Delta Lake 3.2
作者:Carly Akerly
我们很高兴地宣布Delta Lake 3.2版本 (发行说明) 已在 Apache Spark 3.5 上发布,其中包含可提升Delta Lake性能和互操作性的功能。
此版本包含许多改进和错误修复,但我们想重点介绍以下几点:
- 液态聚类(Liquid Clustering):一种性能更高、更灵活的表布局
- UniForm 中对 Hudi 写入的支持:将流行的 UniForm 功能扩展到 Hudi
- 类型扩展(Type Widening):当数据发生变化时,更轻松地处理模式更新
- VACUUM 清单支持:针对大型表更快地执行 VACUUM 操作
- Delta Kernel 更新:时间旅行支持、元数据读取改进、连接器生态系统的额外协议支持以及用于创建和附加数据到 Delta 表的 API 预览版。
- 删除向量(Deletion Vectors)读取性能改进:更快的删除向量读取性能
Delta Lake 3.2 有哪些新功能?
Delta Lake 3.2 在 Delta Lake 3.0 和 3.1 发布的功能基础上,引入了一系列性能增强和优化。
液态聚类
我们很高兴地宣布 Delta Lake 3.2.0 中 液态聚类(Liquid Clustering) 的正式发布。主要变化如下:
- 支持基于 ZCube 的增量聚类:ZCube 是一组由相同 OPTIMIZE 命令生成的,且数据通过希尔伯特曲线聚类的文件。已聚类文件通过 ZCube ID 在文件元数据(即 Delta 日志中)进行标记,新的
OPTIMIZE命令将仅重写未聚类文件。这显著限制了写入放大。 - 支持 ALTER TABLE … CLUSTER BY 以更改聚类列
- 支持 DESCRIBE DETAIL 以检查聚类列
- 支持 Scala 和 Python 中的 DeltaTable clusterBy API。
液态聚类在 Delta Lake 中是完全可插拔的,允许开源社区为其他聚类算法做出贡献。液态聚类中的默认技术使用 希尔伯特曲线,这是一种连续分形空间填充曲线,作为多维聚类技术,显著改善了对 ZORDER 的数据跳过。我们鼓励并期待不同聚类技术的贡献。
UniForm 中对 Hudi 写入的支持
Delta Universal Format (UniForm) 使您能够写入一份数据副本,并将其提供给任何支持 Delta Lake、Iceberg 以及现在 Delta 3.2 中 Hudi 的引擎。Delta 会自动为 Hudi 客户端生成所需的元数据,因此用户无需手动转换即可跨生态系统工作。现在有了 Hudi 的支持,Delta 成为了通用格式,统一了所有三种开放表格式。
类型扩展(Type Widening)
我们很高兴地推出 Delta 3.2 中 类型扩展(Type Widening) 的预览版,它解决了 ETL 流程中的一个重大挑战——不断演进的数据模式。这个新功能允许扩展数据类型,例如将列从 INT 演变为 LONG 而无需重写数据。类型更改可以使用 ALTER TABLE CHANGE COLUMN TYPE 命令手动应用,或者在 INSERT 和 MERGE 操作中通过模式演变自动应用。通过启用此功能,Delta Lake 不仅支持 模式演变,而且通过在读取时自动向上转型数据类型,确保了无缝的数据摄取和处理。
VACUUM 清单支持
Delta Lake 3.2 引入了 VACUUM 清单支持,该功能允许用户在 VACUUM 命令中指定一个清单表。通过利用清单表,VACUUM 操作仅选择性地处理列出的文件,从而绕过了扫描表整个目录的繁重任务。特别是对于大型表,性能差异可能非常显著,从而使数据管理任务更高效且更具成本效益。请关注即将发布的关于此功能起源的深入博客文章。
Delta Kernel 更新
Delta Kernel 项目是一组 Java 库(Rust 即将推出!),用于构建 Delta 连接器,这些连接器无需理解 Delta 协议细节 即可读取(很快也将支持写入)Delta 表。在此版本中,我们通过添加大量的性能改进、额外功能、改进的协议支持并修复了所有粗糙之处,改进了读取支持,使其达到生产就绪状态。
- 支持时间旅行。现在您可以在 版本 ID 或 时间戳 下读取表快照。
- 改进的 Delta 协议支持。
- 支持 读取带有
checkpoint v2的表。 - 支持读取带有
timestamp分区类型数据列的表。 - 支持 读取带有列数据类型
timestamp_ntz的表。
- 支持 读取带有
- 改进了拥有数百万文件的超大型表的表元数据读取性能和可靠性
- 通过将分区谓词推送到检查点 Parquet 读取器以最小化读取的检查点文件数量,改进了 检查点读取延迟。
- 通过 使用
delta-storage模块中的LogStores 以加快listFrom调用,改进了状态重建延迟。 - 在瞬态故障情况下 重试 加载
_last_checkpoint检查点。从该文件加载上次检查点信息有助于更快地构建 Delta 表状态。 - 在尝试查找版本之前或版本上的最后一个检查点时,优化 以最小化对对象存储的列出调用次数。
在此版本中,我们还添加了 API 的预览版,允许连接器执行以下操作:
- 创建 Delta 表
- 向 Delta 表插入数据。当前仅支持盲追加。
- 幂等地更新 Delta 表。
上述功能适用于分区表和非分区表。请参阅 示例 以获取创建和盲追加数据到表的连接器示例代码。我们仍在开发和演进这些 API。请尝试并向我们提供您的反馈。
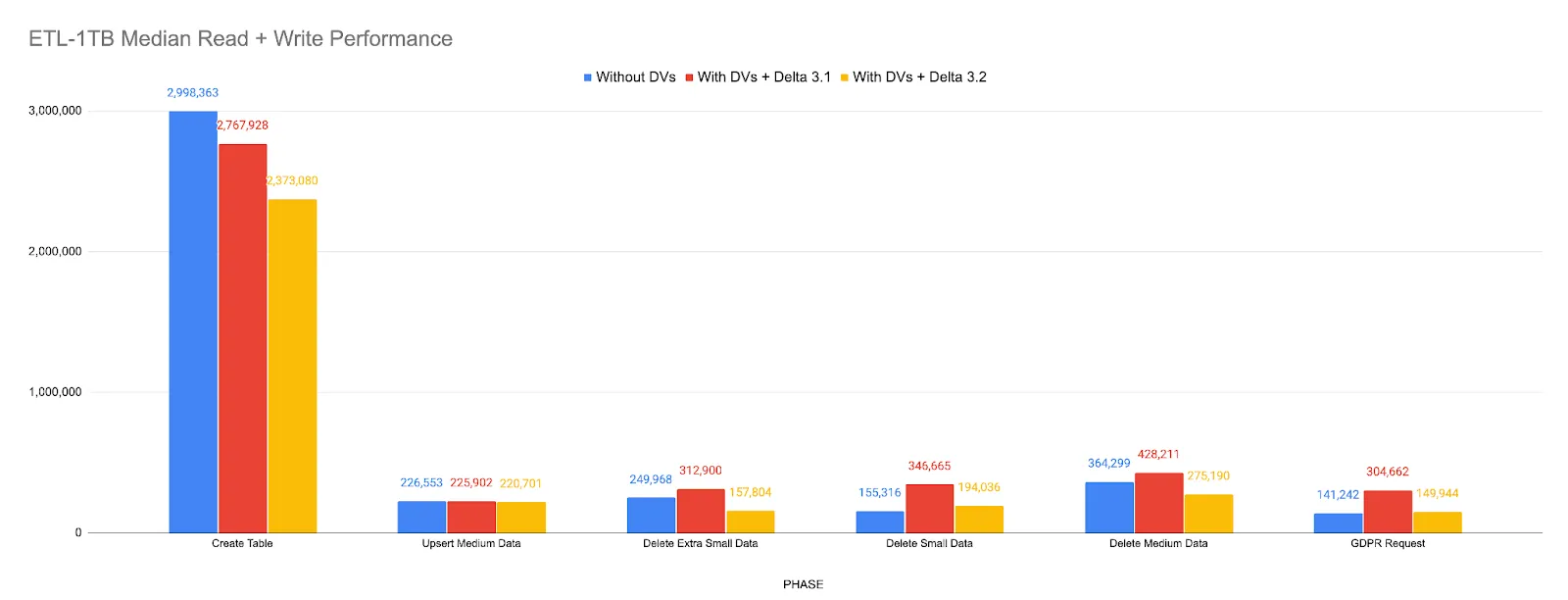
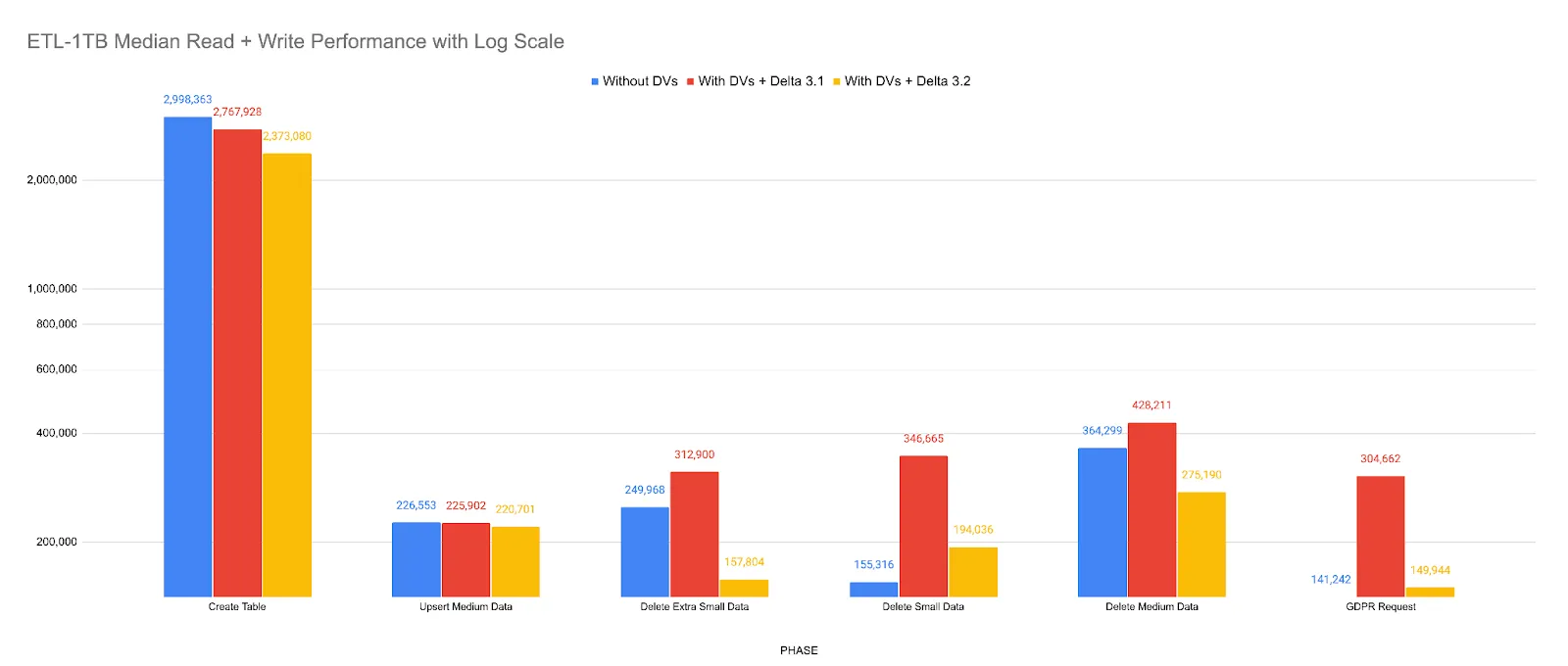
删除向量读取性能改进
我们继续改进使用删除向量(DV)的读时合并(merge-on-read)性能。
- 我们通过 移除将 DV 信息广播到执行器 来 提高 稳定性,这减少了驱动程序的内存消耗,并防止了对于 1TB 以上的超大型 Delta 表可能出现的驱动程序内存溢出 (Driver OOM)。这项工作还通过节省读取小型 Delta 表时的固定广播开销来提高性能。
- 我们通过启用 谓词下推和文件拆分,提高了带有过滤查询的 DV 读取性能。
- 我们使用 真实世界的工作负载 组合对这些改进进行了基准测试。
其他功能
此版本包含更多功能,包括以下改进。有关所有激动人心的功能以及如何使用发布候选工件的说明,请参阅完整的发行说明。
- 支持 Vacuum Writer Protocol Check:Delta Spark 现在可以支持
vacuumProtocolCheckReaderWriter 功能,该功能确保在VACUUM操作期间一致应用读取器和写入器协议检查,解决了潜在的协议差异并减轻了因跳过写入器检查而导致数据损坏的风险。 - 提交内时间戳预览:启用后,此 预览功能 将单调递增的时间戳持久化到 Delta 提交中,确保它们不受文件操作的影响。启用后,即使表目录被重新定位,时间旅行查询也将产生一致的结果。
致谢
感谢所有参与 Delta Lake 3.2 发布的人员
Adam Binford, Ala Luszczak, Allison Portis, Ami Oka, Andreas Chatzistergiou, Arun Ravi M V, Babatunde Micheal Okutubo, Bo Gao, Carmen Kwan, Chirag Singh, Chloe Xia, Christos Stavrakakis, Cindy Jiang, Costas Zarifis, Daniel Tenedorio, Davin Tjong, Dhruv Arya, Felipe Pessoto, Fred Storage Liu, Fredrik Klauss, Gabriel Russo, Hao Jiang, Hyukjin Kwon, Ian Streeter, Jason Teoh, Jiaheng Tang, Jing Zhan, Jintian Liang, Johan Lasperas, Jonas Irgens Kylling, Juliusz Sompolski, Kaiqi Jin, Lars Kroll, Lin Zhou, Miles Cole, Nick Lanham, Ole Sasse, Paddy Xu, Prakhar Jain, Rachel Bushrian, Rajesh Parangi, Renan Tomazoni Pinzon, Sabir Akhadov, Scott Sandre, Simon Dahlbacka, Sumeet Varma, Tai Le, Tathagata Das, Terry Kim, Thang Long Vu, Tim Brown, Tom van Bussel, Venki Korukanti, Wei Luo, Wenchen Fan, Xupeng Li, Yousof Hosny, Gene Pang, Jintao Shen, Kam Cheung Ting, panbingkun, ram-seek, Sabir Akhadov, sokolat, tangjiafu
我们还要特别感谢 Scott Sandre 为此次发布所做的贡献。
一如既往,衷心感谢我们的开源社区的贡献。
今天就加入社区吧!
我们始终很高兴与现有贡献者社区合作,并欢迎新成员。如果您有兴趣帮助 Delta Lake 项目,请查看项目 路线图,并通过我们的任何论坛加入我们的社区,包括 GitHub、Slack、X、LinkedIn、YouTube 和 Google Groups。