Azure Data Lake Storage 上的 Delta Lake
作者:Avril Aysha
本文将向您展示如何将 Delta Lake 与 Azure Data Lake Storage (ADLS) 结合使用。
Delta Lake 是一个开源框架,专为快速、可靠的数据存储而设计。它支持 ACID 事务,能够高效地处理大规模元数据,优化查询性能,并支持时间旅行。借助 Delta Lake,您可以直接在 ADLS 之上构建高性能的湖仓架构。
Azure Data Lake Storage 因其能够存储大量 Parquet 等格式的数据而广受欢迎。ADLS 存储具有可扩展性和成本效益,尤其适用于批处理数据。然而,ADLS 本身不支持 Delta Lake 提供的事务保证或查询优化。
本指南将介绍如何在 Azure Data Lake Storage 上读取和写入 Delta 表,并提供 Spark、Polars 和 pandas 的示例。
您将学习到
- 为什么 Delta Lake 是 Azure 工作负载的理想选择
- 如何设置 Spark 会话以将 ADLS 与 Delta Lake 连接
- 如何配置身份验证并使用 Delta Lake 将数据写入 ADLS
让我们深入了解。
为什么 Delta Lake 是 Azure Data Lake Storage 的理想选择
Azure Data Lake Storage (ADLS) 存储速度快,但列出文件速度慢。Delta Lake 通过避免昂贵的文件列表操作,使 ADLS 上的数据检索更快。
所有基于云的存储系统在列出文件时都比较慢,因为与分层文件系统不同,它们使用扁平命名空间。ADLS 没有真正的目录。相反,通过在对象名称中添加前缀来模拟“目录”。列出文件意味着系统必须扫描所有对象并按前缀过滤。
此外,ADLS 有 API 速率限制,列出许多文件需要多次 API 调用。这会造成瓶颈,尤其是对于大型数据集。
这在处理大型数据集时会成为问题。如果您的表数据分布在 ADLS 的许多文件中,您的引擎必须首先列出所有文件,然后筛选出所需的文件。列出文件会增加延迟并减慢查询速度。
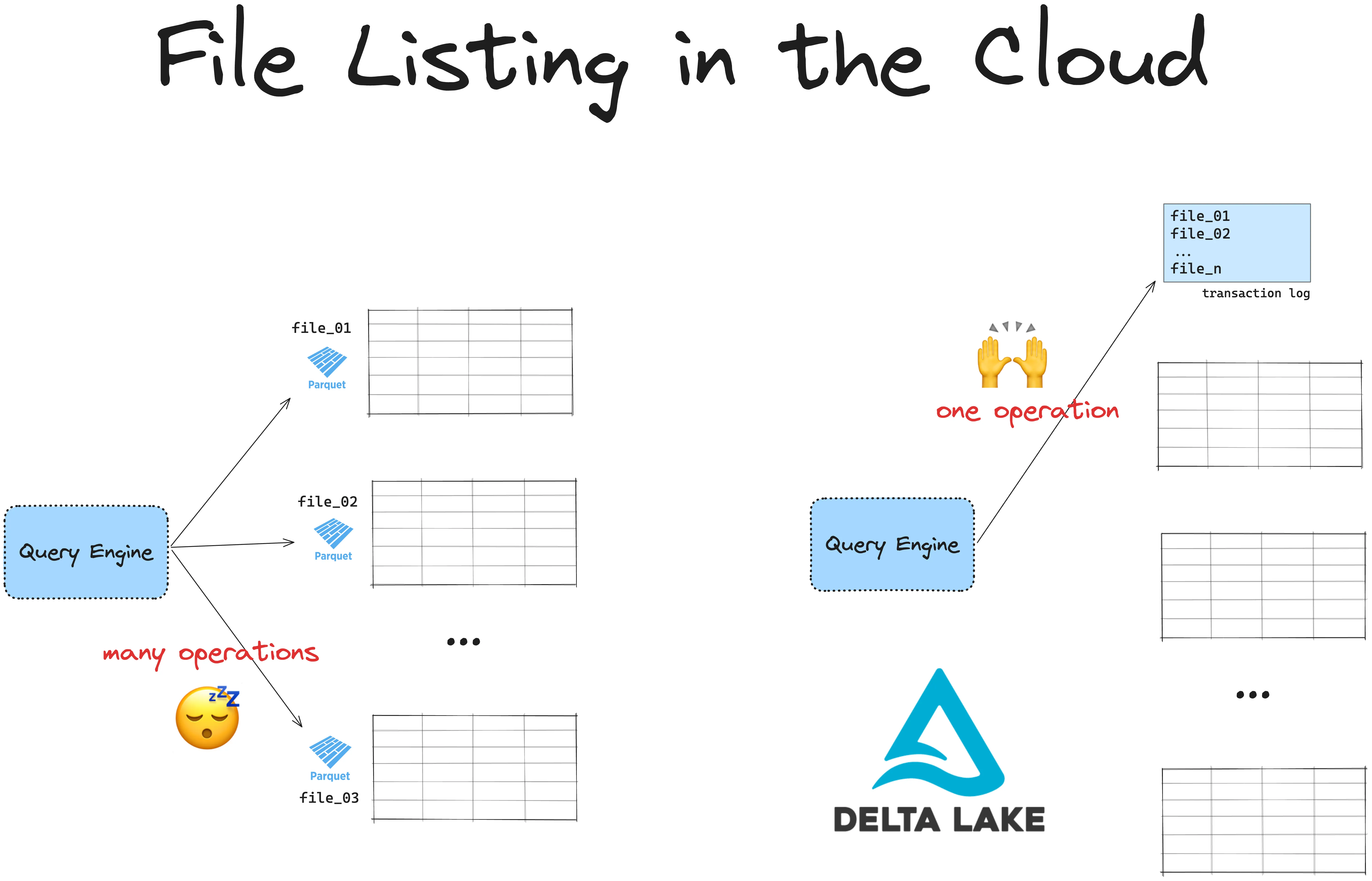
Delta Lake 通过将所有文件路径存储在事务日志中来解决这个问题。引擎无需列出文件,只需一次操作即可检索所有相关文件路径,从而使您的查询更快、更高效。Delta Lake 还支持 ACID 事务和时间旅行等其他功能,为您的基于 ADLS 的湖仓添加了灵活性和可靠性。
设置 Azure Data Lake Storage (ADLS)
在开始之前,请确保您具备以下条件
- Azure 账户:拥有 Azure 订阅以及所需权限的访问权限。
- Azure CLI:安装 Azure CLI 以设置您的存储账户。
现在,让我们在 Azure Data Lake Storage 中设置一个存储账户和容器
- 在 ADLS 中创建存储账户:
- 打开 Azure 门户。
- 转到存储账户并选择创建。
- 创建容器:
- 在存储账户中,转到容器并选择+ 容器。
- 输入唯一的容器名称,然后点击创建。
您将需要存储账户名称和容器名称来配置 Delta Lake 访问。
如何在 ADLS 上使用 Delta Lake
Delta Lake 支持各种查询引擎,其中许多引擎可以在 ADLS 上读取和写入 Delta 表。例如,您可以使用 Spark 读取和写入 Delta 表,如下所示:
# Reading from a Delta table
df = spark.read.format("delta").load("abfss://<container_name>@<storage_account>.dfs.core.windows.net/<delta_table_path>")
# Writing data to a Delta table
data.write.format("delta").save("abfss://<container_name>@<storage_account>.dfs.core.windows.net/<delta_table_path>")某些引擎需要额外的配置才能与 ADLS 上的 Delta Lake 配合使用。让我们逐步了解如何使用 Spark 在 ADLS 上设置 Delta Lake。
如何将 Delta Lake 与 Spark 结合用于 ADLS
本节将介绍如何设置配置为在 ADLS 上与 Delta Lake 配合使用的 Spark 会话。以下是一个具有正确配置的 Spark 会话示例。
用于 ADLS 的 Delta Lake Spark 设置示例
此代码展示了如何使用适用于 ADLS 的 Delta Lake 配置启动 Spark 会话
import pyspark
from delta import *
conf = (
pyspark.SparkConf()
.setAppName("DeltaLakeOnADLS")
.set("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.set("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.set("spark.hadoop.fs.azurebfs.impl", "org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem")
.set("fs.azure.account.key.<storage_account>.dfs.core.windows.net", <your-storage-account-key>)
.setMaster("local[*]") # Use all available cores
)
extra_packages = [
"org.apache.hadoop:hadoop-azure:3.3.4",
#version must match hadoop-client-runtime
]
builder = pyspark.sql.SparkSession.builder.config(conf=conf)
spark = configure_spark_with_delta_pip(
builder, extra_packages=extra_packages
).getOrCreate()请注意以下重要事项
- 将
<storage_account>替换为您的 ADLS 存储账户名称 - 将
<your-storage-account-key>替换为您的实际存储账户访问密钥 - 设置正确的 Hadoop 文件系统
- 使用 Spark 配置安装 hadoop-azure JAR。
hadoop-azure JAR 的版本应与您的 hadoop-client-runtime 版本匹配。您可以通过从 Spark 根目录运行以下代码来查找您的 hadoop-client-runtime 版本
cd <spark-root>/jars && ls -l | grep hadoop-client如果您的
hadoop-client-runtime版本是 3.3.4,那么您的hadoop-azure也应该是 3.3.4,等等。
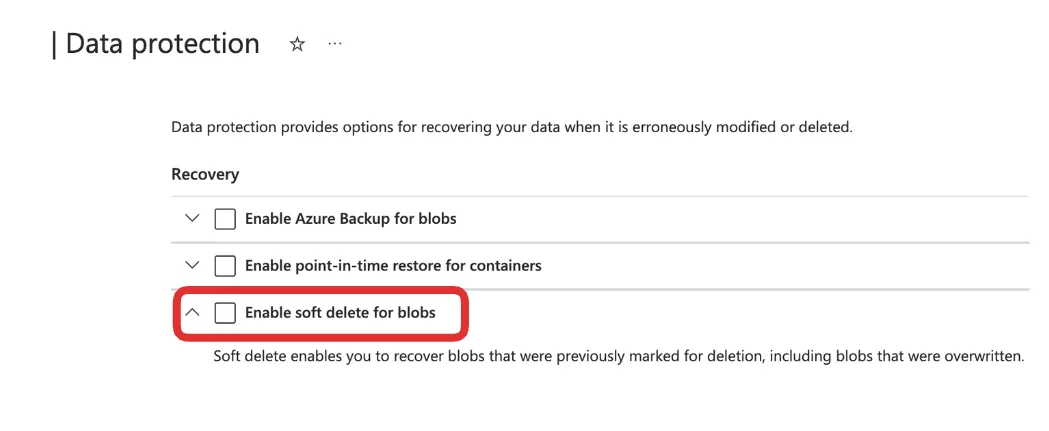
您还需要在 Azure 配置中禁用软 Blob 删除。软 Blob 删除是 Azure 的一项功能,允许您通过在指定的保留期内保留已删除的 Blob 来恢复意外删除的数据。Delta Lake 使用事务日志来跟踪更改,而软删除的文件可能会导致 VACUUM、文件列表或数据查询等操作出现问题。为了确保顺利运行,请关闭软删除,并依赖 Delta Lake 的内置工具(如版本控制和时间旅行)来管理和恢复您的数据。
您可以在数据保护设置中关闭软 Blob 删除
如果您不禁用软 Blob 删除,您可能会看到如下错误
org.apache.hadoop.fs.FileAlreadyExistsException: Operation failed: "This endpoint does not support BlobStorageEvents or SoftDelete. Please disable these account features if you would like to use this endpoint."将数据写入 ADLS 上的 Delta Lake
现在您已准备好将数据写入 ADLS 上的 Delta Lake。这是一个可以作为 Delta 表写入的示例 DataFrame
# Create sample data
data = spark.range(0, 5)
# Write data to a Delta table in ADLS
data.write.format("delta").save("abfss://<container>@<account>.dfs.core.windows.net/delta-table")请将 <container_name> 和 <storage_account> 分别替换为您的 Azure 容器和存储账户名称。
从 ADLS 上的 Delta Lake 读取数据
要读回数据,只需加载 Delta 表路径
# Read Delta table from ADLS
df = spark.read.format("delta").load("abfss://<container_name>@<storage_account>.dfs.core.windows.net/delta-table")
df.show()此命令直接从 ADLS 读取您的 Delta 表,并应输出如下数据
+---+
| id|
+---+
| 3|
| 0|
| 2|
| 1|
| 4|
+---+在 Azure Data Lake Storage 上使用 Delta Lake 的高级功能
ADLS 上的 Delta Lake 支持更新、删除和合并等高级操作。以下是一些示例。
更新和删除操作
from delta.tables import DeltaTable
# Load Delta table
deltaTable = DeltaTable.forPath(spark, "abfss://<container_name>@<storage_account>.dfs.core.windows.net/<path_to_table>")
# Update rows where id is less than 3
deltaTable.update("id < 3", {"id": "id + 10"})
# Delete rows where id is less than 5
deltaTable.delete("id < 5")合并操作
# Merge new data into Delta table
new_data = spark.range(0, 20)
deltaTable.alias("old").merge(
new_data.alias("new"),
"old.id = new.id"
).whenMatchedUpdate(set={"id": "new.id"}).whenNotMatchedInsert(values={"id": "new.id"}).execute()如何将 Delta Lake 与 Polars 结合用于 ADLS
您无需使用 Spark 即可在 Azure Data Lake Storage 上使用 Delta Lake。您可以使用 Delta Lake 的 Rust 实现(delta-rs)代替。
delta-rs 原生支持使用 Azure Data Lake Storage (ADLS) 作为对象存储后端。您无需安装任何额外的依赖项即可使用 Polars 等使用 delta-rs 的引擎向 ADLS 读取或写入 Delta 表。您确实需要正确配置 ADLS 访问凭据。
使用本地身份验证
如果您的本地会话已使用 Azure CLI 进行身份验证,那么您可以直接将 Delta 表写入 ADLS。有关此内容的更多信息,请参阅 Azure CLI 文档。
显式传递凭据
您也可以显式地将 ADLS 凭据传递给您的查询引擎。对于 Polars,您可以通过使用 storage_options 关键字来完成此操作,如上所示。这将把您的凭据转发给 Polars 在后台用于云存储访问的对象存储库。
有关定义特定凭据的更多信息,请阅读 对象存储文档。
示例:使用 Polars 将 Delta 表写入 ADLS
使用 Polars,您可以像这样直接将 Delta 表写入 ADLS
import polars as pl
df = pl.DataFrame({"foo": [1, 2, 3, 4, 5]})
# define container name
container = <container_name>
# define credentials
storage_options = {
"ACCOUNT_NAME": <account_name>,
"ACCESS_KEY": <access_key>,
}
# write Delta to ADLS
df_pl.write_delta(
f"abfs://{container}/delta_table",
storage_options = storage_options
)Pandas 示例
对于没有直接 write_delta 方法的库(例如 Pandas),您可以使用 deltalake 库中的 write_deltalake 函数
import pandas as pd
from deltalake import write_deltalake
df = pd.DataFrame({"foo": [1, 2, 3, 4, 5]})
write_deltalake(
f"abfs://{container}/delta_table_pandas",
df,
storage_options=storage_options
)在没有 Spark 的 Delta Lake 一文中阅读更多内容。
在 Azure Data Lake Storage 上使用 Delta Lake
本文向您展示了如何在 Azure Data Lake Storage 上设置 Delta Lake。您已经学习了如何配置身份验证,以及如何使用 Spark 和非 Spark 引擎在 Azure 中处理 Delta 表。ADLS 上的 Delta Lake 提供了一种高效、可靠的方式来构建可扩展的湖仓,并具备 Delta Lake 的所有出色功能:快速查询、可靠事务和高效数据处理。
查看这些文章以深入了解 Delta Lake 的核心功能
- 使用事务日志来优化您的 Delta 表。
- 使用Delta Lake 进行 ETL 管道。
- 构建Delta Lake 勋章架构。