的高效实现一样,在底层高效地更新最小数量的文件。
如果您使用 Parquet 表,则无法访问任何合并命令。您需要自己实现所有低级合并细节,这既具有挑战性又耗时。
请参阅Delta Lake Merge 博客文章,了解它如何简化数据操作语言操作(INSERT、UPDATE 和 DELETE)。
Delta Lake 表的其他优势
Delta Lake 相比 Parquet 表还有许多其他优势,本文未讨论,但您可以查看这些文章以了解更多信息:
结论
本文向您展示了 Delta Lake 通常优于 Parquet 表。Delta Lake 使执行常见的数据操作(例如删除列、重命名列、删除行和 DML 操作)变得容易。Delta Lake 还支持事务和 schema 强制执行,因此您的表损坏的可能性大大降低。Delta Lake 将文件元数据抽象到事务日志中并支持 Z 排序,因此您可以更快地运行查询。
当您与不支持 Delta Lake 的系统交互时,Parquet 数据湖仍然很有用。如果下游系统无法读取 Delta Lake 格式,您可能需要将 Delta Lake 转换为 Parquet 数据湖。Delta 表将数据存储在 Parquet 文件中,因此从 Delta 表转换为 Parquet 表很容易。使用其他系统读取 Delta 表是一个微妙的话题,但已经构建了许多 Delta Lake 连接器,因此您不太可能无法使用您选择的查询引擎读取 Delta 表。
请参阅这篇博客文章,了解不断增长的 Delta Lake 连接器生态系统。