GCP 上的 Delta Lake
作者:Avril Aysha
本文将向您展示如何将 Delta Lake 与 Google Cloud Platform (GCP) 结合使用。
Delta Lake 是一个用于快速、可靠数据存储的开源框架。它支持 ACID 事务,能够高效地处理大规模元数据,优化查询性能并支持时间旅行。您可以使用 Delta Lake 构建高性能的湖仓架构。
GCP 是一个流行的云服务。许多组织使用其对象存储 Google Cloud Storage 来构建数据湖,例如使用 Parquet 文件。GCP 上的存储成本低廉,访问效率高,特别是对于批处理工作负载。GCS 上的数据湖不原生支持事务保证或 Delta Lake 提供的许多查询优化。
本文将向您展示如何从 GCP 读取 Delta 表并向 GCP 写入 Delta 表。我们将通过 Spark 和 Polars 的代码示例进行演示。
您将学到
- 为什么 Delta Lake 是 GCP 工作负载的绝佳选择
- 如何配置 Spark 会话以实现 Delta Lake 对 GCP 的正确访问
- 如何设置 Python 环境以实现 Delta Lake 对 GCP 的正确访问
让我们开始吧。
为什么 Delta Lake 非常适合 GCP
云对象存储系统在列出文件时速度较慢。当您处理大量数据时,这可能是一个大问题。Delta Lake 提高了您在这些对象存储中数据查询的效率。
与传统文件系统不同,云存储使用扁平命名空间。这意味着没有真正的目录。相反,目录是通过对象键上的前缀模拟的。因此,在列出文件时,系统必须扫描所有内容并按这些前缀进行筛选。
云存储还存在 API 速率限制,因此每次文件列表通常需要多次 API 调用。当您需要列出大量文件时,这可能会造成严重的瓶颈。
Delta Lake 通过将所有文件路径存储在事务日志中来避免这些问题。您的引擎无需列出文件,而可以在单个操作中快速访问相关文件的路径。这使得查询速度更快,效率更高。
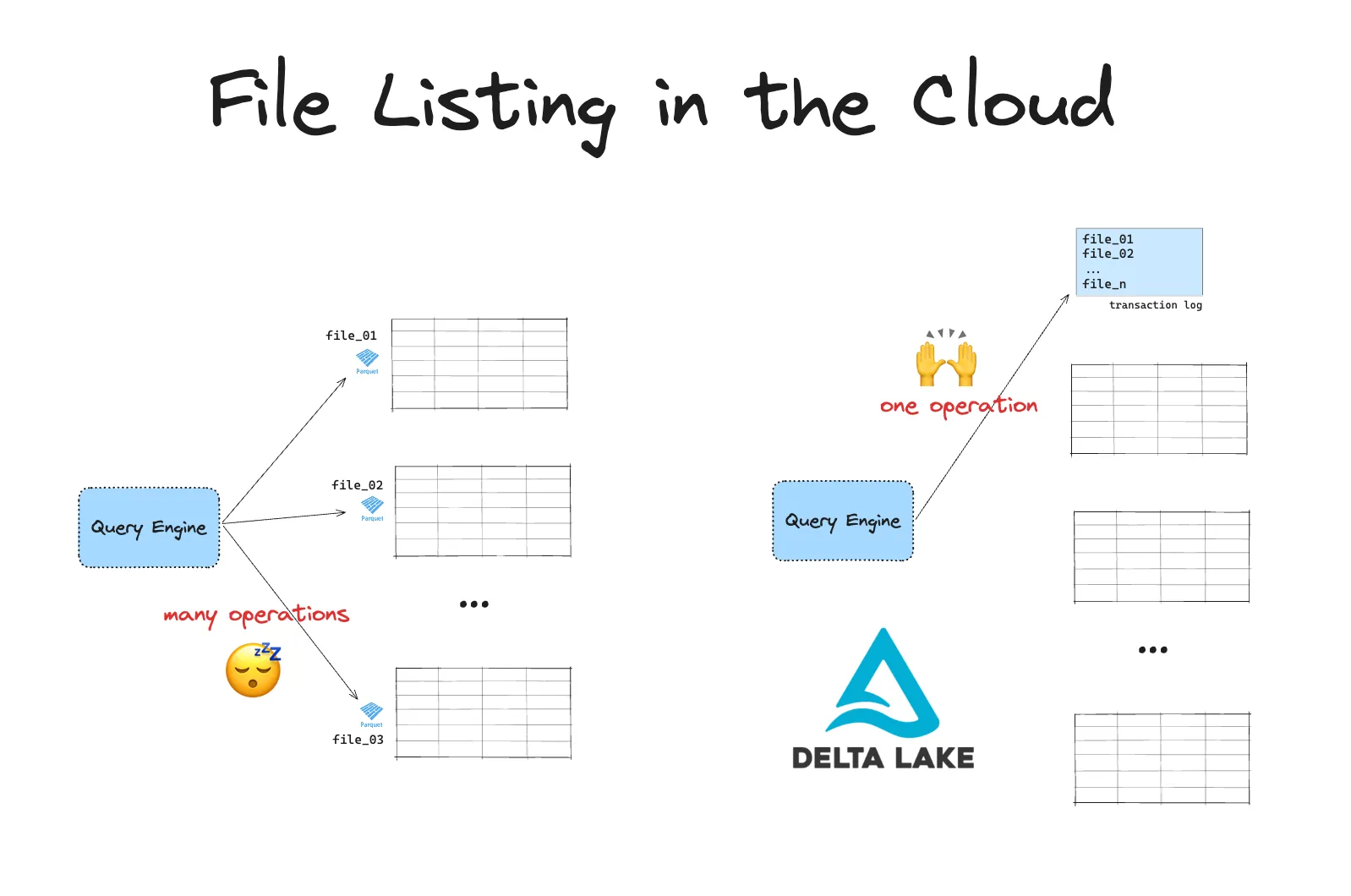
与 GCP 上的数据湖相比,使用 Delta Lake 构建湖仓架构具有更多优势。您可以在Delta Lake vs Data Lake博客中阅读更多相关信息。
如何在 GCP 上使用 Delta Lake
许多查询引擎都支持在 GCP 上读取和写入 Delta Lake。
例如,您可以使用 Spark 读取 Delta Lake 表,如下所示:
df = spark.read.format("delta").load(path/to/delta)您可以使用 Spark 将数据写入 Delta Lake 表,如下所示:
df.write.format("delta").save(path/to/delta)您也可以在没有 Spark 的情况下使用 Delta Lake。
一些查询引擎需要一些额外的配置步骤才能启动并运行 Delta Lake。以下两个部分将引导您了解如何在 Spark 和 Polars 等 Python 引擎上使用 Delta Lake。
首先,让我们正确设置 Google Cloud Storage 存储桶。
设置 Google Cloud Storage (GCS)
无论您使用哪种查询引擎,都需要以下内容
- Google Cloud 帐户:您需要访问 Google Cloud 项目。
- Google Cloud SDK:安装 Google Cloud SDK。
完成这些设置后,创建一个 Google Cloud Storage 存储桶。这将作为 Delta Lake 数据的存储位置。
- 前往 Google Cloud 控制台。
- 打开存储并选择存储桶。
- 点击创建存储桶并按照说明操作。为您的存储桶指定一个唯一的名称,选择一个位置,然后选择您的存储类别。
- 创建存储桶后,记下存储桶名称和位置。
确保为存储桶配置适当的权限。您需要授予查询引擎使用的服务帐户对该存储桶的读写权限。
现在,让我们看一个在 Spark 引擎上使用 Delta Lake 的示例。
如何在 Spark 上使用 Delta Lake
本文将演示使用本地 Spark 会话的代码。您也可以使用 Google Dataproc 或 Databricks 等完全托管的服务。
这是用户在未正确配置 Spark 会话时会看到的常见错误:
java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem not found这表明 Spark 未使用正确的 GoogleHadoopFileSystem 进行设置。如果您遇到此错误,您可能缺少 gcs-connector JAR 和/或未正确设置 spark.hadoop.fs.gs.impl 配置。
以下代码是启动正确配置的 Spark 会话的工作示例:
conf = (
pyspark.conf.SparkConf()
.setAppName("MyApp")
.set(
"spark.sql.catalog.spark_catalog",
"org.apache.spark.sql.delta.catalog.DeltaCatalog",
)
.set("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.set("spark.hadoop.fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
.set("spark.hadoop.google.cloud.auth.service.account.enable", "true")
.set("spark.hadoop.google.cloud.auth.service.account.json.keyfile", "/Users/rpelgrim/Desktop/gcs.json")
.set("spark.sql.shuffle.partitions", "4")
.set("spark.jars", "https://storage.googleapis.com/hadoop-lib/gcs/gcs-connector-hadoop3-latest.jar") \
.setMaster(
"local[*]"
) # replace the * with your desired number of cores. * to use all.
)
builder = pyspark.sql.SparkSession.builder.appName("MyApp").config(conf=conf)
spark = configure_spark_with_delta_pip(builder).getOrCreate()让我们逐步完成配置。
1. 配置身份验证
要使用 Spark 访问 GCS 存储桶,您需要使用 Google Cloud 服务帐户进行身份验证。为此,您需要生成一个服务帐户密钥。操作方法如下:
- 创建服务帐户:
在 Google Cloud 控制台中- 转到 IAM 和管理 > 服务帐户。
- 点击创建服务帐户。
- 为服务帐户分配
Storage Admin角色,以访问 GCS 存储桶。
- 为您的服务帐户生成密钥
- 在服务帐户下,点击管理密钥 > 添加密钥 > 创建新密钥。
- 选择 JSON 作为密钥类型,然后下载密钥。记下您存储它的路径。
稍后,我们将在配置 Spark 会话时使用服务帐户密钥的路径。
2. 安装 GCS 连接器 JAR
您需要再设置两个配置才能开始使用 GCP 上的 Delta Lake
- 下载并安装
gcs-connectorJAR 文件并将其添加到您的 Spark 会话 - 将 GCS 配置为文件系统。
我们将通过在 Spark 会话中设置以下配置来完成所有这些操作
.set("spark.jars", "https://storage.googleapis.com/hadoop-lib/gcs/gcs-connector-hadoop3-latest.jar")
.set("spark.hadoop.fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
.set("spark.hadoop.google.cloud.auth.service.account.enable", "true")
.set("spark.hadoop.google.cloud.auth.service.account.json.keyfile", "/path/to/key.json")将 /path/to/key.json 替换为您的服务帐户密钥 JSON 文件的路径。
运行此代码将启动一个 Spark 会话,该会话已正确配置为在 GCP 上使用 Delta Lake。
.set("spark.jars", …)添加正确的 gcs-connector JAR。.set("spark.hadoop.fs.gs.impl", …)设置正确的文件系统.set("spark.hadoop.google.cloud.auth…配置设置身份验证
3. 将数据写入 GCP 上的 Delta Lake
现在您已准备好开始将数据写入 GCP 上的 Delta Lake。
让我们创建一个示例 DataFrame 并将其作为 Delta 表写入您的 GCS 存储桶
data = spark.range(0, 5)
data.write.format("delta").save("gs://your-bucket-name/delta-table")将 your-bucket-name 替换为您的实际 GCS 存储桶名称。
4. 从 GCS 上的 Delta Lake 读取数据
让我们将数据读回以确认其按预期工作
df = spark.read.format("delta").load("gs://your-bucket-name/delta-table")
df.show()
+---+
| id|
+---+
| 3|
| 4|
| 1|
| 2|
| 0|
+---+这成功地直接从您的 GCS 存储桶读取了 Delta 表。
5. 使用 Delta Lake 执行更新和删除
Delta Lake 提供了用于处理更新、删除和合并的强大功能。让我们看几个示例。
更新:根据条件更新 Delta 表中的值。
from delta.tables import DeltaTable
deltaTable = DeltaTable.forPath(spark, "gs://your-bucket-name/delta-table")
# Update rows where id is less than 3
deltaTable.update("id < 3", {"id": "id + 10"})删除:删除符合特定条件的行。
# Delete rows where id is less than 5
deltaTable.delete("id < 5")合并:根据特定条件将新数据合并到您的 Delta 表中。
new_data = spark.range(0, 20)
deltaTable.alias("old").merge(
new_data.alias("new"),
"old.id = new.id"
).whenMatchedUpdate(set={"id": "new.id"}).whenNotMatchedInsert(values={"id": "new.id"}).execute()有关更多详细信息,请参阅Delta Lake 合并帖子。
6. 使用 Delta Lake 时间旅行
时间旅行是 Delta Lake 的一项强大功能,可让您访问数据的旧版本。操作方法如下。
您可以使用 versionAsOf 选项读取特定版本。第一个版本是 version 0。
# read a specific version of a Delta table
> df_version = spark.read.format("delta").option("versionAsOf", 1).load("gs://your-bucket-name/delta-table")
+---+
| id|
+---+
| 4|
| 11|
| 3|
| 12|
| 10|
+---+您还可以使用保存版本的时间戳引用版本
# read based on a timestamp
df_timestamp = spark.read.format("delta").option("timestampAsOf", "2023-01-01").load("gs://your-bucket-name/delta-table")将 "2023-01-01" 替换为您的目标日期。
有关更多信息,请参阅Delta Lake 时间旅行帖子。
如何在 GCP 上使用 Polars 结合 Delta Lake
您还可以将 Delta Lake 与 Polars 和其他 Python 查询引擎结合使用。
import polars as pl
df = pl.DataFrame(
{
"foo": [1, 2, 3, 4, 5],
"bar": [6, 7, 8, 9, 10],
"ham": ["a", "b", "c", "d", "e"],
}
)
table_path = "gs://avriiil/test-delta-polars"
df.write_delta(
table_path,
)让我们通过将其读回来确认这是否奏效
> df_read = pl.read_delta(table_path)
| | foo | bar | ham |
|---:|------:|------:|:------|
| 0 | 1 | 6 | a |
| 1 | 2 | 7 | b |
| 2 | 3 | 8 | c |
| 3 | 4 | 9 | d |
| 4 | 5 | 10 | e |您无需安装任何额外的依赖项即可使用 Polars 等使用 delta-rs 的引擎将 Delta 表读/写到 GCS。您确实需要正确配置 GCS 访问凭据。
应用默认凭据 (ADC) 是 GCS 用于根据应用程序环境自动查找凭据的策略。如果您在本地机器上工作并已设置 ADC,那么您可以直接从 GCS 读/写 Delta 表,而无需显式传递您的凭据。
或者,您可以显式地将 GCS 凭据传递给您的查询引擎。
对于 Polars,您将使用 storage_options 关键字执行此操作。这将把您的凭据转发到 Polars 在底层使用的对象存储库。有关更多信息,请阅读 Polars 文档和 对象存储文档。
有关在非 Spark 引擎中使用 Delta Lake 的更多示例,请参阅Delta Lake without Spark帖子。
Delta Lake 与 GCS 的锁定提供程序
Google Cloud Storage (GCS) 原生支持对象级别的原子操作,这可以防止文件创建过程中的冲突和损坏。这意味着您不需要额外的锁定提供程序来管理并发写入,这与 AWS S3 不同。
其工作原理如下:
- GCS 对对象写入强制执行原子性,这意味着每个文件创建或修改都被视为单个事务。这可以防止多个写入者同时创建或更新同一文件并导致数据损坏的情况。
- 当发出写入请求时,GCS 要么完全完成写入,要么失败,但它不会将文件置于不完整或部分写入状态。
这意味着在 GCS 中,Delta Lake 的 ACID 属性(包括隔离)得到完全支持,而无需单独的锁定提供程序。您可以依靠 Delta Lake 的事务日志和 GCS 原子写入机制来保证数据一致性。
在 GCP 上使用 Delta Lake
在本文中,您已在 Google Cloud Storage 上设置了 Delta Lake,并探讨了如何使用 Delta 表写入、读取和管理数据。通过将 Delta Lake 与 GCP 集成,您将获得一个强大的工具,用于构建可扩展、可靠的数据湖,并具有 Delta Lake 功能的灵活性。
您可以在 GCP 上读写 Delta Lake 表。将 Delta Lake 与 GCS 结合使用,可以通过避免耗时的文件列表操作来加速您的查询。
Delta Lake 适用于 GCP 上的许多查询引擎。Spark 会话需要一些额外的设置才能开始使用。
无论您使用哪种引擎,Delta Lake 都能为您带来这些核心优势:更快的查询、高效的元数据处理和可靠的事务。