Delta Kernel - 简化构建 Delta Lake 连接器
Delta Lake 最近实现了一个令人印象深刻的里程碑,每月下载量超过 2000 万次!这清楚地表明 Delta Lake 已成为构建数据湖和数据湖仓最流行的数据格式之一。这一成功主要归功于令人惊叹的社区和连接器生态系统,它们允许 Delta 表通过任何引擎进行操作。
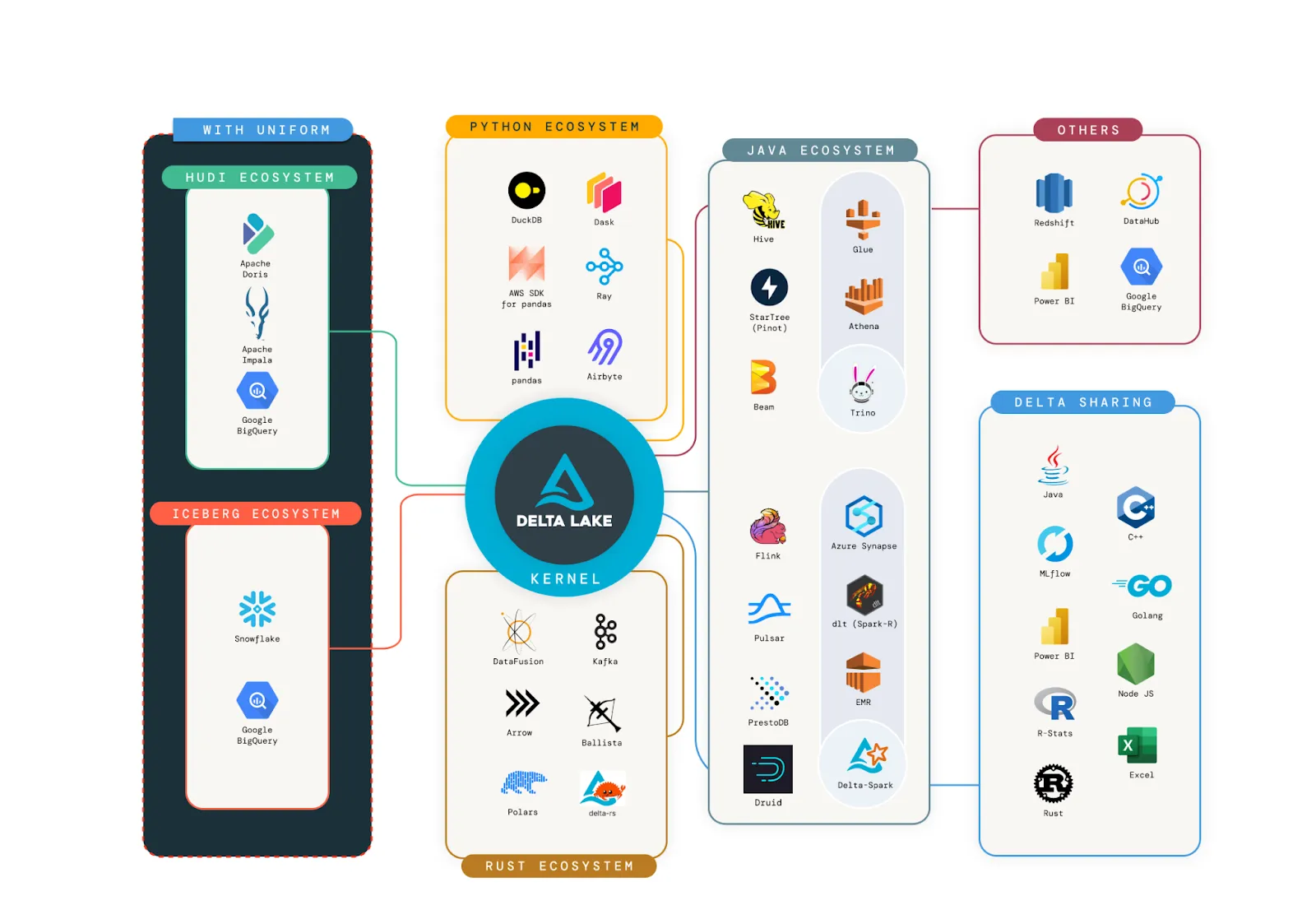
展示了丰富的连接器生态系统。我们的目标是让所有这些连接器都以 Delta Kernel 为核心。
Delta Lake 继续创新并构建令人惊叹的新功能。例如:类型拓宽、变体类型支持、提交内时间戳以及更多。真正的挑战是确保所有连接器都能通过支持协议中的新功能来跟上这种创新速度。为了避免生态系统碎片化,去年我们启动了 Delta Kernel 倡议,以抽象化协议细节,让连接器开发者能够更少关注 Delta 复杂的内部细节,更多关注可实现无缝集成的 API。
在本博客中,我们将讨论谁正在使用 Delta Kernel、Delta Kernel 是什么、为什么设计它具有挑战性,以及如何开始使用它来构建 Delta 连接器。
谁正在使用 Delta Kernel?
Delta Kernel 倡议仍处于早期阶段,API 仍在稳定中。具体来说,
- Kernel Java API - 读取 API(即
Scan,首次发布于 Delta 3.0)已基本稳定,写入 API(首次发布于 Delta 3.2)仍在发展中。 - Kernel Rust API - 读取 API 已在 0.1 版本中发布。
尽管尚不成熟,Delta 社区已开始采用 Kernel。
- DuckDB - DuckDB 已使用 Delta Kernel Rust 发布了其 Delta 支持。
- Apache Druid - Druid 已使用 Kernel Java 添加了其首个 Delta 支持,代码量少于 1000 行生产代码。
- Apache Flink - 即使是部分迁移到 Delta Kernel Java,也为 Delta Flink 连接器带来了45 倍的启动时间改进。
- Delta Sharing - Delta Sharing 生态系统已发展其协议以共享 Delta 元数据目录。两个社区正在合作,在 Sharing Server 和像 delta-sharing-pandas 这样的 Sharing 客户端中采用 Delta Kernel。
- Delta-rs - 我们与 Delta-rs 社区密切合作,开始迁移到 Delta Kernel Rust。
还有更多采用正在进行中。请继续关注更多更新和博客文章。我们邀请整个社区构建新的 Delta 连接器或将现有连接器迁移到使用 Delta Kernel。具体来说,强烈建议使用 Delta Standalone 的现有连接器迁移到 Delta Kernel,因为 Delta Standalone 已不再维护,并将很快弃用。
为了帮助您入门,让我们讨论 Delta Kernel 是什么,以及如何开始使用它!
Delta Lake 协议是什么?
在我们深入了解 Delta Kernel 是什么之前,先快速回顾一下 Delta Lake 协议。Delta Lake 是一种协议,它为存储在分布式文件系统或对象存储(如 S3、Google Cloud Storage 或 Azure Data Lake Storage)中的大量文件数据带来ACID 属性。Delta Lake 表由原子事务日志组成,该日志指定了表的顺序和元数据以及事务,以及作为 Parquet 存储的实际原始数据文件。
要读取或写入 Delta Lake 表,引擎或连接器必须理解如何解释日志,并将其元数据与原始 Parquet 数据结合起来,以生成正确的表数据。
一个简单的例子是分区列。当数据按列分区时,给定分区中的每一行都共享该列的相同值。为了节省空间并加快读取速度,我们不在原始 Parquet 文件中存储该列;相反,我们在 Delta 日志中记录该值。在查询时,此值会传播到该分区中的每一行。
每个 Delta 功能都需要特定的操作才能正确读取或写入数据。在每个引擎和连接器中跟上这些操作是具有挑战性的,这导致了 Delta Kernel 的创建。
Delta Kernel 是什么?
Delta Kernel 是一组库,您可以使用它们通过任何引擎操作 Delta Lake 表。具体来说,您可以在以下位置找到最新版本的内核:
广泛的数据生态系统拥有用各种语言编写的引擎——Java(例如 Spark、Trino)、Python(例如 Pandas)、C/C++(例如 DuckDB)、Rust(例如 Delta-rs、Polars、DataFusion)。用单一语言构建一个满足所有此类引擎需求的单一库是相当困难的。因此,我们正在构建两个内核,一个用 Java 编写,另一个用 Rust 编写。Java Kernel 将用于任何希望添加 Delta 支持的基于 JVM 的引擎。Rust Kernel 还具有 C 和 C++ 绑定,这意味着它可以集成到用 Rust、C、C++、Python 或任何其他可以消费此类库的项目中。Rust Kernel FFI 层提出了一些独特的 API 设计挑战。我们将发布后续博客文章,涵盖感兴趣读者的部分详细信息。
这些库为高级操作(例如读取、追加)提供稳定的 API,这些 API 抽象掉了组合日志元数据与原始表表的所有细节。它们向 API 用户隐藏了 Delta Lake 协议细节,例如分区列、删除向量或列映射。这允许简单地将您的连接器指向一个表并获取正确的数据。此外,Delta Kernel 有助于 Delta 表的最简单方面。它理解日志,计算表的最新快照,并简化读取和写入数据的过程。这些库的最终目标是让整个 Delta 社区满意!让我们了解如何实现。
-
Delta 连接器开发者会很开心 - 在 Kernel 之前,开发者构建连接器以从其引擎读取 Delta 表必须理解许多低级协议规范(例如,删除向量)才能实现支持。在 Delta 存在的头五年,协议规范相对简单,理解和实现此规范对于连接器开发者来说要容易得多,从而形成了丰富的连接器生态系统。
然而,Delta 的创新速度正在加快:Delta 在去年为协议添加了 八个新功能,目前还有 七个新功能 正在开发中。随着每个功能的增加,规范变得更加复杂,连接器更难跟上。例如,删除向量 (DVs) 从根本上改变了 Delta 表的架构,要求开发者更新其连接器的许多部分,例如使用 DV 位图过滤读取数据和调整最小/最大统计信息。使用 Kernel,连接器开发者只需要理解稳定的高级 Kernel API。一旦他们使用 Kernel 构建或迁移了他们的 Delta 连接器,他们就可以简单地升级到最新的 Kernel 版本以支持最新的协议功能。
-
Delta 最终用户(即数据工程师和数据科学家)将感到满意 - 由于 Delta 连接器可以通过 Kernel 升级轻松支持最新功能,Delta 用户将始终能够从他们喜欢的引擎操作 Delta 表,无需担心兼容性,并利用最新的创新。例如,Apache Spark 和 Apache Druid 的用户都可以轻松地在 Delta 表中启用删除向量 (DVs),以享受 Spark 中 4 倍更快的 MERGE 操作,并从 Druid(最近发布了使用 Kernel 的 Delta 支持)读取表。
-
Delta 协议开发者将感到满意 - 设计新协议功能的开发者希望他们的功能能够被最终用户快速广泛采用。Kernel 使新功能的推出和采用对他们来说更容易:他们可以在 Kernel 中实现他们提议的功能(因为他们最了解他们提议的规范),并且连接器生态系统可以快速采用和使用他们的功能。事实上,提议协议更改的 RFC 过程要求只有在可以在 Kernel 中实现更改的情况下才能接受更改。换句话说,Delta Kernel 将为 Delta 的未来提供指导路径。
为了让 Delta Kernel 库尽可能地实现三赢局面,它们必须在众多的处理引擎和连接器中工作。去年我们启动这项倡议时,我们意识到这是一个相当大的挑战。让我们了解为什么。
为什么设计 Delta Kernel 具有挑战性?
乍一看,设计这样一个库似乎很简单。毕竟,有许多针对 JSON、Avro 和 Parquet 等文件格式的库,允许用户无需了解这些协议的复杂性即可读取数据。那么,为什么“又一个格式”会很困难呢?
让我们探讨一下为什么设计 Delta Kernel 带来了一系列独特的挑战。
-
挑战 1:抽象化“表格式” - 像 JSON、Avro、Parquet 这样的格式是“文件格式”,这意味着每个文件都包含读取所需的数据和元数据。例如,Parquet 尾部包含读取列式数据所需的所有模式和行组信息。一个 Parquet 表本质上是一组 Parquet 文件,它们隐含地共享一致的模式。然而,这些隐含的假设可能很脆弱——一个写入不正确的文件可能会导致表不一致或损坏(例如,不一致的模式、不完整的文件)。
文件格式的这些限制导致了像 Delta Lake、Iceberg 和 Hudi 这样的“表格式”的开发,其中表级元数据单独存储在“元数据文件”中,并通过表操作进行事务性更新。构建一个能够抽象表格式的元数据和数据的库是一个新颖的挑战,因为它需要有凝聚力地处理这两个方面——一个以前没有完全探索过的问题。
-
挑战 2:以正确的抽象级别支持分布式引擎 - 如果引擎想要在单个线程或进程中读取数据,那么 Delta Kernel 只需要在给定路径时返回表数据。然而,像 Apache Spark 或 Trino 这样的分布式引擎,或者 DuckDB 的多线程 Parquet 读取器,操作方式不同:它们需要表的元数据(模式、文件列表等)来规划分布式作业的任务。这些任务在不同的机器或线程上运行,根据它们获得的元数据部分读取表数据的不同部分。
为了支持分布式引擎,Delta Kernel 必须提供适当的抽象级别。它需要:
- 暴露足够的“抽象元数据”,以便引擎可以用于规划,而无需理解协议细节。
- 允许使用必要的抽象元数据读取表数据。
具体来说,Delta Kernel 以不透明元数据(“抽象元数据”)的形式返回表中文件的路径和统计信息(例如行数、最小/最大值)等信息。引擎不需要理解数据的内容,但可以将数据分成子集以分发给工作器。在每个工作器中,不透明元数据可以传递回 Delta Kernel,Delta Kernel 使用它来读取并返回原始表数据。
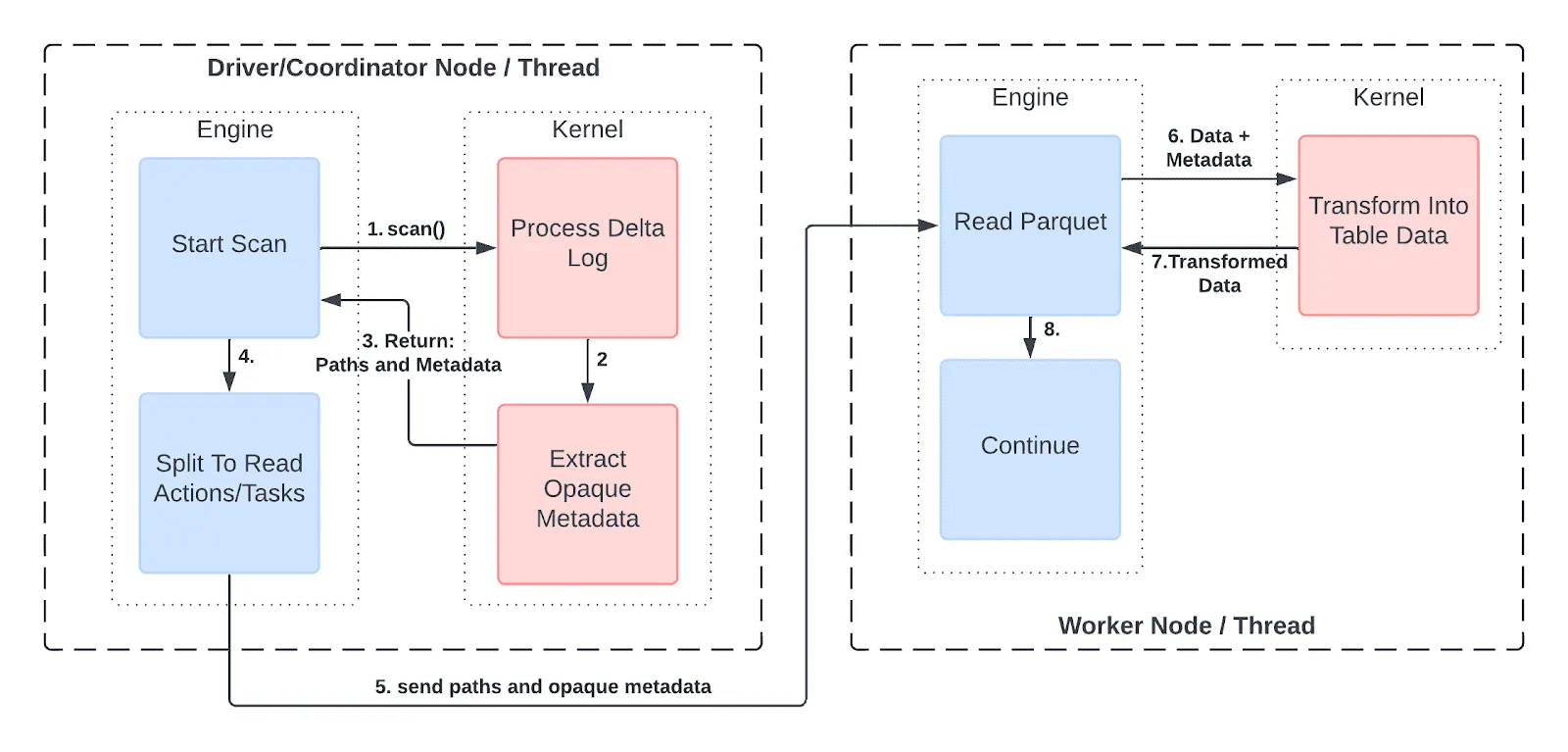
展示分布式引擎如何使用 Kernel
- 挑战 3:通过插件接口使其可自定义到任何引擎 - 引擎通常需要完全控制系统资源,如内存、CPU 和磁盘,以及环境,如已安装的库。为了让 Delta Kernel 可以在任何引擎中使用,它需要以尽可能少的环境假设来设计。因此,在 Kernel 中,我们已经将所有资源密集型操作(如 Parquet 读取、JSON 解析或表达式评估)封装在
Engine接口后面。此接口允许连接器开发者插入引擎定制的实现,以便引擎可以完全控制 Kernel 使用的资源。Kernel 的目标是保持一个薄库,可以插入到连接器/引擎的中间,从而尽可能利用引擎的功能。这在以下架构图中有所说明。
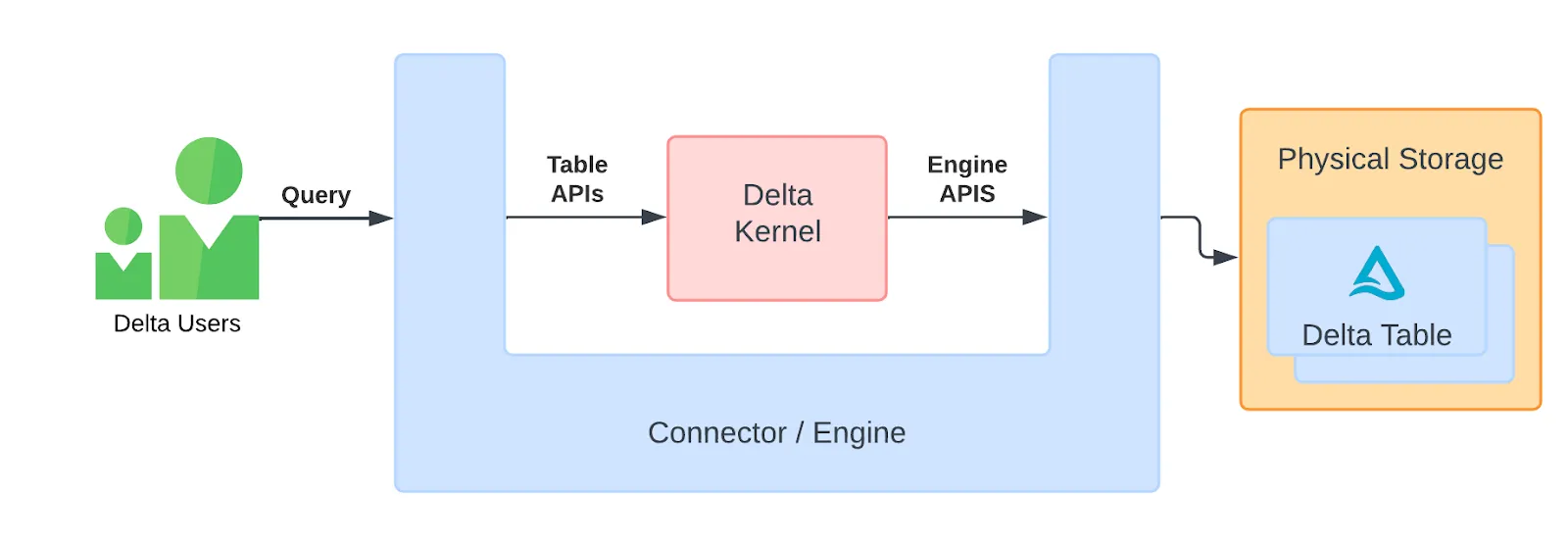
这种“U”形架构允许数据从引擎流向内核,然后再流回引擎,从而允许引擎使用自己的数据类型、内存分配和其他资源管理。
请注意,有两组 API
- 连接器的表 API 在表上操作。稍后将详细介绍。
- 引擎 API 用于可选地插入特定于引擎的组件。
- 挑战 4:在支持复杂引擎的同时,使简单连接器易于编写 - Kernel 提供了 Engine 接口的“内置”默认实现。这确保开发者可以使用此默认实现快速轻松地入门。在他们构建了一个端到端完整的连接器之后,他们可以根据需要用特定于引擎的组件(即“更好的电池”)替换默认组件,以实现更好的性能、内存使用,或满足引擎可能有的任何其他要求。
据我们所知,Delta Kernel 是第一个试图同时解决所有这些挑战的尝试。
如何使用 Delta Kernel API?
如前所述,Delta Kernel 主要有两组 API:“表”和“引擎”。
表 API
“表 API”是引擎可以调用以启动数据读取或写入的 API。这些 API 非常简单,尤其是在读取的情况下。例如,要扫描 Delta 表中的所有数据,可以简单地编写:
engine = default_engine.create()
table = Table.for_path(engine, "/path/to/table")
snapshot = table.get_latest_snapshot(engine)
scan = snapshot.get_scan_builder(engine).with_schema("id", "name", "address").build()
data = scan.execute()您可以在 Kernel 存储库中的示例程序中查看这些 API 的完整示例用法:
引擎 API
为了执行此扫描,Delta Kernel 需要实际读取 JSON 文件以获取元数据,读取 Parquet 文件以获取原始表数据,并对数据评估表达式以生成正确的最终数据。如 [挑战 4] 中所述,我们希望尽可能地让引擎控制如何发生这种情况。这就是“引擎 API”发挥作用的地方。这些 API 包括以下功能:
- 读取 JSON 文件
- 读取 Parquet 文件
- 评估通过上述 API 读取的数据上的表达式
通过实现这些 API,引擎可以允许 Kernel 指导引擎自身的数据函数和表达式评估,以正确读取表。扫描结束时,引擎将获得其自身格式的正确数据,并像往常一样继续查询处理。
请注意,实现“引擎 API”是可选的。引擎可以使用默认实现并以“Kernel 格式”获取数据,对于 Rust Kernel 来说是 Arrow,对于 Java Kernel 来说是 基于堆的 向量。
要查看这些 API 实现的示例,默认引擎实现是一个很好的起点:
在不久的将来,我们将发布一些“深度解析”博客文章,详细解释这些 API 的工作原理,以及如何利用默认实现或构建自己的集成。
接下来是什么?
展望未来,我们很高兴能稳定我们的 API,添加对所有 Delta 功能的支持,并与社区合作以集成到更多的引擎和连接器中!您可以在此处查看项目的路线图。
有关 Delta Kernel 项目的更多信息,请参阅以下内容:
要为这些项目做出贡献,请参阅 Github issue 以获取想法。
要与 Delta 社区互动,请加入 Delta Lake Slack 频道 - go.delta.io/slack