Delta Lake Upsert
作者:Avril Aysha
本文将向您展示如何使用 Delta Lake 执行 Upsert 操作。
当您处理大规模生产数据时,通常需要更新大型数据集中的记录。由于您的数据量大且资源有限,您希望在不从头重新处理所有内容的情况下完成此操作。
Delta Lake upsert 允许您在一次操作中插入、更新或删除记录,而无需重写整个数据集。这使得保持数据最新和准确变得更容易、更经济。
在本文中,您将学习如何使用 Spark 和 delta-rs(无 Spark 依赖)在 Delta Lake 中执行 upsert。
Upsert 在以下情况中特别有用:
- 您需要定期对大型表进行少量更改
- 您正在数据仓库中实现缓慢变化的维度。
- 您希望通过一致且准确的数据确保单一事实来源。
让我们深入了解使用 Delta Lake 执行 upsert 的详细信息。
为什么在 Delta Lake 中使用 Upsert?
传统数据湖使用 Parquet 等不可变文件格式。不可变文件格式非常适合防止数据损坏。它们对于对大型数据集进行少量更改非常低效。
假设您有一个包含 5000 万行数据的数据集。现在您的一个数据点发生了变化(例如,有人更改了他们的地址或进行了购买),并且需要将其更新到主数据集中。您还需要插入一个新行。在存储为 Parquet 的数据集中,这将需要:(1) 重写所有 5000 万行,或者 (2) 将更新存储在许多小文件中,导致小文件问题。无论哪种方式,这都将是缓慢且昂贵的。
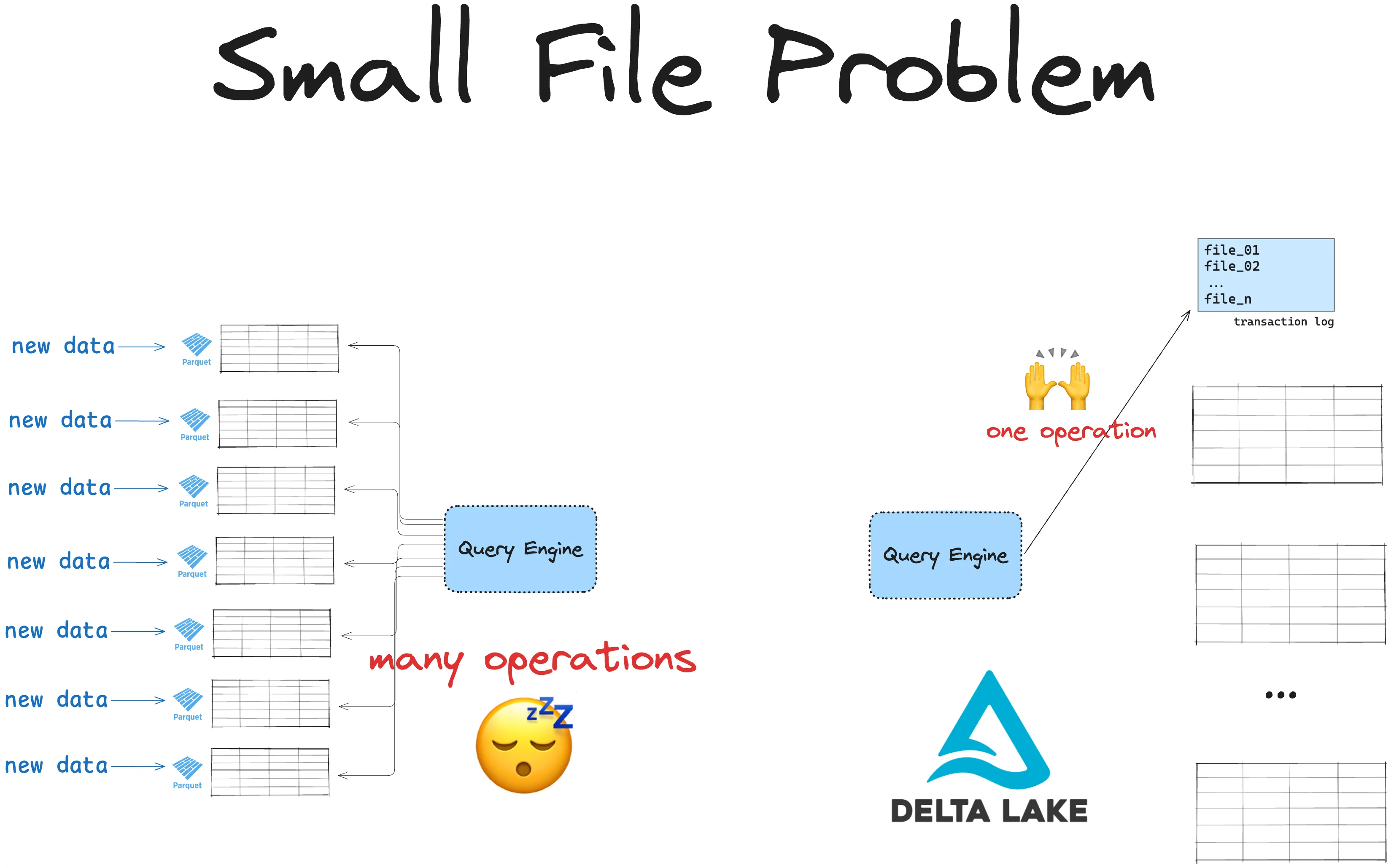
Delta Lake 允许您在一次小操作中完成此操作。Delta Lake 不会重写所有数据,而是将您的 upsert 操作注册为 Delta Lake 事务日志的简单更改。这既快速又简单。操作可以快速完成,您无需再次重写所有数据。您还可以在需要时轻松检查以前的版本。
让我们做一个快速的基准测试,看看它的实际效果。
Delta Lake 与 Parquet 在 Upsert 方面的基准测试
让我们首先读取一个相当大的存储为 Parquet 的数据集
# read a parquet file
df_parq = spark.read.format("parquet").load("tmp/data.parquet")并检查行数
> df_parq.count()
53311644
> df_parq.show(3)
+--------------------+--------------------+------+--------------------+
| id| names|emails| categories|
+--------------------+--------------------+------+--------------------+
|08ff39b22bae03010...|{Mount Boyd, null...| NULL| {mountain, null}|
|08ff39ba2b6909990...|{Erickson Glacier...| NULL|{landmark_and_his...|
|08ff39b209b20c1b0...|{Mount Cromie, nu...| NULL| {mountain, null}|
+--------------------+--------------------+------+--------------------+该数据集包含超过 5300 万行数据。每行都是一个注册地点,包含名称、电子邮件和相关类别。
让我们更新第一行的 emails 字段
from pyspark.sql.functions import col, when
df_parq = df_parq.withColumn(
"emails",
when(
df_parq.id == "08ff39b22bae03010337585ac81e0535",
"email@address.com"
).otherwise(df.emails)
)现在让我们向数据集中插入一个新行
# create new row
new_row = spark.createDataFrame([('1222355', 'Cool Place', 'another_email@address.com', "Recreational")], df_parq.columns)
# append to dataframe
df_parq = df_parq.union(new_row)Parquet 是一种不可变文件格式,因此我们无法覆盖或修改现有文件。存储这些更改的唯一方法是将整个 DataFrame 写入一个新的 Parquet 文件。
> %%time
> df_parq.write.format("parquet").save("tmp/new_data.parquet")
CPU times: user 9.09 ms, sys: 5.65 ms, total: 14.7 ms
Wall time: 28.8 s在配备 8 核的 M1 Macbook Pro 上,这花了超过 28 秒。对于单个 upsert 操作来说,这相当慢。
不仅如此,我们现在硬盘上还有两个大文件。
> ! du -h tmp/*
2.8G tmp/data.parquet
2.8G tmp/new_data.parquet让我们看看 Delta Lake 会是什么样子。
加载您的目标 Delta 表
target_table = DeltaTable.forPath(spark, "tmp/delta_table")
df = spark.read.format("delta").load("tmp/delta_table")然后让我们用一个更新和一个新记录添加我们的新数据
new_data = [
("08f3915108b7651b0395cf706df3eafb", "{Pateo do Sado, null, null}", "email@address.com", "{pizza_restaurant, [portuguese_restaurant, bar]}"), # Update
("1112222333355", "Cool Place", "another_email@address.com", "Recreational") # Insert
]
source_df = spark.createDataFrame(new_data, df.columns)现在让我们使用 MERGE 命令在一次操作中执行 upsert
%%time
# Perform the upsert (MERGE)
target_table.alias("target") \
.merge(
source_df.alias("source"),
"target.id = source.id"
) \
.whenMatchedUpdate(set={
"names": "source.names",
"emails": "source.emails"
}) \
.whenNotMatchedInsert(values={
"id": "source.id",
"names": "source.names",
"emails": "source.emails",
"categories": "source.categories"
}) \
.execute()
CPU times: user 4.77 ms, sys: 2.64 ms, total: 7.41 ms
Wall time: 13.6 s这要快得多。
让我们看看硬盘上的文件
! du -h tmp/*
0B tmp/delta_table/_delta_log/_commits
32K tmp/delta_table/_delta_log
3.1G tmp/delta_tableDelta Lake 不会不必要地复制数据。这效率更高。
Delta 表略大于硬盘上的 Parquet 数据。这是有道理的,因为我们存储了额外的元数据,这使得我们的查询更快,数据更不容易损坏。
让我们使用一个带有简单代码和数据的分步示例来分解这个过程。
Delta Lake Upsert 入门
upsert 是 MERGE 操作的一个特定实例。您有两个(或更多)数据集,您需要将一个数据集中的数据点合并到另一个数据集中:您需要更新现有行并插入新行。
Delta Lake 中的 MERGE 语句旨在处理 upsert。它允许您在单个查询中组合插入、更新和删除操作。
Delta Lake MERGE 操作的基本语法如下:
target_table.alias("target") \
.merge(source_table.alias("source"), "condition") \
.whenMatchedUpdate(set={"target_column": "source_column"}) \
.whenNotMatchedInsert(values={"target_column": "source_column"}) \
.execute()以下是分解:
target_table是您要执行 upsert 的表。source_table是包含新数据的表。condition指定两个表如何连接,通常使用唯一标识符。whenMatchedUpdate允许您更新target_table中与source_table中的行匹配的行。whenNotMatchedInsert允许您将source_table中没有匹配项的行插入到target_table中。
现在让我们看一个实际的代码示例。
示例:在 Delta Lake 中 Upsert 数据
假设您有一个 customer Delta 表,其中包含您需要根据 new_data DataFrame 中的传入数据保持更新的记录。
1. 定义您的目标 Delta 表
首先,确保您有一个 Delta 表作为目标。如果不存在,请创建它。
from delta.tables import DeltaTable
# Create a sample target Delta table
data = [(1, "Alice", "2023-01-01"), (2, "Bob", "2023-01-01")]
columns = ["customer_id", "name", "last_update"]
df = spark.createDataFrame(data, columns)
df.write.format("delta").mode("overwrite").save("/delta/customer")
target_table = DeltaTable.forPath(spark, "/delta/customer")2. 创建源 DataFrame(新数据)
这是您要 upsert 的新数据。
# new data with one update and one new record
new_data = [
(1, "Alice", "2023-02-01"), # Update: Alice's last_update changes
(3, "Charlie", "2023-02-01") # Insert: new record for Charlie
]
new_columns = ["customer_id", "name", "last_update"]
source_df = spark.createDataFrame(new_data, new_columns)3. 执行 MERGE 操作
设置好 target_table 和 source_df 后,您现在可以运行 MERGE 语句了。
# Perform the upsert (MERGE)
target_table.alias("target") \
.merge(
source_df.alias("source"),
"target.customer_id = source.customer_id"
) \
.whenMatchedUpdate(set={
"name": "source.name",
"last_update": "source.last_update"
}) \
.whenNotMatchedInsert(values={
"customer_id": "source.customer_id",
"name": "source.name",
"last_update": "source.last_update"
}) \
.execute()此操作会自动在 Delta Lake 事务日志中创建新事务。
4. 验证结果
执行 upsert 后,您可以查看更新后的客户 Delta 表。
> # read the updated Delta table to verify
> updated_df = spark.read.format("delta").load("/delta/customer")
> updated_df.show()
+-----------+-------+-----------+
|customer_id| name|last_update|
+-----------+-------+-----------+
| 1| Alice| 2023-02-01|
| 3|Charlie| 2023-02-01|
| 2| Bob| 2023-01-01|
+-----------+-------+-----------+结果显示 Alice 的 last_update 已更改,并且 Charlie 的记录作为新条目添加。干得好!
5. 使用时间旅行检查以前的版本
Delta Lake 的时间旅行功能允许您返回到数据的以前版本。
> # travel back to original version if needed
> original_df = spark.read.format("delta").option("versionAsOf", 0).load("tmp/customer")
> original_df.show()
+-----------+-----+-----------+
|customer_id| name|last_update|
+-----------+-----+-----------+
| 1|Alice| 2023-01-01|
| 2| Bob| 2023-01-01|
+-----------+-----+-----------+这使得在需要时恢复数据变得容易。请在 Delta Lake 时间旅行文章中阅读更多信息。
使用自定义 MERGE 条件的 Delta Lake Upsert
您可以使用条件逻辑在 Delta Lake 中自定义 upsert。这让您可以更好地控制更新和插入的发生方式。以下是一些自定义方式:
选择性更新:仅当满足特定条件时才应用更新。
.whenMatchedUpdate(
condition="source.last_update > target.last_update",
set={"name": "source.name",
"last_update": "source.last_update"}
)条件插入:根据特定标准插入记录。
.whenNotMatchedInsert(
condition="source.status = 'active'",
values={"customer_id": "source.customer_id", "name": "source.name",
"last_update": "source.last_update"}
)请在 Delta Lake 合并文章中阅读更多信息。
使用 delta-rs 的 Delta Lake Upsert
您无需使用 Spark 即可使用 Delta Lake 执行 upsert 操作。您也可以使用 PyArrow、pandas、Polars 和 Daft 等非 Spark 引擎。在这种情况下,您将使用 delta-rs:Delta Lake 的 Rust 实现。
以下是使用 delta-rs 在 Delta Lake 中执行 upsert 操作的示例:
import pyarrow as pa
from deltalake import DeltaTable, write_deltalake
target_data = pa.table({"x": [1, 2, 3], "y": [4, 5, 6]})
write_deltalake("tmp_table", target_data)
dt = DeltaTable("tmp_table")
source_data = pa.table({"x": [2, 3, 5], "y": [5, 8, 11]})
(
dt.merge(
source=source_data,
predicate="target.x = source.x",
source_alias="source",
target_alias="target")
.when_matched_update(
updates={"x": "source.x", "y":"source.y"})
.when_not_matched_insert(
updates={"x": "source.x", "y":"source.y"})
.execute()
)请在 Delta Lake without Spark 文章中阅读有关在没有 Spark 依赖项的情况下使用 Delta Lake 的更多信息。
Delta Lake Upsert 的最佳实践
以下是在运行 Delta Lake upsert 操作时要考虑的一些最佳实践:
- 优化表性能:定期优化和清理您的 Delta 表,以提高性能并降低存储成本。请在 Delta Lake Optimize 文章中阅读更多信息。
- 启用 Z-Ordering 或 Liquid Clustering:对于大型表,请考虑对频繁查询的列进行 Z-Ordering 或启用 Liquid Clustering。这有助于缩短读取时间。请在 Delta Lake Z Order 文章中阅读更多信息。
- 在条件中使用主键:如果可能,请在
MERGE条件中使用唯一标识符,以防止意外重复。
使用 Delta Lake 进行 Upsert 操作
Delta Lake 使您可以轻松可靠且高效地执行 upsert。这使您可以在不担心数据损坏或性能瓶颈的情况下大规模管理数据湖中的增量更新。Delta Lake upsert 适用于批处理和流处理工作负载。