Delta Lake 3.1.0
作者:Carly Akerly
我们很高兴宣布 Delta Lake 3.1 版本(发行说明)已在 Apache Spark 3.5 上发布,其中包含的功能将使 Delta Lake 更易于使用和标准化。
此版本包含许多改进和错误修复,但我们想重点介绍以下内容:
- 带删除向量的
MERGE:合并操作减少高达 3.7 倍 - 优化写入和自动压缩:两项功能可自动优化文件大小,以实现最佳开箱即用读取性能
- Delta Kernel 读取 API 的改进:通过表状态重建和支持基于查询谓词的数据跳过,提高了读取性能
- UniForm Iceberg 兼容性:支持 MAP 和 LIST 数据类型,并提高了与流行的 Iceberg 读取客户端的兼容性
- (预览)Liquid clustering:一种性能更高、更灵活的表布局。
- Delta Sharing 与 Delta-Spark 集成:您现在可以使用 Delta-Spark 查询已使用 Delta Sharing 协议共享的 Delta Lake 表。
- Min/Max 查询优化:利用元数据统计信息,将 Min/Max 聚合查询的速度提高多达 100 倍
Delta Lake 3.1 有哪些新功能?
Delta Lake 3.1 在 Delta Lake 3.0 发布的功能基础上,引入了大量的性能增强和优化。
带删除向量的 MERGE
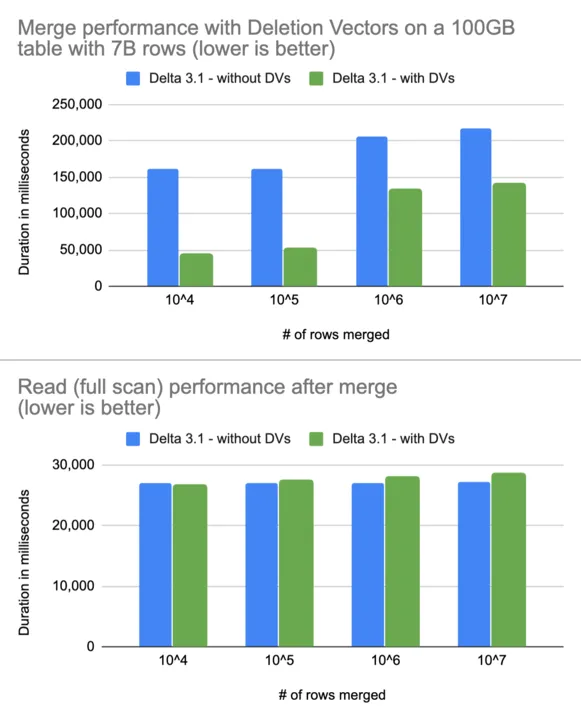
Delta Lake 3.0 版本通过支持删除向量,为 UPDATE 和 DELETE 语句带来了一些主要的性能升级。在此版本中,MERGE 现在也支持删除向量。这减少了 MERGE 操作的写入开销,并将其性能提高了多达 3.7 倍。下图显示了在合并后,使用删除向量对大型表进行小型更新的速度更快,几乎不影响读取性能。
优化写入和自动压缩
频繁地写入表可能导致文件布局碎片化。表中存在大量小文件可能会导致读取性能变慢,因为打开和关闭小文件的开销更高。Optimize 等离线操作通过压缩,并在需要时进行 Z-Ordering,将小文件合并成大文件,从而减少了这个问题。表中小文件的数量会持续增长,直到显式运行这些操作。Delta 3.1.0 添加了两项功能,可以显著提高开箱即用性能——优化写入和自动压缩。
优化写入强制任何分布式写入操作(即,仅限于 Delta on Spark 操作)在将文件写入表之前,使用数据洗牌重新平衡数据。这显著减少了写入操作时生成小文件的可能性。强烈建议在分区表上启用此功能,因为分区表数据跨分区碎片化的可能性更高。
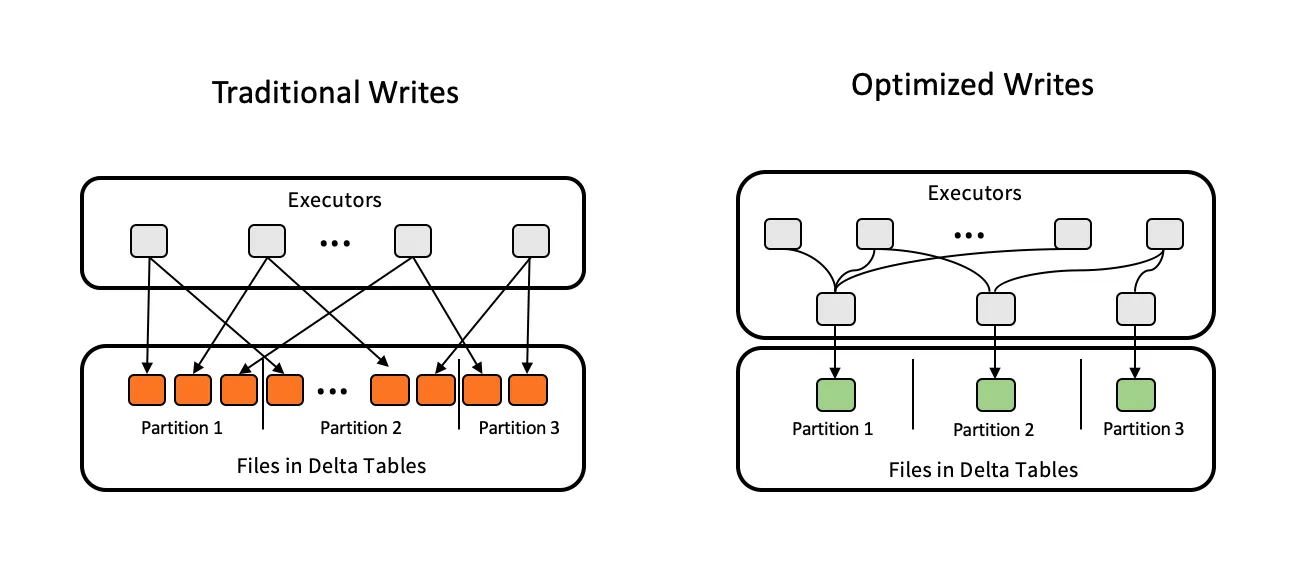
然而,优化写入本身能做的有限。例如,在持续向 Delta Lake 表追加数据的流式管道中,每次写入可能只包含少量数据。单独优化每次写入可能仍然会导致大量写入后小文件堆积。自动压缩通过在每次写入操作后运行“迷你优化”操作来压缩所有先前写入中的小文件,从而解决了这个问题。因此,当在表上显式启用此功能时,它将防止小文件积压的产生。
请注意,这两项功能都会略微增加写入延迟,以换取更好的开箱即用读取性能。因此,它们默认不启用,您需要根据您的工作负载要求启用它们。
Delta Kernel 中的数据跳过支持
Delta Kernel 是一个新项目,旨在简化 Delta 连接器的构建和维护,作为 Delta Lake 3.0 的一部分发布。根据社区反馈,添加了许多新功能、API 改进和错误修复。最值得注意的是与读取性能相关的改进。
对于任何给定的查询谓词,Delta Kernel 可以使用存储在 Delta Lake 元数据中的文件级统计信息来限制要扫描的文件列表。通过跳过数据,这些查询扫描的数据更少,从而实现更快的读取性能。
Delta Kernel 现在还可以通过改进的表状态重建功能,更快地读取表元数据(即模式、属性等)。Delta Flink Sink 3.1.0 包含一个实验性的 Kernel 集成,在写入一个包含 700 万个文件、大小为 11 PB 的表时,将 Flink 管道的初始化时间缩短了 45 倍(即,通过更快的表元数据获取)。
Delta Kernel 现在还支持读取具有列映射 id 模式的表。
欲了解更多信息,请参阅
- Delta Kernel API 文档
- 用户指南,其中包含在独立 Java 程序或分布式处理连接器中使用 Kernel 的分步过程。
- 幻灯片,解释了 Kernel 的原理和 API 设计。
- 示例Java 程序,演示如何使用 Kernel API 读取 Delta 表。
UniForm Iceberg 兼容性
Delta 3.1.0 扩展了 Delta Lake 3.0 中首次发布的 UniForm 支持。
Delta 3.1.0 包含一种新的 Iceberg 支持模式 IcebergCompatV2,该模式增加了对 Map 和 List 数据类型的支持,并为时间戳提供了更好的兼容性,将时间戳写入为 int64,与 Iceberg 规范一致。文件统计信息(列最小值、最大值、行数和空值计数)现在已转换为 Iceberg 格式。
此外,您现在可以使用 UPGRADE UNIFORM 命令将现有的 Delta Lake 表升级到 UniForm
REORG TABLE table APPLY (UPGRADE
UNIFORM(ICEBERG_COMPAT_VERSION=2))有关这些新功能的更多信息,请查阅 UniForm 的文档。
Liquid Clustering
Hive 风格分区通常用于提高数据湖的读取性能,但如果您的列基数高、数据严重倾斜或数据变化频繁,则可能导致维护和性能问题。根据数据分布情况,您最初使用的分区策略最终可能导致文件大小和分区大小不一致,最终导致性能下降。如果您想更改分区以适应新数据,则必须重写表,这是一个耗时且昂贵的过程。
Delta Lake 2.0 引入了 Zorder 的概念,这是一种多维聚类技术。OPTIMIZE ZORDER BY 命令应用 ZORDER 聚类并提高利用其谓词中 ZORDER BY 列的查询性能。但是,它有以下限制:
OPTIMIZE ZORDER BY总是重新聚类(即重写)表中的所有数据,导致高写入放大。此外,当执行失败时,不会保存部分结果。ZORDER BY列不持久化,用户需要记住以前的ZORDER BY列,这经常导致用户错误。
Liquid clustering 是 Delta Lake 3.1.0 中可用的预览功能,它引入了一种新的 增量 聚类方法。主要更改如下:
- Liquid 使用 希尔伯特曲线,一种连续的分形空间填充曲线作为多维聚类技术,显著改善了对
ZORDER的数据跳过。 - 增量聚类围绕 ZCubes 的新概念构建。ZCube 是由同一
OPTIMIZE命令生成的具有希尔伯特聚类数据的文件组。已经聚类的文件在文件元数据(即 Delta 日志)中通过 ZCube id 标记,新的OPTIMIZE命令将只重写未聚类的文件。这显著限制了写入放大。 - 最后,聚类列信息存储在表中,因此用户无需每次都在
OPTIMIZE命令中指定聚类列,从而避免了错误。
请注意,Delta 3.1.0 仅提供了 Liquid Clustering 的预览版,存在主要限制。为了使用聚类,您需要启用 Spark 会话配置标志 spark.databricks.delta.clusteredTable.enableClusteringTablePreview。
Liquid clustering 通过 CLUSTER BY 语句在表创建时启用
-- Create an empty table
CREATE TABLE table1(col0 int, col1 string) USING DELTA CLUSTER BY (col0);
-- Using a CTAS statement
CREATE TABLE table2 CLUSTER BY (col0) -- specify clustering after table name, not in subquery
AS SELECT * FROM table1;
-- Optimize / cluster the table without specifying the columns
OPTIMIZE table1更多详情请参阅文档和示例。如需更深入的了解,请参阅原始设计文档。
Delta Sharing Spark 连接器
在 Delta 3.1.0 中,我们将 delta-sharing-spark Maven Artifact 从 delta-io/delta-sharing Github 仓库迁移到 delta-io/delta 仓库。您可以使用它通过 Apache Spark 读取使用 Delta Sharing 协议共享的 Delta Lake 表。该连接器支持读取表的快照、通过流式传输增量读取表以及 变更数据源 (Change Data Feed) 查询。delta-sharing-spark Maven Artifact 的现有用户必须将其版本从 <= 1.0 升级到 3.1。
除了迁移之外,Delta Sharing 还增加了对具有高级功能的 Delta Lake 表的支持,例如删除向量和列映射。要使用这些功能,您必须在 SparkSession 中设置配置以使用 Delta Sharing 读取格式。批处理数据可以按原样读取,但对于带有删除向量或列映射的表的流式和 CDF 查询,您还需要设置 responseFormat=delta。请参阅文档以获取更多详细信息。
Min/Max 查询优化
对于大型表,像 MIN 和 MAX 这样看似简单的聚合查询可能会耗费大量时间。通过使用表元数据,这些操作的速度得到了加快,减少了全面表扫描的需要,并将性能提高了多达 100 倍。
Delta Lake 3.1 中的其他功能
此版本包含更多功能。请参阅发行说明以获取完整列表。
致谢
感谢所有参与 Delta Lake 3.1 版本发布的人员
Ala Luszczak, Allison Portis, Ami Oka, Amogh Akshintala, Andreas Chatzistergiou, Bart Samwel, BjarkeTornager, Christos Stavrakakis, Costas Zarifis, Daniel Tenedorio, Dhruv Arya, EJ Song, Eric Maynard, Felipe Pessoto, Fred Storage Liu, Fredrik Klauss, Gengliang Wang, Gerhard Brueckl, Haejoon Lee, Hao Jiang, Jared Wang, Jiaheng Tang, Jing Wang, Johan Lasperas, Kaiqi Jin, Kam Cheung Ting, Lars Kroll, Li Haoyi, Lin Zhou, Lukas Rupprecht, Mark Jarvin, Max Gekk, Ming DAI, Nick Lanham, Ole Sasse, Paddy Xu, Patrick Leahey, Peter Toth, Prakhar Jain, Renan Tomazoni Pinzon, Rui Wang, Ryan Johnson, Sabir Akhadov, Scott Sandre, Serge Rielau, Shixiong Zhu, Tathagata Das, Thang Long Vu, Tom van Bussel, Venki Korukanti, Vitalii Li, Wei Luo, Wenchen Fan, Xin Zhao, jintao shen, panbingkun
我们还要特别感谢 Venki Korukanti 为此次发布做出的贡献。
一如既往,衷心感谢我们的开源社区的贡献。
今天就加入社区吧!
我们始终很高兴与现有贡献者社区合作,并欢迎新成员。如果您有兴趣帮助 Delta Lake 项目,请查看项目路线图,并通过我们的任何论坛加入我们的社区,包括 GitHub、Slack、X、LinkedIn、YouTube 和 Google Groups。