Delta Lake 与 ORC 比较
作者:Avril Aysha
Delta Lake 与 ORC
本文解释了 Delta Lake 和 ORC(优化行式列式)表之间的区别。
ORC 是 Apache Hive 项目或处理小型数据集且不需要强 ACID 事务时的良好文件格式。当数据存储在许多文件中时,ORC 表会变得缓慢且难以管理。Delta Lake 使管理许多文件中的数据变得容易,而不会丢失或损坏数据。
Delta Lake 拥有 ORC 表的所有优点以及许多其他对数据从业者至关重要的功能。
让我们比较 ORC 表和 Delta 表的基本结构,以更好地理解 Delta Lake 的优势。
ORC:基本属性
ORC 是一种用于存储结构化数据的不可变列式文件格式。
与 CSV 等基于行的格式相比,ORC 具有一些重要优势
- 它是一种列式文件格式。这意味着查询引擎可以轻松忽略与查询无关的列。基于行的格式要求引擎遍历整个文件。
- 它将模式和元数据硬编码到文件中。这意味着查询引擎不需要推断模式(容易出错),用户也不需要手动指定它(耗时)。
- 它提供出色的压缩功能,以实现更好的存储优化。
- 它将数据存储在称为“条带”的块中。文件包含每个条带的元数据,这可以通过数据跳过实现查询优化。
- 它是一种不可变文件格式,可降低意外数据更新的风险。
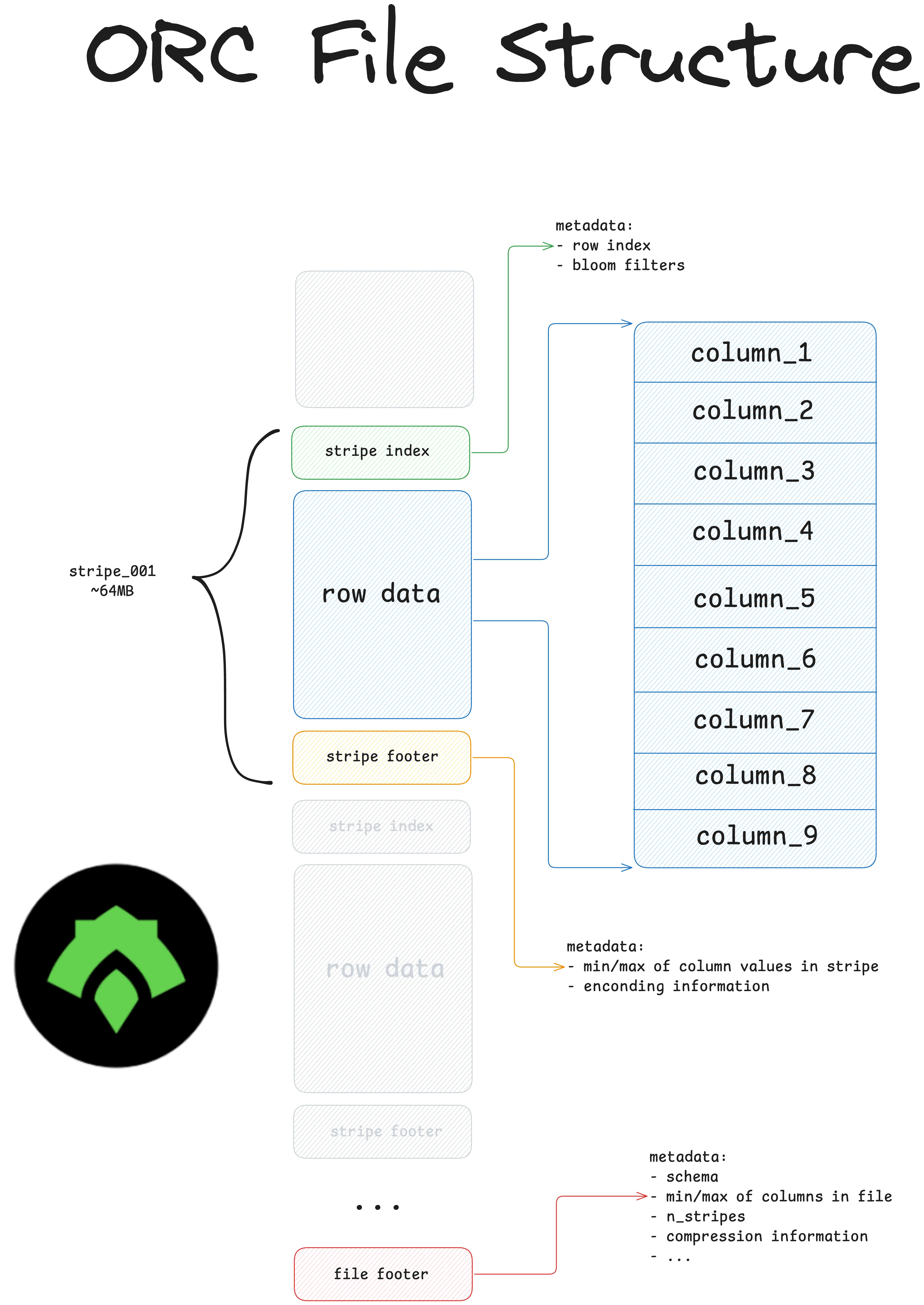
ORC 的开发目的是
- 加速 Apache Hive 中的工作负载
- 提高 Hadoop 分布式文件系统 (HDFS) 的存储效率
- 优化大型读密集型数据操作
以下是 ORC 目录在磁盘上的样子
my_data.orc
_SUCCESS
part-00000-add4a8a6-feef-4796-b1ec-2134a2d2b03f-c000.snappy.orc
part-00001-add4a8a6-feef-4796-b1ec-2134a2d2b03f-c000.snappy.orc
part-00002-add4a8a6-feef-4796-b1ec-2134a2d2b03f-c000.snappy.orc
part-00003-add4a8a6-feef-4796-b1ec-2134a2d2b03f-c000.snappy.orc
...以 ORC 格式存储的数据集包含每个分区一个单独的文件。`_SUCCESS` 文件是一个空标记文件,用于指示操作(例如写入或保存数据)已成功完成。这种标记文件在 Hadoop 分布式文件系统 (HDFS) 和类似的存储系统中是常见的做法。
使用 ORC 的挑战
以下是使用 ORC 的一些挑战
- 在 Apache Hive 和 Hadoop 之外的功能有限
- 不原生支持 ACID 事务
- 文件列表开销(小文件问题)
- 昂贵的页脚读取以收集文件跳过的统计信息
- 没有数据版本控制或时间旅行功能
- 更改和删除列很困难
- 没有模式强制导致数据损坏的可能性很高
让我们看看 Delta Lake 表的基本结构,了解其设计如何支持数据从业者的关键功能。
Delta Lake:基本结构
Delta Lake 将元数据存储在事务日志中,将表数据存储在 Parquet 文件中。以下是 Delta 表的内容
your_delta_table/ <-- this is the top-level table directory
_delta_log <-- this is the transaction log which tracks
00.json all the changes to your data
01.json
…
n.json
file1.parquet <-- these are your Delta table partitions,
file2.parquet ordered for maximum query performance
…
fileN.parquet这是 Delta 表的可视化表示
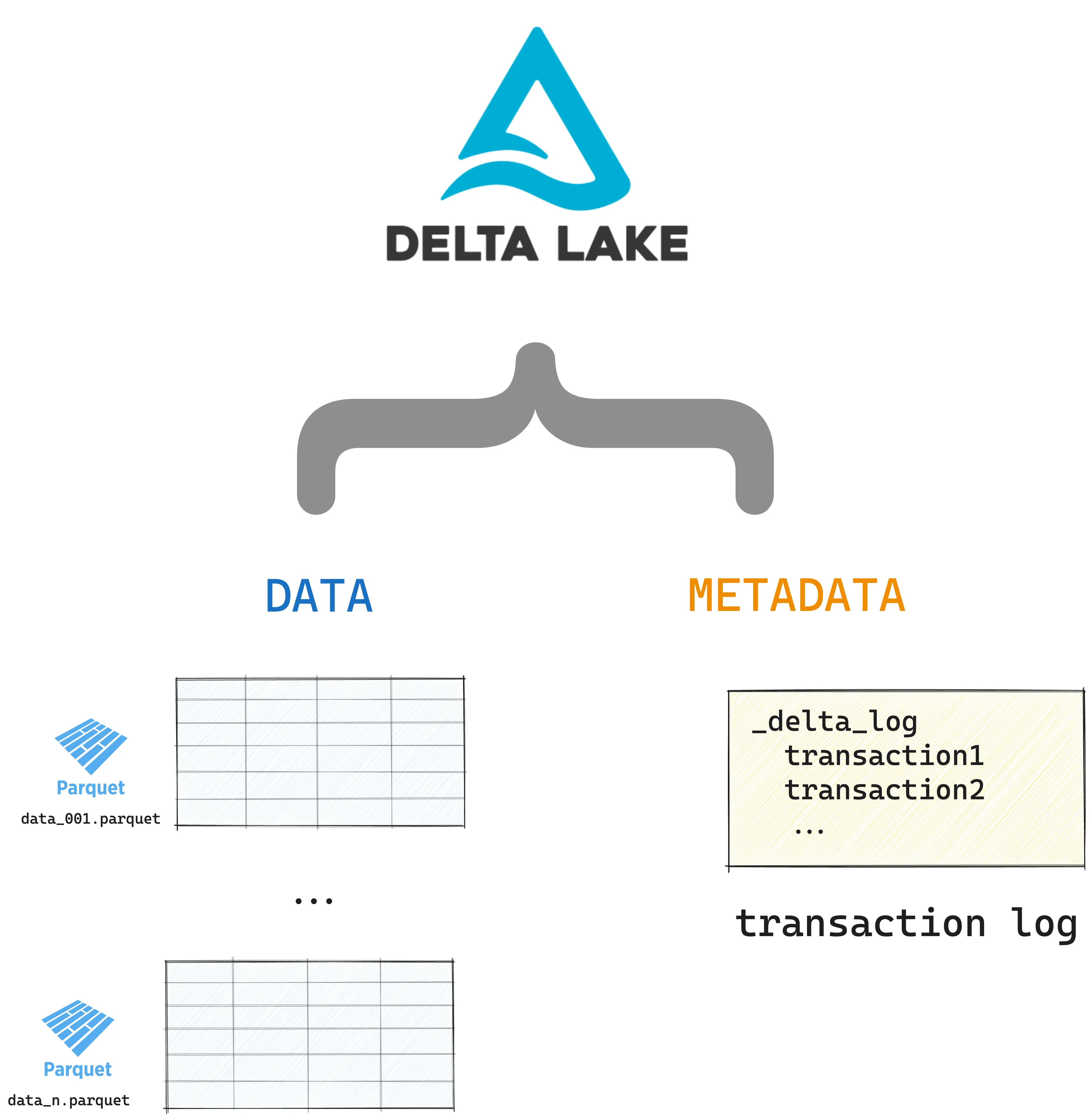
您可以查看 协议 来查看完整的 Delta Lake 规范。
让我们看看 Delta Lake 如何加快文件列表操作。
Delta Lake 与 ORC:文件列表
要读取 ORC 中存储的数据,您首先必须执行文件列表操作。您的 ORC 读取器需要知道所有文件的路径才能读取它们。
这对于小型数据集来说没问题,但当您拥有更多数据时,会变得缓慢且昂贵,尤其是在您从云端读取文件时。云文件系统使用键/值存储来引用数据,这些存储在列表操作方面比 UNIX 文件系统慢。
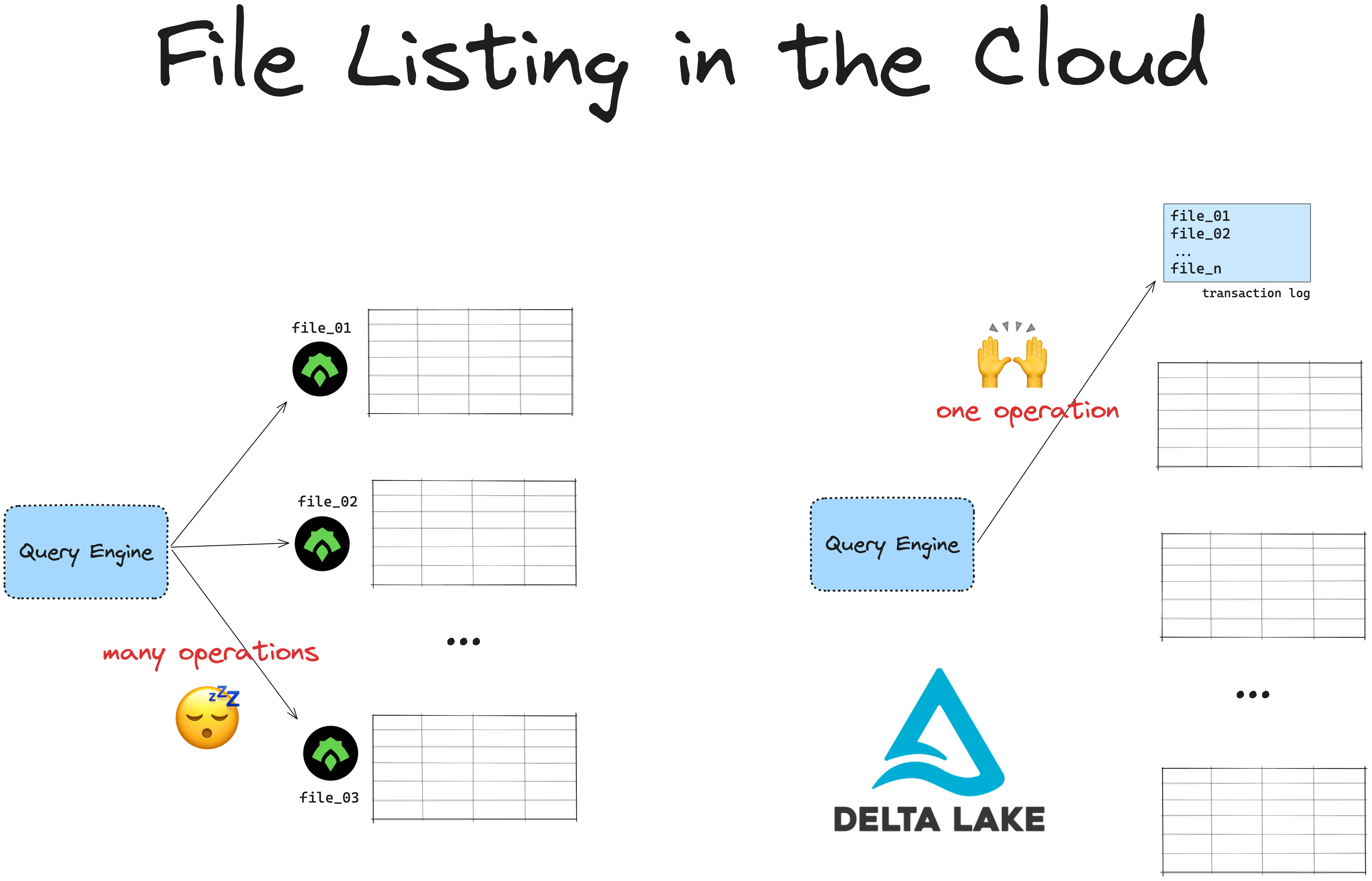
云对象存储在列出嵌套在目录中的文件时尤其慢。Hive 样式分区通常就是这种情况。使用 Hive 样式分区列出存储在云中的文件可能需要几分钟甚至几小时才能计算。
Delta Lake 将所有底层文件的路径存储在事务日志中。这是一个单独的文件,不需要昂贵的列表操作。与 ORC 文件相比,文件越多,使用 Delta Lake 读取数据的速度就越快。
Delta Lake 与 ORC:数据跳过
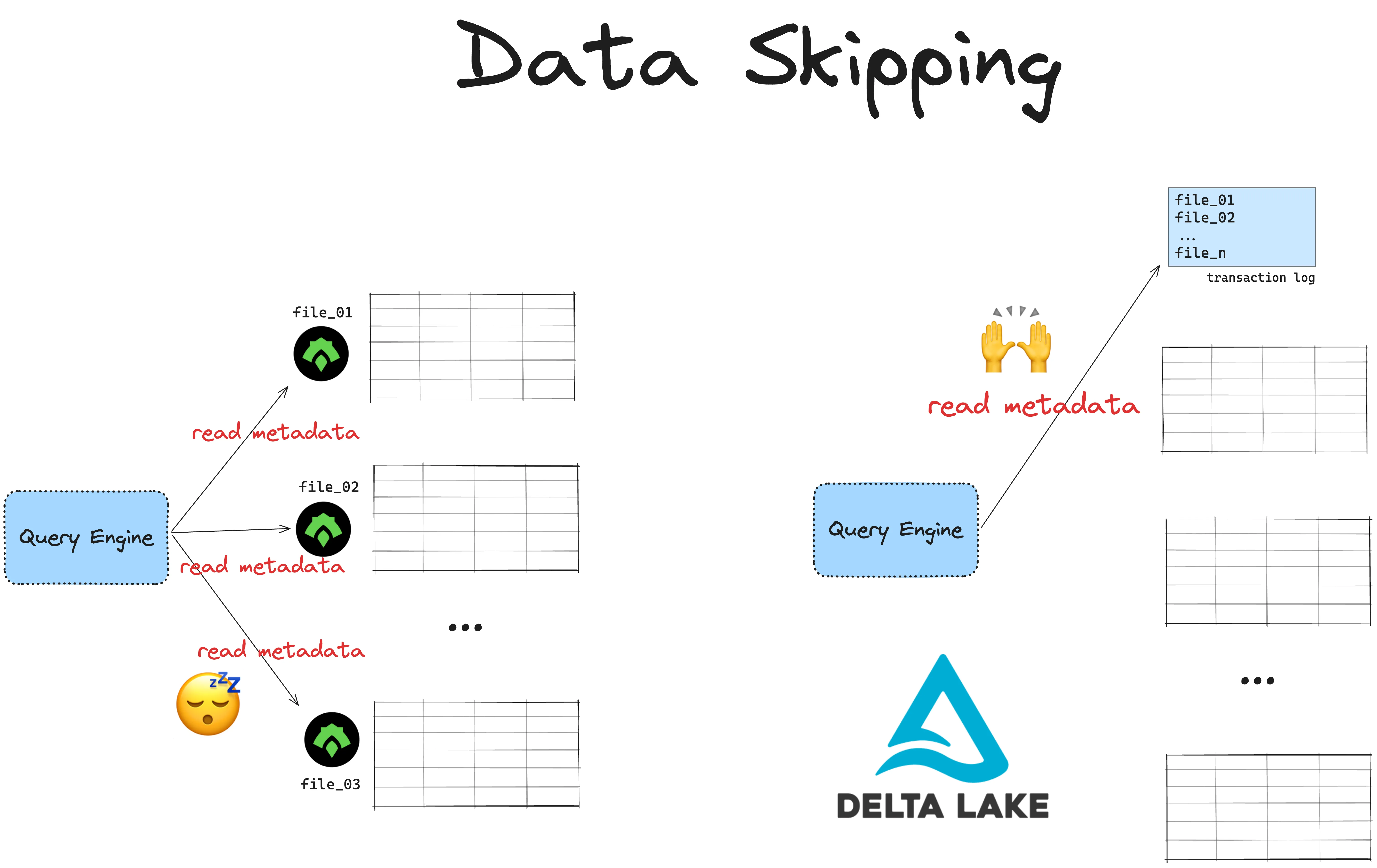
ORC 在文件级别和条带级别包含元数据,例如模式、条带和行数、布隆过滤器以及每列的最小值/最大值。此元数据允许 ORC 读取器通过跳过不相关的数据来执行高效的查询优化。
但 ORC 将每个分区存储为自己的文件。这意味着您的 ORC 读取器需要独立访问每个分区文件以获取元数据。当您处理分布在许多分区文件中的大量数据时,这将导致昂贵的页脚读取。
Delta Lake 将所有元数据存储在单独的事务日志中的表级别。查询引擎可以通过一次读取访问所有元数据,并快速知道要跳过哪些数据。这要快得多。
Delta Lake 与 ORC:ACID 事务
Delta Lake 通过支持 ACID 事务来防止操作损坏您的表。事务是任何更改表的写入操作。
ORC 不支持 ACID 事务。
ORC 表更容易损坏,因为它们不支持事务。如果您正在向现有 ORC 表写入大量数据,而您的集群崩溃,您将留下一个失败的部分写入。损坏的表可能会破坏许多下游数据系统,并且需要手动热修复。这可能会耗时且昂贵,而且肯定不好玩。
支持 ACID 事务的系统不可能出现这种情况:整个写入操作将失败,您可以自由重试,而无需处理损坏的表。
事务还协调来自多个进程的安全并发写入,并防止意外数据丢失。在生产环境中处理大数据时,您几乎总是需要 ACID 事务。
那么 ACID ORC 呢?
ACID ORC 指的是 Apache ORC 文件格式与 Apache Hive 的专门使用,以支持 Hive 表中的 ACID 事务。
此功能是 Hive 事务表功能的一部分。ACID 功能由 Hive 的事务框架启用,该框架仅使用 ORC 作为底层文件格式进行存储。
ORC 本身不支持 ACID 事务。
Delta Lake 与 ORC:使用您喜欢的工具
ORC 的创建是为了解决 Apache Hive 和 Apache Hadoop 工作负载的特定问题。在这些环境之外以 ORC 格式存储文件仍然可以快速且节省存储空间,但您将无法获得完整的功能体验。Polars 和 DuckDB 等流行的 Python 库目前不提供对 ORC 文件的完整读/写支持。
Delta Lake 可以从 Apache Spark、Python、Rust 和 许多其他流行的查询引擎 中使用。您还可以使用 Delta Kernel 项目来构建自己的连接器。
Delta Lake 与 ORC:布隆过滤器
布隆过滤器是 ORC 文件的一个流行功能。
布隆过滤器是一种概率数据结构,用于确定某个值可能存在于某个列中,还是肯定不存在。在 ORC 中,为每个列构建一个布隆过滤器。这允许 ORC 读取器检查某个值是否可能在列中。
布隆过滤器存储在每个 ORC 文件的条带级别。这意味着 ORC 读取器必须访问每个分区文件中的每个条带。如上所述,当您处理存储在许多分区文件中的大型数据集时,这可能导致昂贵的读取操作。
Delta Lake 将用于数据跳过的所有元数据存储在单独的事务日志中的分区和表级别。Delta 读取器可以只访问事务日志,而无需读取所有分区文件。这要快得多。
Delta Lake 与 ORC:小文件问题
像 ORC 这样的不可变格式可能导致磁盘上有太多小文件。这被称为小文件问题,可能导致查询变慢。
假设您有一个表需要每天更新多次。您将表存储在 ORC 中,因为它具有出色的压缩和数据跳过功能,并且它是不可变的:没有人能够意外覆盖您的数据。
但由于 ORC 是不可变的,每次更新都会创建一个新文件。随着时间的推移,对该表的查询可能会因小文件问题而导致性能下降。
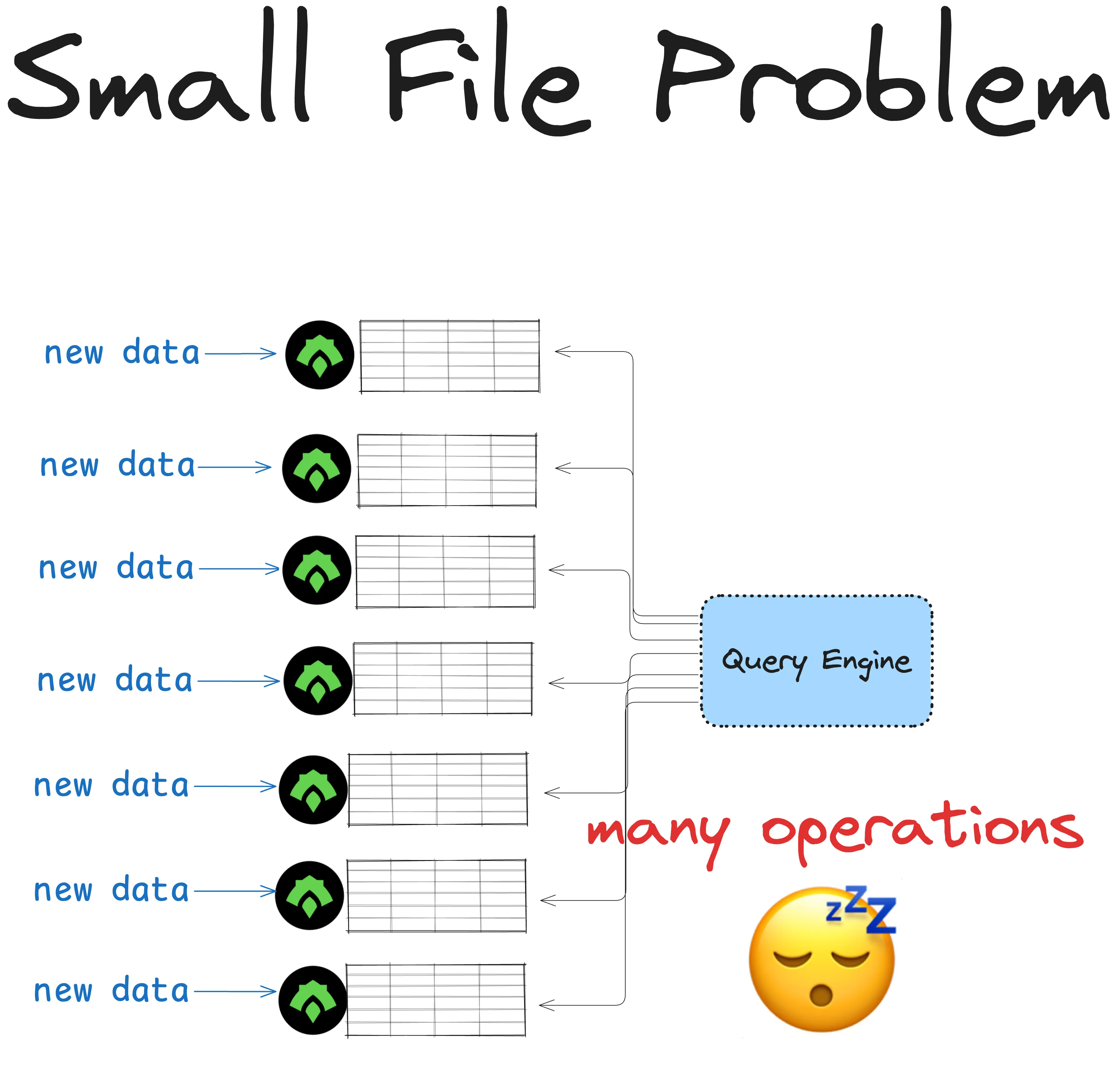
为了解决这个问题,您将不得不手动将数据合并到更大的文件中,删除过时文件或扩展您的计算以提高查询速度。这可能很昂贵。
Delta Lake 提供自动维护操作,例如 自动压缩和优化写入,以帮助您处理小文件问题。这些操作将您的较小文件压缩成更大、性能更好的文件。
Delta Lake 与 ORC:Hive 样式分区
小文件问题经常发生在使用 Hive 样式分区的数据集中。
Hive 样式分区是将大型数据集根据分区列(例如日期、区域等)组织成层次结构目录的做法。每个目录将包含单独文件中的数据。这曾经是通过使查询引擎更容易跳过分区来优化数据读取性能的最快方法。
Hive 样式分区数据集看起来像这样
my_dataset
year=2024
month=01
month01_001.orc
month01_002.orc
…
month=02
month02_001.orc
…
month=03
month03_001.orc
…ORC 是专门为 Apache Hive 环境开发的,并经常用于执行 Hive 样式分区。
Hive 样式分区不再是分区大型数据集最有效的方式。它有两个主要问题
- 它假设您在分区数据时知道所有要运行的查询,这可能导致当查询更改时昂贵的重新分区。
- 当存在许多分区列时,它会导致小文件问题
传统系统使用物理磁盘(即 Hive 样式)分区进行文件跳过。像 Delta Lake 这样的现代系统使用事务日志中的分区信息进行文件跳过。
在 Hive 样式分区的优缺点 中阅读更多内容。
Delta Lake 与 ORC:重命名列
ORC 文件是不可变的。这意味着您无法直接修改它们来重命名列。要更改列名,您必须加载数据,重命名列,然后再次保存整个文件。这可能既昂贵又耗时,特别是对于大型数据集。
Delta Lake 通过分离物理和逻辑列名来简化此操作。物理列名是存储在底层数据文件中的名称。逻辑列名是用户与之交互的名称。
通过这种方式,Delta Lake 允许您通过修改逻辑列名来快速重命名列,这只是记录在 Delta 事务日志中的一个简单的元数据更改。此操作速度快,不涉及重写数据。
Delta Lake 与 ORC:删除列
Delta Lake 使删除列变得容易。您可以简单地向 Delta 事务日志添加一个条目,告诉 Delta 在将来的操作中忽略该列。这是一个快速操作,不需要重写数据——您只更改元数据。
使用 ORC 表删除列更复杂。因为 ORC 是不可变表格式,您必须读取整个数据集,使用查询引擎删除列,然后重写所有数据。这个过程计算成本高昂,尽管任务本身非常简单。
有关 如何从 Delta 表中删除列 的更多信息,请参阅此博客文章。
Delta Lake 与 ORC:模式强制
在将新数据写入现有表时,您通常希望确保新数据遵循与现有数据集相同的模式。否则,您将得到不匹配的列,这可能会破坏下游系统。此过程称为模式强制,有助于维护数据集的一致性。
常规 ORC 表不支持模式强制。这意味着通过附加具有不匹配模式的数据来损坏您的表是可能的。
Delta Lake 默认内置了模式强制。这可以防止您意外损坏数据。让我们看看实际操作。
我们将创建一个具有预定义模式的 Delta 表
df = spark.createDataFrame([("bob", 47), ("li", 23), ("leonard", 51)]).toDF(
"first_name", "age"
)
df.write.format("delta").save("tmp/fun_people")现在,让我们尝试将具有不同模式的数据写入此相同的 Delta 表
df = spark.createDataFrame([("frank", 68, "usa"), ("jordana", 26, "brasil")]).toDF(
"first_name", "age", "country"
)
df.write.format("delta").mode("append").save("tmp/fun_people")此操作将报错 `AnalysisException`
AnalysisException: A schema mismatch detected when writing to the Delta table (Table ID:...).Delta Lake 默认不允许您附加具有不匹配模式的数据。阅读 Delta Lake 模式强制 文章以了解更多信息。
您还可以绕过 Delta 表中的模式强制,并随时间更改表的模式。
Delta Lake 与 ORC:模式演进
有时您需要表格模式的灵活性。您可能需要添加新列或更改数据类型。
使用 ORC 可以实现这一点,因为它不支持模式强制。默认情况下,您的表格模式没有明确的控制。这为您提供了灵活性(您可以添加任何喜欢的数据),但代价是可靠性(您的下游表格读取可能会中断)。查询引擎通常通过查看一个文件的模式来推断 ORC 表的模式,然后假设所有其他文件都具有相同的模式。这容易出错。
Delta Lake 支持模式演进,因此您可以轻松安全地更新您的模式,而无需运行大型计算。这是另一个对处理生产中大数据的数据从业者有用的关键功能。在 Delta Lake 模式演进 博客文章中阅读更多内容。
要更新 Delta 表的模式,您可以使用 mergeSchema 选项写入数据。让我们为上面刚刚看到的示例尝试一下
df.write.option("mergeSchema", "true").mode("append").format("delta").save(
"tmp/fun_people"
)这是写入后 Delta 表的内容
spark.read.format("delta").load("tmp/fun_people").show()
+----------+---+-------+
|first_name|age|country|
+----------+---+-------+
| jordana| 26| brasil| # new
| frank| 68| usa| # new
| leonard| 51| null|
| bob| 47| null|
| li| 23| null|
+----------+---+-------+Delta 表现在有三列。它以前只有两列。当添加新列时,新列没有数据的行将被标记为 null。
Delta Lake 模式演进优于 ORC 所提供的。
Delta Lake 与 ORC:数据版本控制
ORC 不支持内置数据版本控制。覆盖或删除 ORC 表中的数据意味着它永远消失了,您无法回滚到它。这被称为“物理删除”。
当您或同事意外更新数据时,这就会成为一个问题。ORC 表不提供撤消这些更改的简单方法。
Delta Lake 通过其事务日志原生支持数据版本控制。对数据所做的每个更改都记录在此日志中,为所有转换提供了清晰的历史记录,便于参考。覆盖和删除是更新事务日志的“逻辑删除”。未来的读取将不再引用被覆盖或删除的数据,但旧数据仍可供将来检索。
您可以使用 VACUUM 命令 对过期数据执行显式物理删除。
Delta Lake 与 ORC:时间旅行
数据版本控制意味着 Delta Lake 也支持时间旅行。您可以轻松地在 Delta 表的不同版本之间切换。这使得撤销意外更改或查看数据以前的状态变得简单。
您可以像这样加载 Delta 表的特定版本:
spark.read.format("delta").option("versionAsOf", version).load("path/to/delta")在 Delta Lake 时间旅行 文章中阅读更多关于时间旅行的信息。
Delta Lake 与 ORC:Apache Hive 工作负载
ORC 针对 Apache Hive 进行了优化。Delta Lake 的 Hive 连接器 支持读取 Delta 表,但不具有原生写入支持。
有关更多详细信息,请参阅 没有 Spark 的 Delta Lake 博客。
Delta Lake 表的其他优势
Delta Lake 相对于 ORC 表还有许多其他优势,本文未作讨论。您可以查看这些文章以了解更多信息
结论
本文解释了 Delta Lake 和 ORC 之间的区别。Delta Lake 拥有 ORC 的所有出色功能以及许多其他关键功能。
如果您满足以下条件,请考虑使用 ORC
- 必须在 Apache Hive 环境中工作
- 正在处理小型数据集
- 正在运行不需要 ACID 事务的非生产工作负载
如果您满足以下条件,请考虑使用 Delta Lake
- 正在处理存储在云端的大型数据集
- 在 ETL 管道 中需要 ACID 事务以获得生产级可靠性
- 关心最大的数据跳过性能
- 正在使用 Polars 或 DuckDB 等 Python 库