用于 ETL 的 Delta Lake
作者:Avril Aysha
本文介绍了如何将 Delta Lake 用于 ETL 工作负载。
Delta Lake 具有一些出色的功能,可以使您的 ETL 工作负载更快、更可靠。这些功能对于生产和大规模的 ETL 工作负载尤其重要。
让我们看看 Delta Lake 如何帮助您更好地运行 ETL 工作负载。
什么是 ETL?
ETL 代表“提取-转换-加载”,是指数据项目,它Extract(提取)原始数据,Transform(转换)为更有用的格式,然后Load(加载)数据进行存储和进一步分析。
本文使用术语“ETL”来指代任何涉及提取、转换和加载数据的数据工作负载,无论您以何种顺序执行这些操作。大多数数据项目无论如何都不是完全线性的,请参阅下面的“ETL 与 ELT”部分。您可能需要多次在转换和加载之间来回切换。Delta Lake 使这变得简单可靠。
什么是 Delta Lake?
Delta Lake 是一种用于数据存储的开源表格式。Delta Lake 通过支持 ACID 事务、高性能查询优化、模式强制和演进、数据版本控制以及许多其他功能来改进数据存储。
Delta 表由两个主要组件组成
- 包含数据的 Parquet 文件,以及
- 存储有关事务的元数据的事务日志。
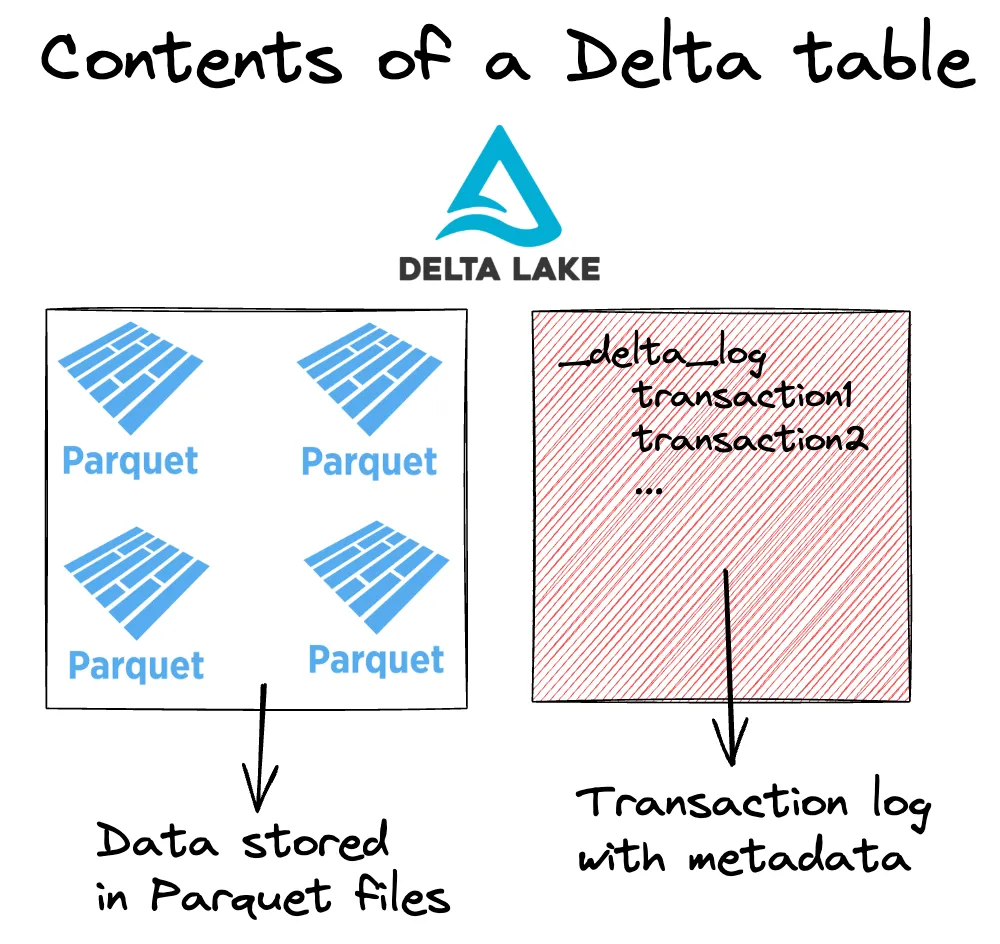
事务日志使 Delta Lake 能够优化您的查询,确保可靠的读写,并存储所有数据转换的记录。有关更多详细信息,请参阅 Delta Lake 与 Parquet 和 Delta Lake 与数据湖 文章。
Delta Lake 支持 ETL 和 ELT 工作负载。提取数据后,您可以使用 Delta Lake 存储原始数据,然后查询它进行转换 (ELT),或者您可以首先在内存中转换数据,然后将处理后的数据写入 Delta Lake 并向下游查询进行进一步分析 (ETL)。无论哪种方式,您都将受益于 Delta Lake 出色的优化和可靠性功能。
让我们看看 Delta Lake 成为 ETL 工作负载的绝佳选择的一些原因。
为什么我应该将 Delta Lake 用于 ETL?
Delta Lake 因其性能和可靠性而非常适合 ETL。
以下是一些将改进您的 ETL 工作负载的 Delta 功能
- 查询优化:数据访问经过优化,可实现快速数据检索和分析。
- 可伸缩性:Delta Lake 可以高效处理大量数据。
- 可靠性:ACID 事务确保数据正确且一致地加载。
- 模式强制和演进:Delta Lake 确保数据遵循定义的模式,并可根据需要演进。
- 时间旅行:所有数据转换都记录在事务日志中,可以随时访问旧版本的数据。
让我们仔细看看 Delta Lake 如何提高您的 ETL 查询性能。
用于 ETL 的 Delta Lake:查询性能
Delta Lake 具有许多优化查询性能的功能。
Delta Lake 通过以下方式加快您的数据转换速度
- 在事务日志中存储文件路径和元数据
- 通过文件跳过执行部分读取
- 将相似数据共同放置以实现更好的文件跳过
事务日志:Delta Lake 将所有文件路径、元数据和数据转换操作存储在专用的事务日志中。这使得文件列表更快,并支持部分数据读取。
文件跳过:Delta Lake 在单个事务日志中在文件级别存储元数据。这样,查询引擎可以通过单个网络请求找出哪些数据可以跳过。可以通过这种方式跳过整个文件。
共同放置相似数据:Delta Lake 可以使用 Z-排序 或 液体聚类 将相似数据存储在一起,以提高查询性能。
查询性能示例
假设您正在为分析部门的同事构建一个 BI 仪表板。您有一些刚刚摄取的原始数据,但实际上您的最终仪表板只需要这些数据的一个子集。在运行分析之前对原始数据运行选择性筛选查询是有意义的。
您可以使用这样的伪代码在内存中转换原始数据 (ETL)
# extract data
df = fetch_raw_data()
# transform
df_subset = df.where(df.col > value)您还可以使用 Delta Lake 作为转换前的中间存储层 (ELT)
# extract data
df = fetch_raw_data()
# load to Delta table
df.write.format("delta").save("delta/table")
# transform
df_subset = df.read.format("delta").load("delta/table").where(df.col > value)由于我们刚刚提到的功能,使用 Delta Lake 存储数据在转换之前可以显著提高性能。这将取决于您摄取的数据类型、数据规模以及您正在运行的转换类型。
如果多个团队需要访问相同的原始数据以进行不同类型的查询,那么通常将原始数据按原样加载并稍后进行转换是有意义的。在这种情况下,您和您的同事都可以受益于 Delta Lake 提供的出色性能优化。
让我们看一个代码示例。
假设您的 CSV 文件接收器中有 1600 万行新鲜数据。该数据集包含有关居住在美国的各种人员的信息。您的同事只对高收入人群(每年 >=5 万)的数据感兴趣。处理所有数据将是浪费的。
您可以从接收器中提取数据并在存储之前对其进行转换,例如这样
# read in 16M rows
df = spark.read.csv("data/census_16M.csv", header=True)
%%time
# subset relevant data
df.where(df.income == "=>50K").collect()
CPU times: user 5.52 ms, sys: 3.69 ms, total: 9.21 ms
Wall time: 21.2 s但是,将原始数据存储为在 `income` 列上分区的 Delta 表,然后对 Delta 表运行数据转换操作,受益于其查询优化,速度会更快
# read in 16M rows
df = spark.read.csv("data/census_16M.csv", header=True)
# load data to Delta table
df.write.format("delta").partitionBy("income").save("data/delta_census")
%%time
# query relevant data
df = spark.read.format("delta").load("data/delta_census")
df.where(df.income == "=>50K").collect()
CPU times: user 2.95 ms, sys: 1.99 ms, total: 4.94 ms
Wall time: 8.5 s这要快得多。该代码在具有 16GB 内存的 M1 Mac 上使用 4 个核心运行。该数据集是美国人口普查数据集的合成版本。
在 Delta Lake 与数据湖 文章中阅读更多关于 Delta Lake 性能提升的信息。
用于 ETL 的 Delta Lake:可靠性
Delta Lake 通过强制执行 ACID 事务使您的 ETL 工作负载更可靠。事务可以防止您的数据损坏或丢失。
不支持事务的数据存储格式(如 CSV 或 Parquet)很容易损坏。例如,如果您正在写入大量数据并且您的集群宕机,那么您的表中将有几个部分写入的文件。这些部分文件将导致下游读取操作崩溃。
Delta Lake 事务为您提供 4 个重要保证
- 不再有失败的部分写入:每个写入操作要么完全完成,要么完全失败,并且没有数据发生更改。
- 不再有损坏的表:如果事务将破坏任何预定义的约束,则整个事务将被拒绝,并且不会完成。
- 不再有冲突的数据版本:并发进程相互隔离发生,不能访问彼此的中间状态。
- 不再有意外数据丢失:即使发生系统故障或断电,所有数据更改也保证永远不会丢失。
Delta Lake 可靠性保证的一个重要部分是模式强制和演进。
用于 ETL 的 Delta Lake:模式强制和演进
为了防止意外数据损坏,Delta Lake 提供了模式强制。
如果新数据与现有表的模式不匹配,则无法将其写入 Delta 表。它将以 `AnalysisException` 错误终止。
例如,让我们创建一个具有简单模式的 Delta 表
df = spark.createDataFrame([("bob", 47), ("li", 23), ("leonard", 51)]).toDF(
"first_name", "age"
)
df.write.format("delta").save("data/toy_data")现在,让我们尝试将具有不同模式的数据写入此相同的 Delta 表
df = spark.createDataFrame([("frank", 68, "usa"), ("jordana", 26, "brasil")]).toDF(
"first_name", "age", "country"
)
df.write.format("delta").mode("append").save("data/toy_data")这是完整的错误
AnalysisException: [_LEGACY_ERROR_TEMP_DELTA_0007] A schema mismatch detected when writing to the Delta table
Table schema:
root
-- first_name: string (nullable = true)
-- age: long (nullable = true)
Data schema:
root
-- first_name: string (nullable = true)
-- age: long (nullable = true)
-- country: string (nullable = true)Delta Lake 默认不允许您附加具有不匹配模式的数据。阅读 Delta Lake 模式强制 文章以了解更多信息。
模式演进
当然,ETL 工作负载会随着时间的推移而演进。输入数据可能会更改,或者您的下游分析可能需要一个新列。当您需要更大的模式灵活性时,Delta Lake 还支持模式演进。
要更新 Delta 表的模式,您可以使用 `mergeSchema` 选项写入数据。让我们为我们刚刚看到的示例尝试一下
df.write.option("mergeSchema", "true").mode("append").format("delta").save(
"data/toy_data"
)这是写入后 Delta 表的内容
spark.read.format("delta").load("data/toy_data").show()
+----------+---+-------+
|first_name|age|country|
+----------+---+-------+
| jordana| 26| brasil| # new
| frank| 68| usa| # new
| leonard| 51| null|
| bob| 47| null|
| li| 23| null|
+----------+---+-------+Delta 表现在有三列。它以前只有两列。当添加新列时,新列没有任何数据的行将被标记为 null。
您还可以默认设置模式演进。在 Delta Lake 模式演进 博客文章中阅读更多内容。
用于 ETL 的 Delta Lake:时间旅行
人无完人。ETL 流水线也一样。
当发生错误时,您希望能够将数据回滚到错误发生之前的版本。手动执行此操作既痛苦又耗时。Delta Lake 通过支持时间旅行功能使这变得容易。
由于所有事务都存储在事务日志中,Delta Lake 始终可以回溯到表的早期状态。这与将 Git 存储库恢复到以前的提交没有什么不同。
让我们以上面的美国人口普查数据为例。
请记住,您已将数据存储为在 `income` 表上分区的 Delta 表。
# read in 16M rows of raw data
df= spark.read.csv("data/census_16M.csv", header=True)
# load data to partitioned Delta table
df.write.format("delta").partitionBy("income").save("data/delta_census")现在假设您的同事想要对 `age` 列运行一些查询。她读取您分区的 Delta 表,在 `age` 列上重新分区并覆盖该表。
# colleague reads in income-partitioned delta
df = spark.read.format("delta").load("data/delta_census")
# colleague does a repartition overwrite
df.write.format("delta").mode("overwrite").partitionBy("age").option("overwriteSchema", "true").save("data/delta_census")
# colleague runs query on new partition column
df = spark.read.format("delta").load("data/delta_census")
df.where(df.age == 25)现在您对 `income` 列的查询会变慢。您不希望查询变慢。
您可以做您的同事所做的事情:访问数据,在您感兴趣的列上重新分区并再次覆盖表。
# read in age-partitioned delta
df = spark.read.format("delta").load("data/delta_census")
# repartition overwrite again
df.write.format("delta").mode("overwrite").partitionBy("income").option("overwriteSchema", "true").save("data/delta_census")
# run query on new partition column
df = spark.read.format("delta").load("data/delta_census")
df.where(df.age == 25)但这需要再次读取和写入整个数据集。这既昂贵又不必要。
相反,您可以使用时间旅行访问数据的早期版本,该版本在 `income` 列上分区。
# read previous version
df = spark.read.format("delta").option("versionAsOf", 0).load("data/delta_census")
# run query on income partition column
df.where(df.income == "=>50K")在 Delta Lake 时间旅行 文章中阅读更多关于时间旅行的信息。
接下来,让我们看看 Delta Lake 的可伸缩性支持。
用于 ETL 的 Delta Lake:可伸缩性
随着更多数据的可用,ETL 工作负载通常会扩展。Delta Lake 支持小型和非常大的数据工作负载。
Delta Lake 通过以下方式使处理大型工作负载变得更容易、更快
- 对数据进行分区
- 对数据进行聚类
- 支持多种不同的查询引擎
分区
文件分区使得大规模处理数据更快。
在上面看到的查询优化示例中,我们使用了一种智能分区策略来使查询运行得更快。当您在某个列上对表进行分区时,Delta Lake 会将具有相同列值的所有记录存储在同一个文件中。这样,当不需要某些列值时,它可以跳过整个文件。
分区在并行查询引擎中尤其高效。在这种情况下,每个进程(或“工作器”)都可以并行读取其自己的分区。这可以加快您的查询速度,并让您在更短的时间内处理更多数据。
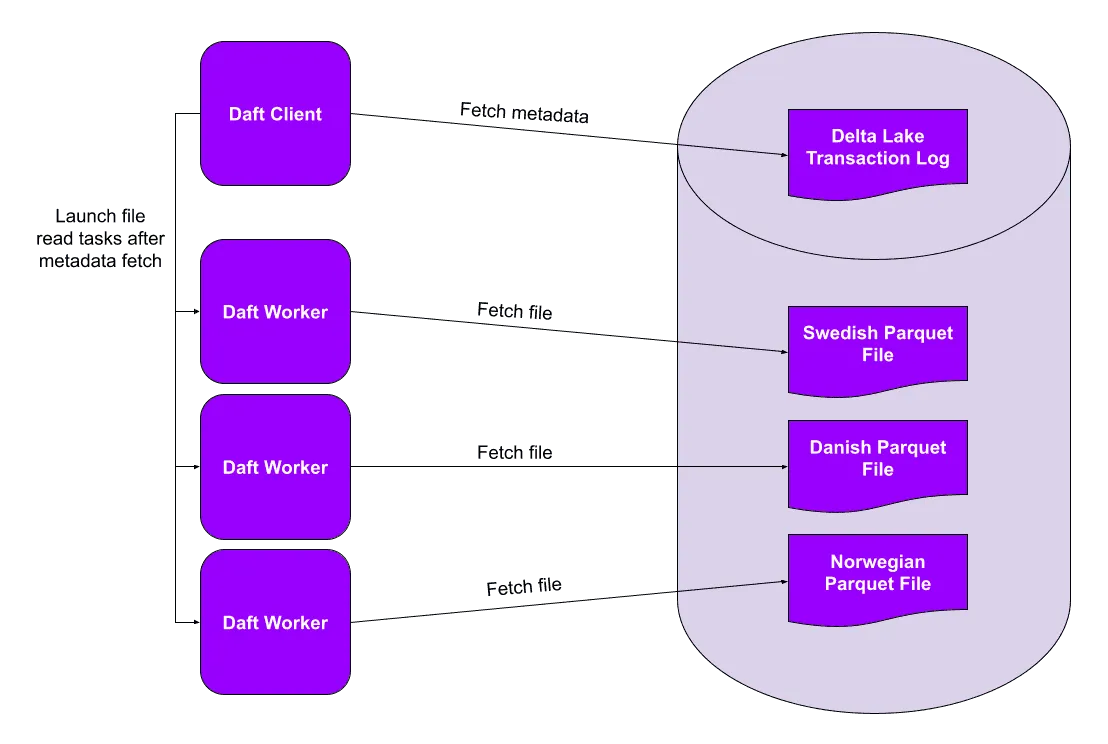
上图取自 Delta Lake 与 Daft 博客文章,但同样的优势适用于任何支持并行处理的查询引擎,例如 Spark、Polars、Dask、Daft 等。
数据聚类
Delta Lake 允许您通过 液体聚类、Z-排序 和 Hive 风格分区 将相似数据存储在一起。液体聚类是三种技术中最新的、性能最好的。
如果出现以下情况,您的 ETL 工作负载可能会受益于聚类
- 您经常需要按高基数列进行筛选。
- 您的数据在数据分布上存在显著偏差。
- 您的表增长迅速,需要维护和调优工作。
- 您的数据访问模式随时间变化。
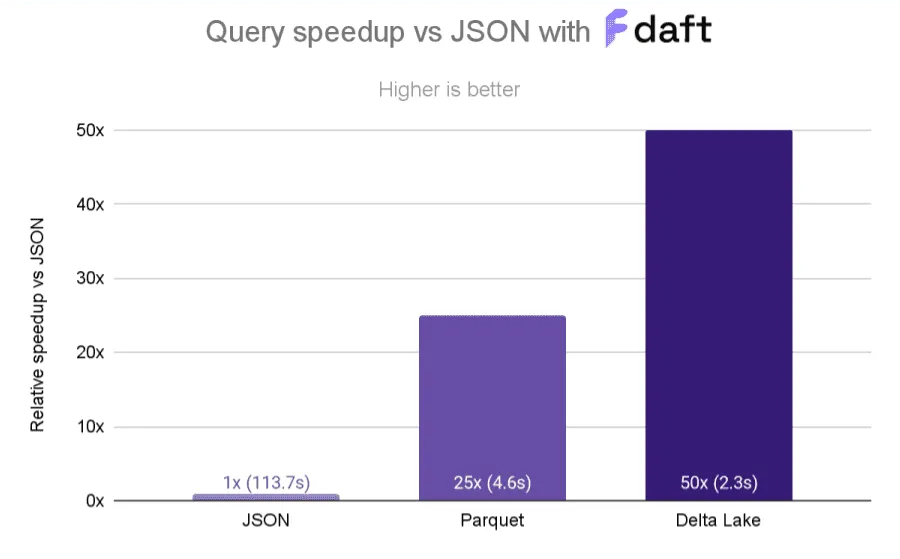
当您查询多个列时,Z-排序尤为重要。Z-排序可以为您带来不错的性能提升,您可以在 Delta Lake 社区的 这个很棒的示例 中看到。下图显示了 Z-有序 Delta 表与 Parquet 和 JSON 的查询性能加速。
查询引擎支持
Delta Lake 使得与各种不同的查询引擎协同工作变得容易。
您可能首先使用像 Polars 这样的单节点处理库在本地工作
# load data
df = pl.DataFrame(data)
# perform some data operations
...
# write to delta table
df.write_delta("data/delta_table")当您的数据量增加时,您可以切换到像 Spark 这样的分布式查询引擎
# load delta table created with polars
df = spark.read.format("delta").load("data/delta_table")
# join to much larger dataset
big_df = df.join(new_df, …)
# run big data operations
…
# write to delta table
big_df.write.format("delta").mode("append").option("overwriteSchema", "True").save("data/delta_table")Delta Lake 与许多查询引擎具有良好的互操作性。有关更多示例,请查看 Delta Lake 不使用 Spark 文章。
ETL 与 ELT
关于 ETL 和 ELT 工作负载之间的区别存在很多争论和一些困惑。这两个术语之间的区别在于选择何时转换数据:在将其加载到存储之前还是之后。
- ETL 工作负载在将数据加载到目标系统之前对其进行转换。
- ELT 工作负载首先将原始数据加载到存储中,然后对其进行转换。
“ETL”一词起源于传统数据仓库。这些仓库要求数据在加载到存储之前采用非常特定的格式:您需要将原始、杂乱的数据转换为仓库可以接受的格式,然后才能使用它。
现代数据湖和数据湖仓已经改变了这一点。这些技术允许您存储原始数据,而无需严格的专有格式要求。这意味着您可以按原样加载原始数据,然后稍后进行转换(如果您愿意)。当多个团队需要访问相同的原始数据集以进行不同类型的查询时,这会很有帮助。
当然,您也可以先转换数据再加载。这完全取决于您以及最适合您的用例的方法。这是湖仓架构的伟大之处:它们同时为您提供可靠性、性能和灵活性。在所有情况下,您都将受益于 Delta Lake 出色的性能和可靠性功能。
我何时应该将 Delta Lake 用于 ETL?
您可以使用 Delta Lake 来使您的 ETL 工作负载更快、更可靠。
如果出现以下情况,Delta Lake 可能是您 ETL 工作负载的绝佳选择
- 您正在处理大数据集并希望提高性能
- 您关心可靠性并且不希望数据损坏
- 您希望能够轻松回溯到数据的早期版本
- 您希望在如何以及何时转换/加载数据方面具有灵活性
Delta Lake 通过查询优化、ACID 事务、模式强制和演进、可伸缩性和时间旅行等功能改进 ETL 工作负载。Delta Lake 支持 ETL 和 ELT 过程,允许数据存储和转换在您选择的任何阶段高效发生。