Delta Lake 与数据湖——有什么区别?
作者:Avril Aysha
本文定义了 Delta Lake 和数据湖,并解释了在决定如何存储数据时应了解的差异。
数据湖是一个中央存储库,用于存储和处理原始数据,无论其大小或格式如何。数据湖为您提供了灵活性,但牺牲了性能和可靠性。
Delta Lake 是一种用于数据存储的开源表格式。Delta Lake 通过支持 ACID 事务、高性能查询优化、模式演进、数据版本控制和许多其他功能来改进数据存储。
数据湖很容易变成数据沼泽。将大量不同的文件格式和数据类型倾倒在一个位置,而没有适当的版本控制或模式强制,可能会很快变得一团糟。Delta Lake 帮助您解决这些问题,并在不影响性能和可靠性的前提下保持灵活性。
“数据湖”是一个通用术语,描述了一种数据存储方法,这种方法可以存在于任何您可以存储混合数据格式的地方。例如,您可能有一个数据湖,其中包含位于 AWS S3 存储桶中的 Parquet、JSON 和非结构化文本文件。
“Delta Lake”是一种特定的开源技术。您没有 Delta Lake;您使用 Delta Lake 将数据存储在 Delta 表中。Delta Lake 使您的数据湖更安全、性能更高。这通常被称为数据湖仓架构。
Delta Lake 是开放表格式的一个例子。本文将比较数据湖与 Delta Lake。如果您的数据湖包含非表数据,则需要将其转换为表(例如,通过向量化自由文本、添加 JSON 列或使用支持多模态 dtype 的 DataFrame 库)。如果您无法将数据转换为表格式,则可能需要考虑除 Delta Lake 之外的其他技术。
让我们仔细看看这是如何工作的。
什么是数据湖?
数据湖是中央存储库,用于存储和处理您的原始数据,无论其大小或格式如何。“数据湖”一词来源于湖泊(“中央存储库”)的类比,其中有许多不同的河流(“数据流”)汇入。这些数据流都汇集到一个地方,并且共存而没有严格的分离或预定义的结构。
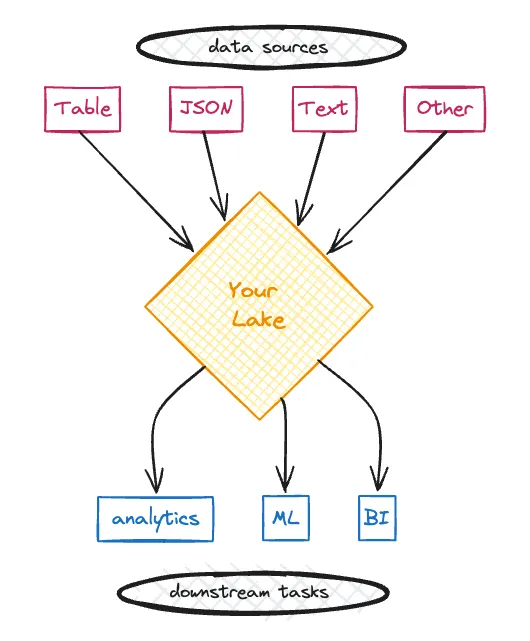
数据湖的兴起是对数据仓库的一种反应,数据仓库要求您的数据采用特定的结构化格式。数据仓库针对您预先定义的特定查询进行了性能优化。它们以牺牲灵活性为代价为您提供了速度。它们通常还将数据存储为专有格式,因此您面临供应商锁定的风险。
相反,数据湖针对灵活性进行了优化。您可以以任何您喜欢的格式存储数据,并对数据运行许多不同类型的分析,而无需昂贵的预处理。
数据湖为您提供
- 从多个来源自由移动数据,以其原始格式,可能实时
- 编目和索引,让您全面了解数据湖中包含的数据类型
- 不同团队和角色访问数据以用于下游用途。
- 执行数据科学和机器学习分析的能力。
包含 Parquet 文件的本地目录可以被视为数据湖。或者包含许多不同文件类型(数据格式为表、JSON、自由文本、图像、视频等)的 S3 存储桶。
这是磁盘上 Parquet 文件数据湖的外观
```
your_data_lake/
file1.parquet
file2.parquet
…
fileN.parquet
```数据湖 —> 数据沼泽
数据湖很棒,因为它们提供了极大的灵活性和廉价的存储。来自多个来源的多种数据格式都可以有效地存储在一个位置。
但是当您的数据扩展时,这种灵活性可能会成为一个问题。跟踪文件版本、数据模式或回滚意外数据操作可能很困难。数据湖也很容易损坏,这使得它们在没有手动清理的情况下无法读取。
您的数据湖很容易变成数据沼泽。这将导致不正确的分析以及需要使用下游数据的开发人员付出昂贵的停机时间。

什么是 Delta Lake?
Delta Lake 是一种用于大规模存储数据的开源表格式。它通过为您提供以下功能来提高常规数据湖的可靠性、性能和开发人员体验
- 用于可靠读写的 ACID 事务
- 通过文件跳过实现高性能查询优化
- 数据版本控制和时间旅行
- 模式强制和演进
- 灵活的数据操作,例如删除/重命名列、删除行和 DML 操作
Delta Lake 为您提供数据湖的灵活性和低存储成本,以及数据仓库的可靠性和性能。您可以在现有数据湖基础设施之上运行 Delta Lake。Delta Lake 表可用于构建数据湖仓架构,如本文所述。
Delta Lake 在底层将您的数据存储在 Parquet 文件中。Parquet 文件是数据湖流行的文件格式。但是 Parquet 文件不具备事务日志、Z-ordering 和时间旅行等功能。
Delta Lake 通过以下方式使您现有的 Parquet 数据湖更可靠、性能更高
- 将所有元数据存储在单独的事务日志中
- 在此事务日志中跟踪您数据的所有更改
- 组织您的数据以实现最大查询性能
这是磁盘上 Delta Lake 目录的样子
```
your_delta_table/ <-- this is the top-level table directory
_delta_log <-- this is the transaction log which tracks
00.json all the changes to your data
01.json
…
n.json
file1.parquet <-- these are your Delta table partitions,
file2.parquet ordered for maximum query performance
…
fileN.parquet
```让我们仔细看看上面提到的每个 Delta Lake 功能。
Delta Lake vs 数据湖:ACID 事务
Delta Lake 支持 ACID(原子性、一致性、隔离性和持久性)事务。ACID 事务使您的数据写入更可靠,因此操作不会损坏您的表。“事务”是指任何改变表状态的写入操作。
ACID 事务为您提供 4 个重要的保证
- 每个数据事务都被视为一个不可分割的单元。要么整个事务完成,要么完全失败,并且不更改任何数据。这解决了失败的部分写入问题。(原子性)
- 在每个事务之前和之后,您的数据库都处于有效(未损坏)状态。如果事务将破坏任何预定义约束,则整个事务将被拒绝并且不会完成。这解决了表损坏问题。(一致性)
- 并发进程相互隔离地发生,并且不能访问彼此的中间状态。这解决了跨多个服务器或进程的文件或数据版本冲突问题。(隔离性)
- 一旦事务完成,即使发生系统故障或断电,更改也保证永远不会丢失。所做的更改存储在非易失性存储中。这解决了意外数据丢失的问题。(持久性)
数据湖不提供任何这些保证。
例如,假设您正在向现有的 Parquet 文件数据湖写入大量数据。如果您的集群在操作期间崩溃,您的数据湖中可能会留下部分写入的 Parquet 文件。这些部分文件将中断下游读取。要解决此问题,您需要识别所有损坏的文件并删除它们。然后您需要重新运行操作,并希望您的集群不会再次崩溃。这不好玩。
使用 ACID 事务不可能发生这种情况:整个写入操作将失败,您可以自由重试,而无需处理损坏的表。
让我们从性能方面看看 Delta Lake 与数据湖的比较。
Delta Lake vs 数据湖:性能
Delta Lake 使您的查询比常规数据湖运行得更快。
Delta Lake 通过以下方式优化您的查询
- 将文件路径存储在单独的事务日志中
- 在事务日志中存储元数据
- 通过文件跳过优先处理部分读取
- 将相似数据共同放置以实现更好的文件跳过
Delta Lake vs 数据湖:文件列表
要从 Parquet 数据湖读取数据,您首先必须列出所有文件。文件列表操作可能很慢且开销大,尤其是在云中。这是因为云文件系统使用键值存储,其列表操作比 UNIX 文件系统慢。
Delta Lake 将所有底层 Parquet 文件的路径存储在事务日志中。这是一个单独的文件,不需要昂贵的列表操作。您拥有的文件越多,使用 Delta Lake 读取数据的速度将比常规 Parquet 文件快。
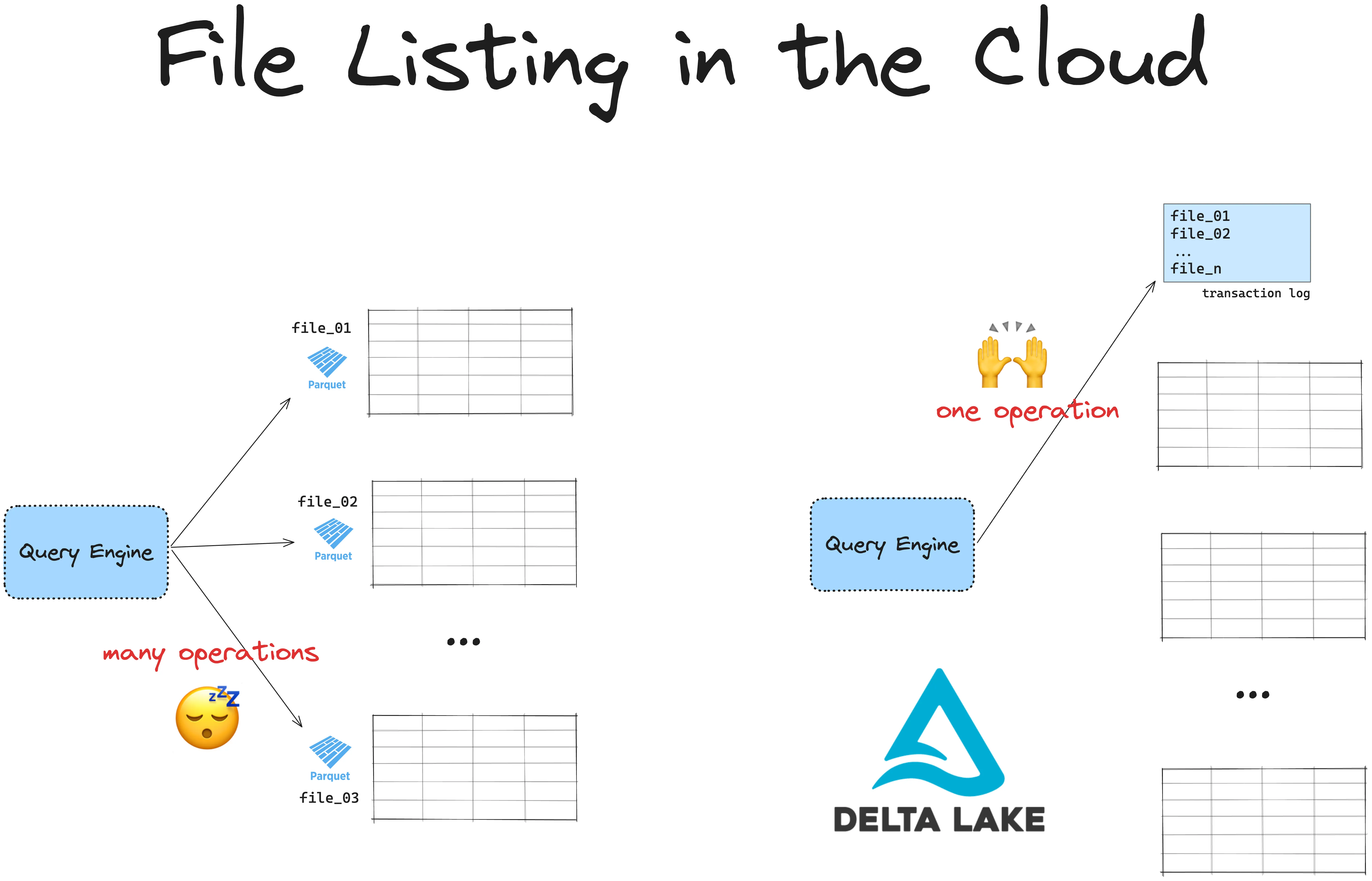
Delta Lake vs 数据湖:元数据
常规 Parquet 文件将有关列值的元数据存储在每个文件的页脚中。此元数据包含每个行组的列的最小/最大值。这意味着当您想要读取数据湖的元数据时,您必须从每个单独的 Parquet 文件中读取元数据。这需要获取每个文件并抓取页脚元数据,当您拥有大量 Parquet 文件时,这会很慢。
Delta Lake 在文件级别将元数据存储在单独的事务日志中。这意味着 Delta Lake 可以快速读取事务日志中的元数据,并使用它来告诉您的查询引擎跳过整个文件。这效率更高。
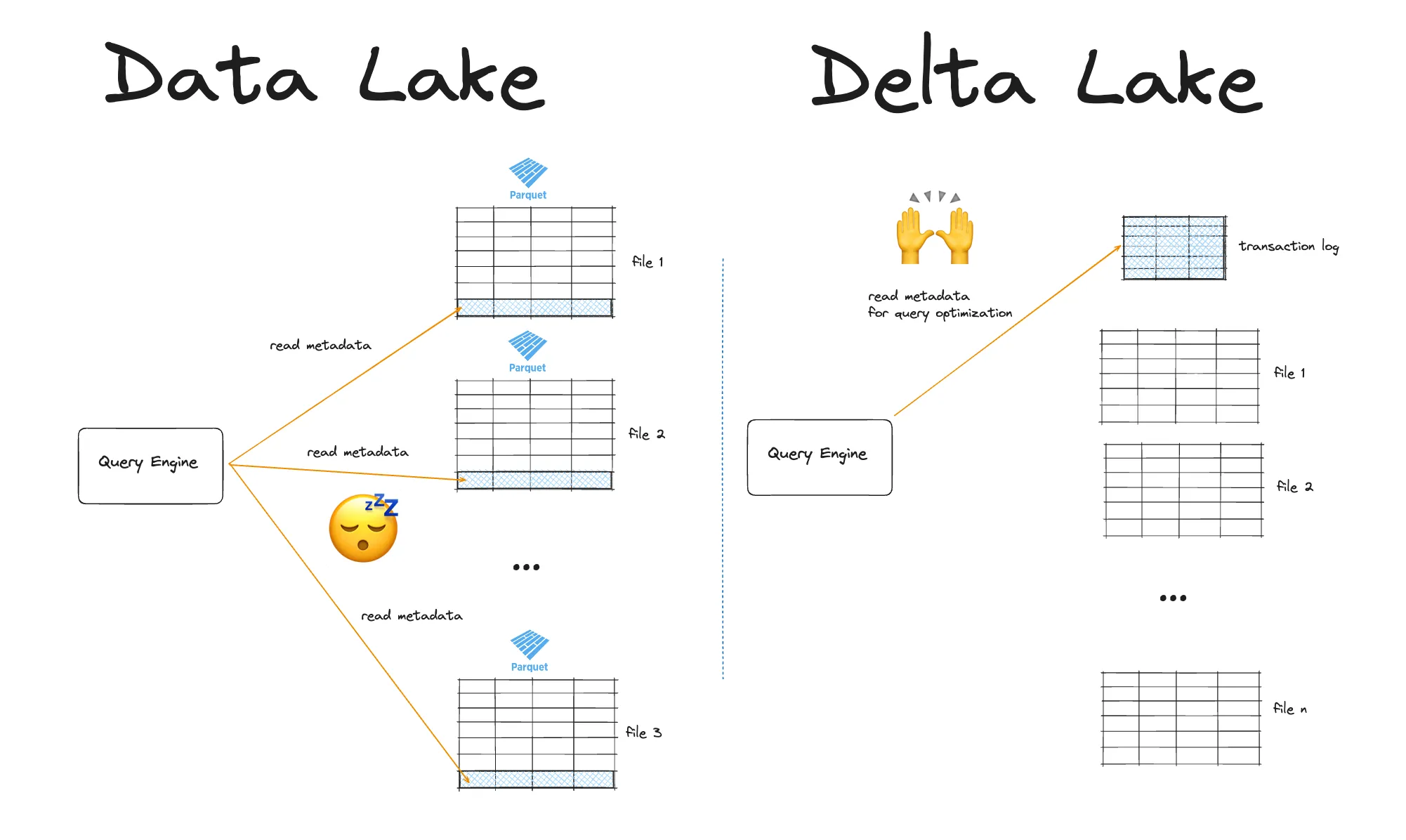
Delta Lake vs 数据湖:数据跳过
Delta Lake 可以通过识别与您的查询无关的数据来帮助您优化查询性能。这样,您的查询引擎可以跳过整个文件,避免不必要的读取数据。
Parquet 文件在元数据页脚中存储行组的列统计信息。这支持列剪枝和谓词下推等查询优化。
Delta Lake 更进一步。除了 Parquet 的功能之外,Delta Lake 还在单个事务日志中存储文件级别的元数据。这样,查询引擎可以通过单个网络请求找出哪些数据可以跳过。整个文件都可以通过这种方式跳过,当读取具有选择性过滤器的大表时,可以获得数量级的性能提升。
Delta Lake vs 数据湖:Z-Ordering
正如我们刚刚看到的,常规的 Parquet 数据湖已经针对列式查询优化和行组跳过进行了优化。Delta Lake 通过 Z-ordering 将相似数据存储在一起,从而更进一步。Z-ordering 在查询多个列时尤其重要。
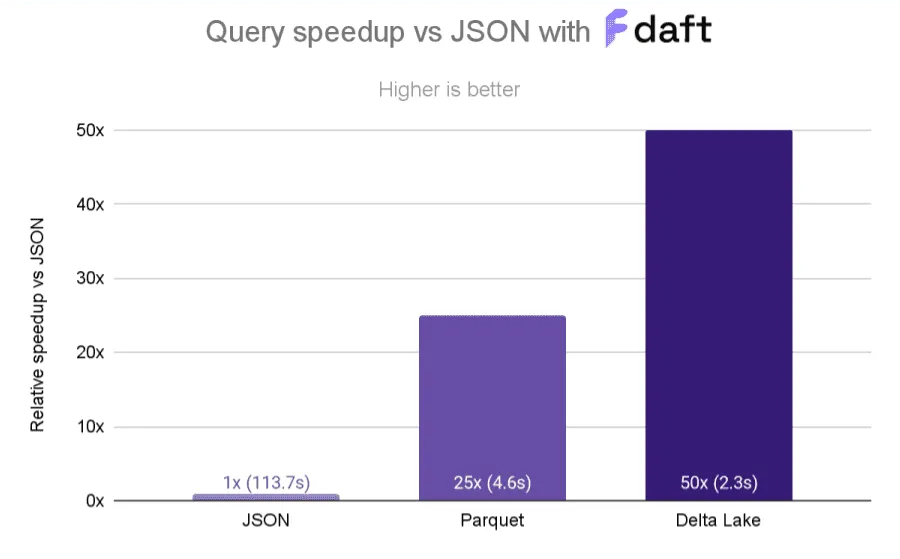
Z-ordering 可以为您带来巨大的性能提升,正如您在 Delta Lake 社区的这个出色示例中看到的那样。
Delta Lake 还支持通过 Hive 样式分区和 Liquid Clustering 将相似数据共同定位。
Delta Lake vs 数据湖:数据版本控制和时间旅行
数据湖不原生支持数据版本控制。当您的数据扩展并且难以跟踪特定数据片段何时被访问或转换时,这可能是一个问题。当您或同事意外更新数据时,这也是一个问题。常规数据湖不提供轻松恢复此更改的可能性。
Delta Lake 通过其事务日志支持数据版本控制。对数据所做的所有更改都记录在此日志中。这意味着您拥有所有关于数据转换的信息,以便于参考。
数据版本控制意味着 Delta Lake 也支持“时间旅行”功能。这意味着您可以在 Delta 表的不同版本之间轻松切换。通过这种方式,您可以回滚任何意外更改或记住以前的状态。
您可以像这样加载 Delta 表的特定版本:
spark.read.format("delta").option("versionAsOf", version).load("path/to/delta")在 Delta Lake 时间旅行 文章中阅读更多关于时间旅行的信息。
Delta Lake vs 数据湖:模式强制
在写入数据更新时,您通常希望确保新数据与现有数据的模式匹配。这称为“模式强制”,可确保数据集的一致性:我们刚才看到的 ACID 中的“C”。
根据您的数据湖基础设施,确保模式强制可能容易或难以设置。如果您的数据湖有元数据存储,您可以在那里定义模式强制约束。默认情况下,包含常规 Parquet 文件的数据湖不支持模式强制。这意味着很容易将具有不同模式的数据写入现有的 Parquet 数据湖。这将在尝试读取数据时导致下游问题。
Delta Lake 默认具有内置的模式强制。这可以防止您意外损坏数据。
让我们看看这是如何实现的。
我们将创建一个具有预定义模式的 Delta 表
```
df = spark.createDataFrame([("bob", 47), ("li", 23), ("leonard", 51)]).toDF(
"first_name", "age"
)
df.write.format("delta").save("tmp/fun_people")
```现在,让我们尝试将具有不同模式的数据写入此相同的 Delta 表
```
df = spark.createDataFrame([("frank", 68, "usa"), ("jordana", 26, "brasil")]).toDF(
"first_name", "age", "country"
)
df.write.format("delta").mode("append").save("tmp/fun_people")
```此操作将因 `AnalysisException` 而出错。Delta Lake 默认不允许您附加模式不匹配的数据。阅读 Delta Lake 模式强制帖子以了解更多信息。
Delta Lake vs 数据湖:模式演进
您并不总是知道最终数据集的确切模式。输入数据可能会随时间变化,或者您可能希望添加新列以进行分析。
当您需要更大的模式灵活性时,Delta Lake 也支持模式演进。
要更新 Delta 表的模式,您可以使用 `mergeSchema` 选项写入数据。让我们为我们刚刚看到的示例尝试一下
```
df.write.option("mergeSchema", "true").mode("append").format("delta").save(
"tmp/fun_people"
)
```这是写入后 Delta 表的内容
```
spark.read.format("delta").load("tmp/fun_people").show()
+----------+---+-------+
|first_name|age|country|
+----------+---+-------+
| jordana| 26| brasil| # new
| frank| 68| usa| # new
| leonard| 51| null|
| bob| 47| null|
| li| 23| null|
+----------+---+-------+
```Delta 表现在有三列。它以前只有两列。当添加新列时,新列没有任何数据的行将被标记为 `null`。
您还可以默认设置模式演进。在 Delta Lake 模式演进博客文章中阅读更多信息。
Delta Lake vs 数据湖:数据操作
许多基本数据操作在数据湖中困难或效率低下。数据湖中唯一容易的数据操作是追加数据。Delta Lake 通过使所有数据操作变得简单,为您提供了更好的开发人员体验。Delta Lake 支持数据操作,例如删除列、重命名列、删除行和选择性地覆盖匹配筛选条件的行。
常规 Parquet 文件是不可变的。为了对您的 Parquet 数据湖进行更改,您需要读取整个文件,进行更改,然后重写整个文件。这是一项昂贵的操作。不可变性是 Parquet 文件的功能:它可以防止您意外损坏数据。
Delta Lake 比常规 Parquet 文件提供更高的可靠性和更大的灵活性。正如我们已经看到的,通过事务日志实现的 ACID 事务为您提供了生产级别的可靠性保证。在 Delta Lake 中执行数据更新也更高效,因为更改会记录到事务日志中。这为您节省了读取和写入整个文件的计算和成本。
例如,您可以使用 Delta Lake replaceWhere 操作选择性地覆盖表中的特定行
```
(
df.write.format("delta")
.option("replaceWhere", "number > 2")
.mode("overwrite")
.save("tmp/my_data")
)
```Delta Lake 写入是“逻辑操作”。删除或覆盖操作只是更改事务日志中的标记,以指向新的行或列。实际数据不会被删除。这与使用“物理操作”的常规 Parquet 文件不同。当您从 Parquet 表中删除数据时,您实际上是从存储中删除它。
Delta Lake 使运行常见数据操作变得容易,并在底层高效执行它们。
我什么时候应该使用 Delta Lake?
让我们总结一下我们在这篇文章中学到的知识
数据湖是一项很好的技术,可以为您提供灵活且低成本的数据存储。如果符合以下条件,数据湖可能是一个不错的选择:
- 您的数据以多种格式从多个来源获取
- 您希望在许多不同的下游任务中使用此数据,例如分析、数据科学、机器学习等。
- 您希望灵活地对数据运行多种不同类型的查询,并且不想预先定义要向数据提出的问题
- 您不想被锁定在特定供应商的专有表格式中
数据湖也可能变得混乱,因为它们不提供可靠性保证。数据湖也并非总是经过优化以提供最快的查询性能。
Delta Lake 几乎总是比常规数据湖更可靠、更快、对开发人员更友好。Delta Lake 对您来说可能是一个不错的选择,因为
- Delta Lake 支持事务和模式强制,因此您的表损坏的可能性大大降低。
- Delta Lake 将文件元数据抽象为事务日志并支持 Z Ordering,因此您可以更快地运行查询
- Delta Lakes 使执行常见数据操作(如删除列、重命名列、删除行和 DML 操作)变得容易。
本文简要概述了 Delta Lake 与常规数据湖相比的主要功能。要深入了解,您可能需要查看以下帖子