Delta Lake 优化
作者:Avril Aysha
本博客将向您展示如何优化 Delta Lake 表以减少小文件数量。
小文件可能是一个问题,因为它们会减慢查询读取速度。列出、打开和关闭许多小文件会产生昂贵的开销。这被称为“小文件问题”。您可以通过将数据合并成更大、更高效的文件来减少小文件问题的开销。
您可以通过 3 种方式优化 Delta Lake 表
- 离线优化 (Offline Optimize)
- 优化写入 (Optimized Write)
- 自动压缩 (Auto Compaction)
优化写入和自动压缩是 Delta Lake 的新功能,自 Delta 3.1.0 版本起可用。
为您的用例选择正确的优化方法可以在查询运行时节省大量计算资源。
小文件导致读取缓慢
假设您有一个包含许多小文件的 Delta Lake 表。对此数据集运行查询是可能的,但效率不高。
以下代码在包含 200 万行的 Delta 表上运行查询。Delta 表按education列分区,每个分区有 1440 个文件
%%time
df = spark.read.format("delta").load("test/delta_table_1440")
res = df.where(df.education == "10th").collect()
CPU times: user 175 ms, sys: 20.1 ms, total: 195 ms
Wall time: 16.1 s现在将其与在包含相同 200 万行数据但每个分区只有一个优化文件的 Delta 表上运行的相同查询进行比较
%%time
df = spark.read.format("delta").load("test/delta_table_1")
res = df.where(df.education == "10th").collect()
CPU times: user 156 ms, sys: 16 ms, total: 172 ms
Wall time: 4.62 s此查询运行速度快得多。
以优化数量的文件存储数据将提高您的开箱即用读取性能。优化数量的文件并不总是 1 个文件;根据数据集的大小,它可能不止 1 个。请阅读下面maxFileSize部分中的更多内容。
小文件问题的原因是什么?
小数据文件可能由以下原因造成:
- 用户错误:用户可以重新分区数据集并写入包含许多小文件的数据。
- 使用不可变文件:Parquet 等不可变文件格式无法被覆盖。这意味着对这些数据集的更新将创建新文件,可能导致小文件问题。
- 分区:在高基数列上对表进行分区可能导致磁盘分区包含许多小文件。
- 频繁的增量更新:频繁进行小更新的表可能包含许多小文件。每 2 分钟更新一次的表每周将生成 5040 个文件。
最好设计系统以避免创建许多小文件。
但有时这是不可避免的,例如当您处理像 Parquet 这样的不可变文件格式的表时,该表需要频繁更新。
让我们看看在这种情况下如何使用离线优化来优化 Delta Lake 表。
Delta Lake 优化:手动优化
假设您有一个 ETL 管道,每天摄取一些数据。数据被流式传输到每分钟更新一次的分区 Delta 表中。
这意味着您每天结束时每个分区将有 1440 个文件。
> # get n files per partition
> !ls test/delta_table/education\=10th/*.parquet | wc -l
1440正如我们上面看到的,在包含许多小文件的 Delta 表上运行查询效率不高。
您可以手动运行 Delta OPTIMIZE 命令来优化文件数量。这是通过将所有低效的小文件压缩成更大、更高效的读取文件来实现的。此操作后每个分区写入的默认文件大小为 1 GB。
您可以使用以下命令手动执行压缩:
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "test/delta_table")
deltaTable.optimize().executeCompaction()现在,对此优化后的 Delta 表的下游查询将更快。
在专门的小文件压缩文章中阅读更多内容。
Delta Lake 优化:优化写入
您不必手动运行 OPTIMIZE 命令。您还可以配置优化以在 Delta Table 上自动运行。这些自动优化包括:优化写入和自动压缩。
优化写入在执行之前将所有对同一分区的少量写入合并为一个写入命令。这在多个进程写入同一分区 Delta 表(即分布式写入操作)时非常有用。
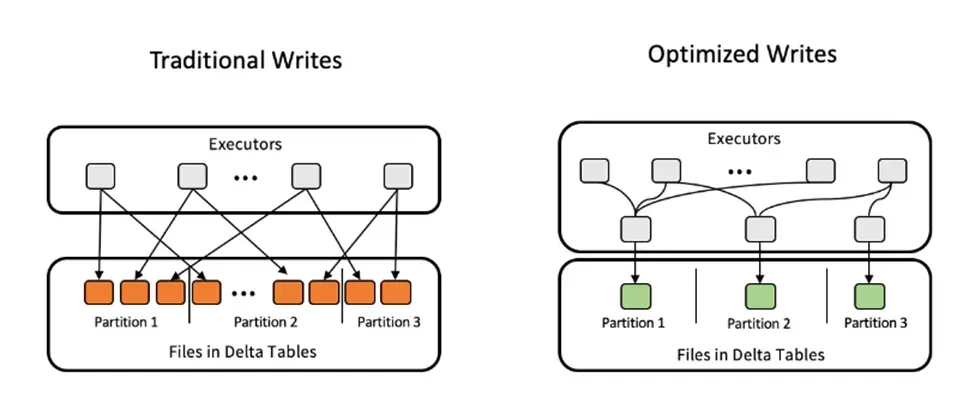
优化写入在将文件写入表之前使用数据混洗重新平衡数据。这样可以减少小文件数量。
您可以通过在 Delta Lake 写入器中设置optimizeWrite选项来启用优化写入
df.write.format("delta").option("optimizeWrite", "True").save("path/to/delta")您还可以通过以下方式为整个 Delta 表启用优化写入功能
- 通过设置
delta.autoOptimize.optimizeWrite表属性。 - 通过设置
spark.databricks.delta.optimizeWrite.enabledSQL 配置,为整个 Spark SQL 会话启用。
优化写入执行时间稍长,因为在写入数据之前会进行数据混洗。这就是此功能默认不启用的原因。
优化写入示例
我们来看一个例子。您可以在此笔记本中自行运行此代码。
启动一个具有 4 个工作节点的本地 Spark 集群,以模拟分布式写入设置
import pyspark
from delta import *
builder = pyspark.sql.SparkSession.builder.master("local[4]").appName("parallel") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = configure_spark_with_delta_pip(builder).getOrCreate()然后我们从包含 200 万行数据的数据集开始
df = spark.read.csv("data/census_2M.csv", header=True)重新分区此数据以模拟存在许多小文件的情况
df = df.repartition(1440)将数据写入 Delta 表。4 个本地进程中的每个进程都将并行写入许多分区
df.write.format("delta").partitionBy("education").save("delta/census_table_many/")让我们看看每个分区在磁盘上有多少个文件
> # get n files per partition
> !ls delta/census_table_many/education\=10th/*.parquet | wc -l
1440每个分区在磁盘上有 1440 个文件。
让我们在包含许多小文件的 Delta 表上运行查询
> df_small = spark.read.format("delta").load("delta/census_table_many")
> %%time
> df_10th = df_small.where(df_small.education == "10th").collect()
CPU times: user 175 ms, sys: 20.1 ms, total: 195 ms
Wall time: 16.1 s现在让我们使用优化写入来写入相同的数据。这将在写入操作*之前*执行数据混洗,并且应该避免小文件问题。
df.write.format("delta").partitionBy("education").option("optimizeWrite", "True").save("delta/census_table_optimized/")让我们看看每个分区在磁盘上有多少个文件
> # get n files per partition
> !ls delta/census_table_optimized/education\=10th/*.parquet | wc -l
1所有数据都已合并到每个分区的一个文件中。这个示例数据集很小(约 250MB),因此每个分区一个文件在这里是合理的。
现在让我们在此优化后的 Delta 表上运行查询
> df_opt = spark.read.format("delta").load("delta/census_table_optimized")
> %%time
> df_10th = df_opt.where(df_opt.education == "10th").collect()
CPU times: user 146 ms, sys: 30.3 ms, total: 177 ms
Wall time: 3.66 s这带来了 4.5 倍的性能提升。
Delta Lake 优化:自动压缩
优化写入对于分布式写入场景非常有用,即多个不同进程写入同一个 Delta 表。
但有时这不足以解决小文件问题,例如当您频繁地对表进行小更新时。在这种情况下,即使在优化写入之后,文件仍然很小。
自动压缩通过在每次写入操作后自动运行一个小的optimize命令来解决这个问题。小于特定阈值大小的文件中的数据会自动合并到一个更大的文件中。这样,您的下游查询就可以从更优化的文件大小中受益。
您可以为 Delta 表或整个 Spark 会话启用自动压缩
- 表属性:
delta.autoOptimize.autoCompact - SparkSession 设置:
spark.databricks.delta.autoCompact.enabled
自动压缩仅针对至少包含一定数量小文件的分区或表触发。触发自动压缩所需的最少文件数可以通过spark.databricks.delta.autoCompact.minNumFiles进行配置。
我们来看一个简单的例子。
我们将从上面使用的相同 200 万行数据集开始,并对其进行重新分区,以模拟每分钟执行一次写入的情况。
df = spark.read.csv("data/census_2M.csv", header=True)
df = df.repartition(1440)然后,我们为 Spark 会话启用自动压缩功能
spark.sql("SET spark.databricks.delta.autoCompact.enabled=true")现在将数据写入 Delta 表
df.write.format("delta").partitionBy("education").save("delta/census_table_compact/")然后执行查询
df_comp = spark.read.format("delta").load("delta/census_table_compact")
%%time
df_10th = df_comp.where(df_comp.education == "10th").collect()
CPU times: user 205 ms, sys: 39.2 ms, total: 244 ms
Wall time: 4.69 s再次,我们在优化 Delta 表后看到了显著的性能提升。
Delta Lake 优化:VACUUM
因为自动压缩在写入操作*之后*优化您的 Delta 表,所以磁盘上可能仍然有许多小文件。
> # get n files per partition
> !ls delta/census_table_compact/education\=10th/*.parquet | wc -l
1441在这种情况下,我们有 1440 个文件(每个分区一个)和一个包含所有数据的最终文件。
Delta Lake 已经迭代地将所有小写入合并成一个更大的文件。它还在事务日志中记录了最新文件的路径。下游数据读取将查看事务日志并仅访问最新、最大的文件。
但正如您所看到的,旧的、较小的文件仍然在磁盘上。这不影响您的读取性能,因为 Delta Lake 知道您只需要访问最新文件。但您可能仍然希望删除这些文件,例如为了节省存储成本。
您可以使用 VACUUM 命令删除这些旧文件。参数是您希望保留的前几个小时。
deltaTable.vacuum(0)VACUUM 命令会删除事务日志中不再主动引用的旧文件。默认情况下,VACUUM 仅影响超过默认保留期(7 天)的文件。
您可以使用以下方式覆盖此默认设置
spark.sql("SET spark.databricks.delta.retentionDurationCheck.enabled=false")在VACUUM 专用文章中阅读更多内容。
优化写入 vs 自动压缩
优化写入将对同一分区的许多小写入合并为一个更大的写入操作。它是在数据写入 Delta 表*之前*执行的优化。
自动压缩将许多小文件合并成更大、更高效的文件。它是在数据写入 Delta 表*之后*执行的优化。之后您可能需要执行 VACUUM 操作来清理剩余的小文件。
Delta Lake 优化 maxFileSize
您可以使用maxFileSize配置选项设置文件的最大文件大小
spark.databricks.delta.optimize.maxFileSize
1GB 文件的默认设置在大多数场景中效果最佳。您通常不需要调整此设置。
1 GB 的默认文件大小是根据多年的客户使用经验选择的,结果表明此文件大小在常见的计算实例上表现良好。
Delta Lake 优化:权衡
所有形式的优化都需要计算并花费时间。根据您的用例,一种方法可能比另一种更适合。
如果您有许多下游查询将从更快的读取性能中受益,那么运行优化通常是有意义的。
如果您需要尽可能低的写入延迟,Delta Lake 优化可能不适合您。
优化您的 Delta Lake 表
小文件可能导致下游查询缓慢。优化您的 Delta Lake 表以避免小文件问题是提高开箱即用性能的好方法。
您可以优化您的 Delta Lake 表
- 使用
optimize().executeCompaction()命令手动优化 - 在写入之前使用优化写入功能
- 在写入之后使用自动压缩功能
请查看GitHub 上的笔记本,自行运行示例代码。