在 Jupyter Notebook 中使用 Delta Lake
作者:Avril Aysha
本文将向您展示如何在 Jupyter Notebook 中使用 Delta Lake。
Jupyter Notebook 是 Python 中进行数据分析的绝佳工具。它们易于使用,并提供直观、交互式的界面来处理和可视化数据。
许多 Python 数据专业人员在 Jupyter Notebook 中使用 Delta Lake。这对于运行探索性数据分析、跨团队和组织协作以及需要交互式代码执行的任务来说是一个很好的设置。
本文将向您展示如何在 Jupyter Notebook 中使用 Delta Lake。
在 Jupyter Notebook 中使用 Delta Lake
在 Jupyter Notebook 中使用 Delta Lake 有两种方法
- 将 delta-spark 与 PySpark 配合使用
- 将 Python deltalake(又称 delta-rs)与其他查询引擎(如 pandas 或 polars)配合使用
如果您正在使用 Spark 查询引擎,请使用 delta-spark。如果您尚未使用 Spark,但您的工作负载足够大,可以从 Spark 的分布式计算中受益,那么您可能仍然希望使用 delta-spark。
如果您更熟悉 Python 数据处理引擎(如 pandas、polars、Dask、Daft 和 Datafusion),请使用 delta-rs。
接下来,让我们深入了解如何在 Jupyter Notebook 中使用 Delta Lake 和 Spark。
在 Jupyter Notebook 中使用 Delta Lake 和 Spark
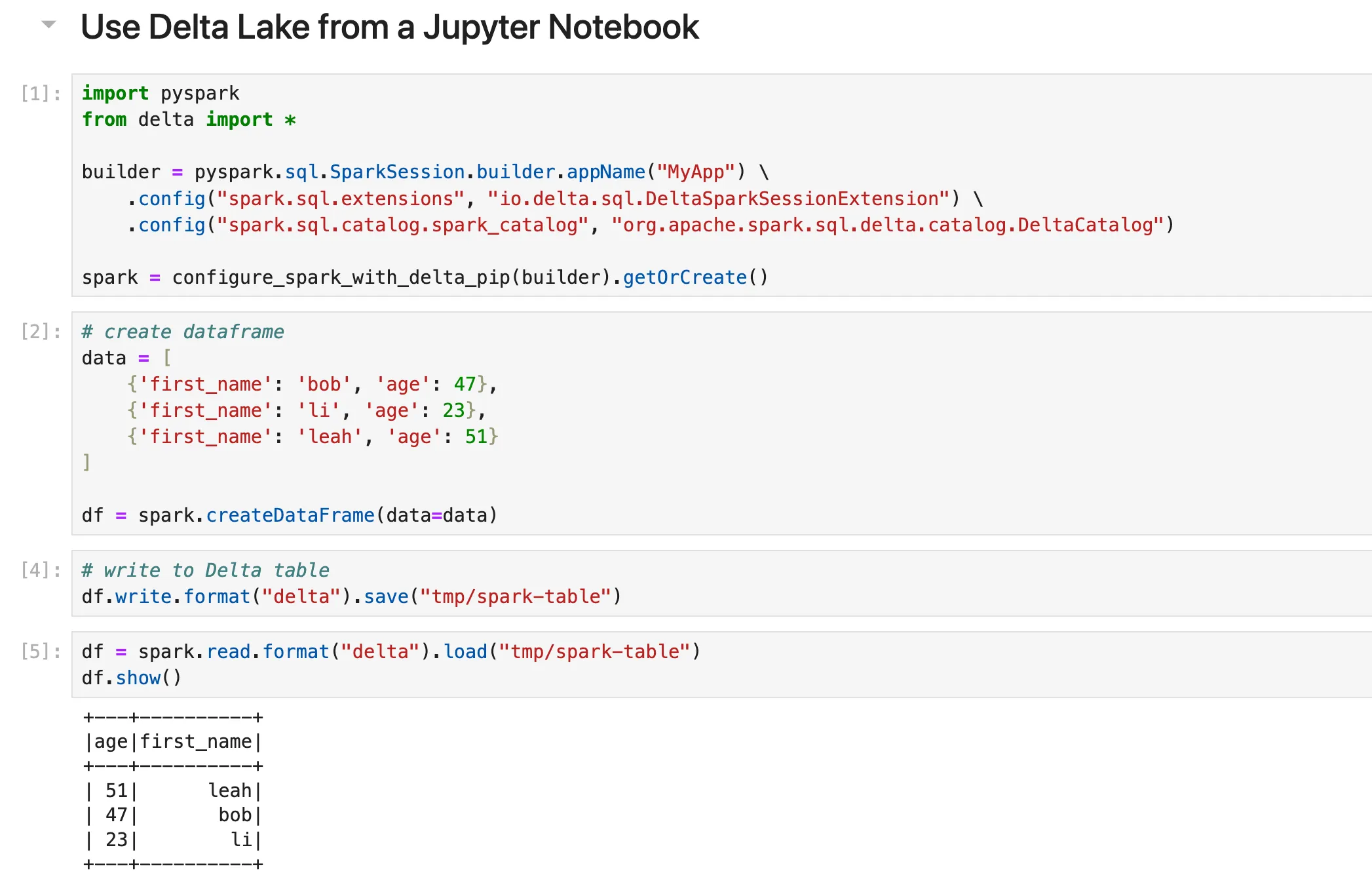
您可以在 Jupyter Notebook 中将 Delta Lake 与 PySpark 配合使用。
这是一个示例,展示了如何使用 PySpark 写入和读取 Delta Lake 表。
# create a dataframe
data = [
{'first_name': 'bob', 'age': 47},
{'first_name': 'li', 'age': 23},
{'first_name': 'leah', 'age': 51}
]
df = spark.createDataFrame(data=data)
# write data to delta table
df.write.format("delta").save("/tmp/spark-delta-table")
# read delta table
df = spark.read.format("delta").load("/tmp/spark-delta-table")
df.show()
+------------+---------------+
| age| first_name|
+------------+---------------+
|[47, 23, 51]|[bob, li, leah]|
| [33, 68]| [suh, anais]|
| [33, 68]| [suh, anais]|
+------------+---------------+当将 Delta Lake 与 PySpark 配合使用时,您需要确保使用的版本兼容。这是用户的一个常见痛点,但很容易解决。
有 3 种方法可以确保您拥有正确的 Delta Lake 和 PySpark 版本
- 创建固定正确版本的虚拟环境,例如使用 conda。
- 使用官方的 Delta Lake Docker 镜像。
- 查阅 兼容性矩阵 并手动安装正确的版本。
虚拟环境
确保拥有正确版本的 Delta-spark 和 PySpark 最简单的方法是使用 Conda 创建一个虚拟 Python 环境。Conda 是 Python 的包管理器。
要使用最新兼容版本的 PySpark 和 delta-spark 创建 Conda 环境,请按照以下步骤操作
-
创建一个 .yml 文件,其中包含以下内容并将其命名为
pyspark-350-delta-320.ymlname: pyspark-350-delta-320 channels: - conda-forge - defaults dependencies: - python=3.11 - ipykernel - jupyterlab - jupyterlab_code_formatter - isort - black - pyspark=3.5.0 - pip - pip: - delta-spark==3.2.0注意:这将创建一个包含最新 PySpark 和 Delta-spark 版本的环境。您可以使用 Delta Examples 仓库 中的 .yml 文件创建包含旧兼容版本的环境。
-
确保您已 安装 Conda。
-
打开终端窗口,使用以下命令从 .yml 文件创建新的 conda 虚拟环境
conda env create -f pyspark-350-delta-310.yml -
激活环境以使用它
conda activate pyspark-350-delta-310.yml -
通过从命令行运行
jupyter lab启动 Jupyter Notebook。您可以选择现有 Notebook,或从File > New > Notebook启动新 Notebook。 -
将 Delta Lake 与 PySpark 配合使用
让我们通过一个简单的示例来演示如何在 Jupyter Notebook 中将 Delta Lake 与 PySpark 配合使用。
首先导入 PySpark 和 Delta Lake 并初始化 Spark 会话
```
import pyspark
from delta import *
builder = (
pyspark.sql.SparkSession.builder.appName("MyApp")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config(
"spark.sql.catalog.spark_catalog",
"org.apache.spark.sql.delta.catalog.DeltaCatalog",
)
)
spark = configure_spark_with_delta_pip(builder).getOrCreate()
```接下来,让我们创建一些示例数据来处理
```
data = [
{"first_name": "bob", "age": 47},
{"first_name": "li", "age": 23},
{"first_name": "leah", "age": 51},
]
df = spark.createDataFrame(data=data)
```并将此 DataFrame 写入磁盘上的 Delta Lake 表
`df.write.format("delta").save("/tmp/spark-delta-table")`您可以像这样将此 Delta 表读回 Spark 会话
```
df = spark.read.format("delta").load("/tmp/spark-delta-table")
df.show()
+---+----------+
|age|first_name|
+---+----------+
| 51| leah|
| 47| bob|
| 23| li|
+---+----------+
```现在假设您想向此 Delta 表添加更多数据。您可以使用“append”写入模式
```
data2 = [
{'first_name': 'suh', 'age': 33},
{'first_name': 'anais', 'age': 68},
]
df2 = spark.createDataFrame(data=data2)
df2.write.format("delta").mode("append").save("/tmp/spark-delta-table/")
```通过读取 Delta 表进行确认
```
df = spark.read.format("delta").load("/tmp/spark-delta-table")
df.show()
+---+----------+
|age|first_name|
+---+----------+
| 68| anais|
| 51| leah|
| 33| suh|
| 47| bob|
| 23| li|
+---+----------+
```您还可以使用 versionAsOf 选项在 Delta Lake 表的不同版本之间进行时间旅行。下面我们读取版本 0,即追加操作之前
```
df = (
spark.read.format("delta")
.option("versionAsOf",0)
.load("/tmp/spark-delta-table")
)
df.show()
+---+----------+
|age|first_name|
+---+----------+
| 51| leah|
| 47| bob|
| 23| li|
+---+----------+
```干得好。
请注意,您还可以使用其他工具(如 poetry 或 venv)创建虚拟环境。
Delta Lake Docker 镜像
您还可以使用官方的 Delta Lake Docker 镜像 来将 Delta Lake 与 PySpark 配合使用。您需要确保您的机器上已 安装 Docker。
要使用此 Docker 镜像在 Jupyter Notebook 中使用 Delta Lake,请按照以下步骤构建一个已安装 Apache Spark 和 Delta Lake 的 Docker 镜像
-
将 delta-docker 仓库克隆到您的机器上
-
导航到克隆的文件夹
-
打开终端窗口
-
从克隆的仓库文件夹执行以下命令
docker build -t delta_quickstart -f Dockerfile_delta_quickstart -
从带有 JuypterLab 入口点的镜像运行容器
docker run --name delta_quickstart --rm -it -p 8888-8889:8888-8889 delta_quickstart
或者,您也可以从 Delta Lake DockerHub 下载镜像
docker pull deltaio/delta-docker:latest用于标准 Linux dockerdocker pull deltaio/delta-docker:latest_arm64用于在您的 Mac M1 上优化运行此镜像
手动实现
运行 Delta Lake 与 PySpark 的最后一个选项是查看 Delta Lake 文档中的 兼容性矩阵。然后您可以手动安装兼容的 PySpark 和 Delta Lake 版本,例如使用 pip。
此方法适用于快速测试。不建议用于需要高可靠性和可重现 Notebook 的生产环境。
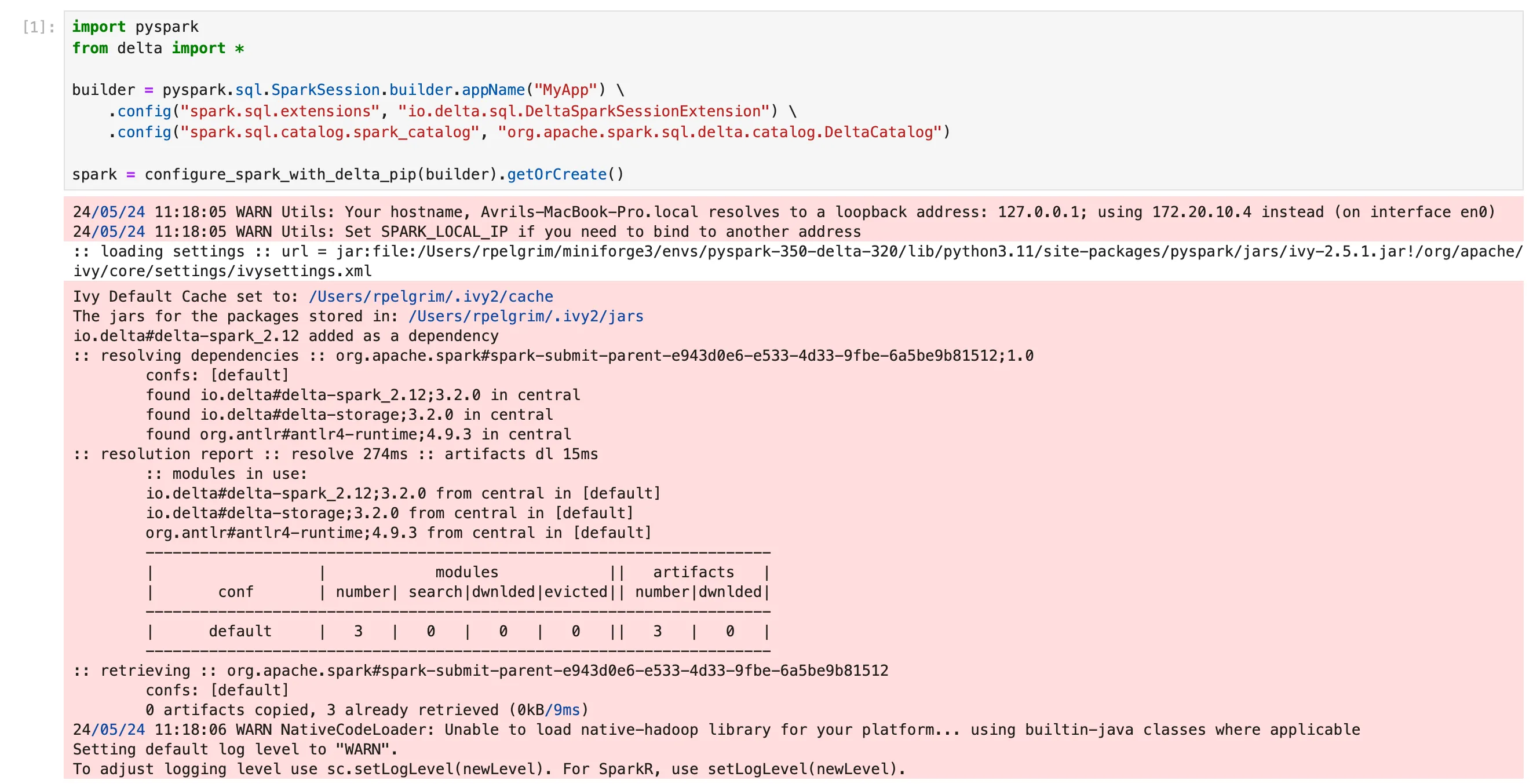
禁用日志输出
默认情况下,在 Jupyter Notebook 中运行 PySpark 可能会输出显示为红线的日志信息。这是由于 ipykernel 6.0.0 的更改,它将低级输出转发到您的 Notebook 显示。日志数据纯粹是信息性的,并不表示您的代码有任何问题。
这可能看起来像这样
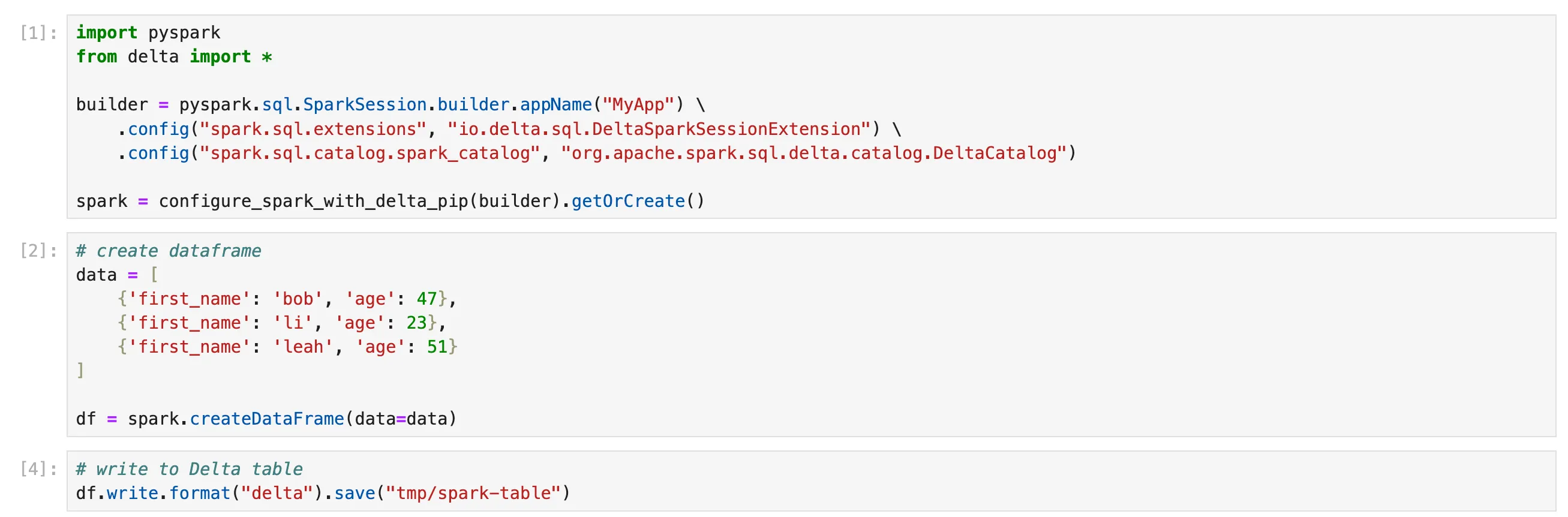
您可以使用 iPython 配置文件中的 capture fd output 标志禁用此日志记录。
为此
- 从终端窗口运行
ipython profile create - 将以下行添加到您的
~/.ipython/profile_default/ipython_config.py文件中:c.IPKernelApp.capture_fd_output = False - 重要提示:清除浏览器缓存
- 如果您的 Notebook 内核已在运行,请重新启动它
您的单元格输出现在应该看起来像这样
在 Jupyter Notebook 中使用 Delta Lake 和 delta-rs
您无需了解 Spark 即可使用 Delta Lake。您还可以从许多其他 Python 或 SQL 查询引擎中使用 Delta Lake,包括
- pandas
- polars
- Dask
- Daft
- Datafusion
- DuckDB
使用 delta-rs 在 Delta Lake 表上使用这些查询引擎运行分析。
运行 delta-rs 没有兼容性问题。要开始使用,只需 pip install deltalake 以及您喜欢的查询引擎即可。
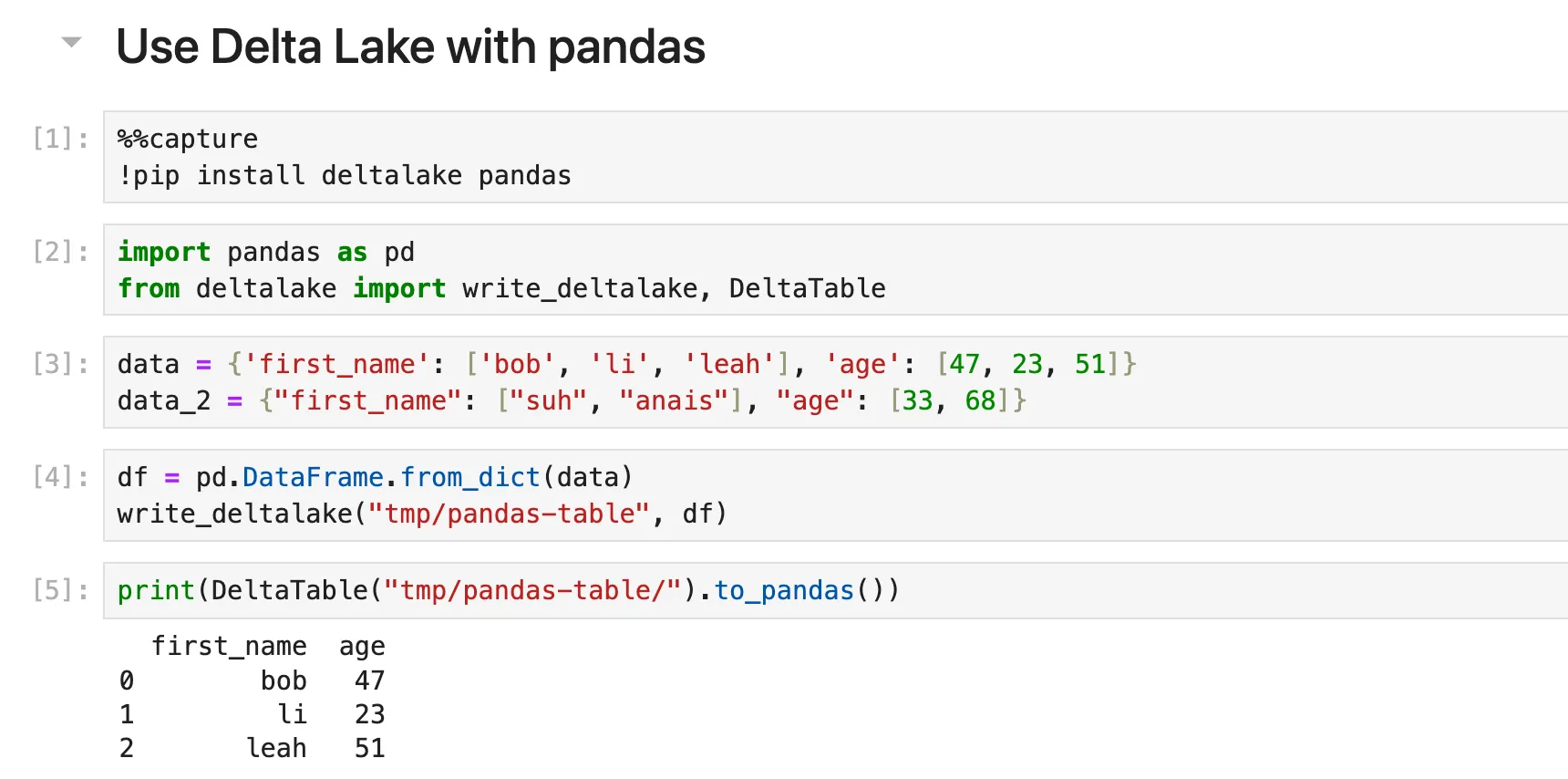
在 Jupyter Notebook 中使用 Delta Lake 和 pandas
让我们来看一个使用 pandas 的示例。
打开新 Notebook 并运行
`!pip install deltalake pandas`导入 pandas 和 deltalake
```
import pandas as pd
from deltalake import write_deltalake, DeltaTable
```定义数据字典
```
data = {'first_name': ['bob', 'li', 'leah'], 'age': [47, 23, 51]}
data_2 = {"first_name": ["suh", "anais"], "age": [33, 68]}
```使用第一个字典创建 DataFrame 并将其写入 Delta Lake 表
```
df = pd.DataFrame.from_dict(data)
write_deltalake("tmp/pandas-table", df)
```加载 Delta 表以检查结果
```
DeltaTable("tmp/pandas-table/").to_pandas()
first_name age
0 bob 47
1 li 23
2 leah 51
```让我们追加其余数据
```
df2 = pd.DataFrame(data_2)
write_deltalake("tmp/pandas-table", df2, mode="append")
```读回数据以仔细检查
```
DeltaTable("tmp/pandas-table/").to_pandas()
first_name age
0 bob 47
1 li 23
2 leah 51
3 suh 33
4 anais 68
```您可以使用 version 关键字时间旅行到以前的版本
```
DeltaTable("tmp/pandas-table/", version=0).to_pandas()
first_name age
0 bob 47
1 li 23
2 leah 51
```
有关将 Delta Lake 与其他查询引擎(如 polars、Dask、Daft 等)一起使用的更多信息,请参阅 Delta-rs 文档中的 集成页面。
使用虚拟环境
虽然 pip install 有效,但对于需要可靠性和可重现 Notebook 的生产级工作负载,不建议使用此方法。在这种情况下,最好定义一个虚拟环境。您可以使用 conda 和包含以下内容的 .yml 文件来做到这一点
```
name: deltalake-minimal
channels:
- conda-forge
- defaults
dependencies:
- python=3.11
- ipykernel
- pandas
- polars
- jupyterlab
- deltalake
```按照上面 PySpark 部分中的步骤,使用此 .yml 文件创建 Conda 环境,激活它,并运行 Jupyter Notebook。
从 Jupyter Notebook 运行 Delta Lake
从 Jupyter Notebook 运行 Delta Lake 有很多方法。
如果您正在使用 Spark,请使用带有 Conda 虚拟环境的 delta-spark,以确保 PySpark 和 delta-spark 版本兼容。或者,您也可以使用官方 Docker 镜像。
如果您没有使用 Spark,请使用 delta-rs 和您喜欢的查询引擎。您可以简单地 pip 安装这些库,但推荐的方法是构建虚拟环境。
我们欢迎对 Delta Examples 仓库做出贡献,提供展示 Delta Lake 功能的 Jupyter Notebook,这将使社区受益!