使用 Daft 在大规模 Delta Lake 表上进行高性能查询

通过高性能分布式查询引擎连接您的湖仓和机器学习管道
Daft 是一个用于 Python 的分布式数据帧库,最近新增了对 Delta Lake 表的分布式并行读取支持,实现了从您的湖仓进行高吞吐量读取。Daft 还实现了对过滤谓词进行性能关键型优化,例如自动分区修剪和基于统计的文件修剪,跳过不需要读取的数据。
使用 Daft 读取 Delta Lake
Daft 是一个用于大规模 ETL、分析和机器学习/人工智能的框架。其熟悉的 Python 数据帧 API 旨在超越 Spark 的性能和易用性,同时提供与现代数据存储系统(如数据目录、数据湖和湖仓)以及机器学习训练和推理管道的一流集成。
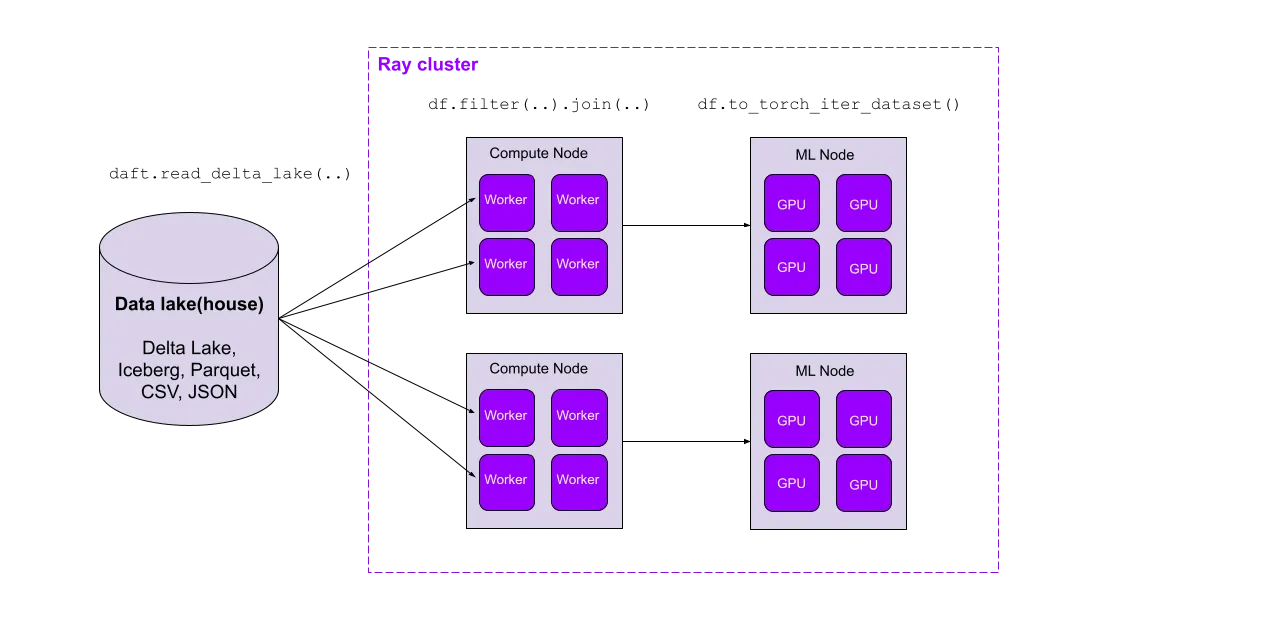
Delta Lake 是一个开源的 ACID 表存储框架,允许用户在云存储之上实现湖仓架构,提供对海量数据集的可扩展访问,同时将 ETL、数据仓库和机器学习数据统一到一种表格文件格式中。作为现代机器学习堆栈的分布式数据帧库,Daft 为 Delta Lake 的统一存储提供统一的计算。
要使用 Daft 读取 Delta Lake 表,请安装带有 getdaft[deltalake] 额外功能的 Daft(这也会安装 deltalake Python 包)
pip install -U "getdaft[deltalake]"您可以使用新安装的 deltalake 库从 pandas DataFrame 创建一个本地 Delta Lake 表,然后您可以使用 Daft 读取该表
# Create a local Delta Lake table.
from deltalake import write_deltalake
import pandas as pd
df = pd.DataFrame({
"group": [1, 1, 2, 2],
"num": [1, 2, 3, 4,
"letter": ["a", "b", "c", "d"],
})
# This will write out two partitions, for group=1 and group=2.
write_deltalake("some-table", df, partition_by="group")只需提供表 URI,您就可以将 Delta Lake 表读取到 Daft DataFrame 中
# Read Delta Lake table into a Daft DataFrame.
import daft
df = daft.read_delta_lake("some-table")该表可以从您喜欢的云存储中读取,例如 AWS S3、GCP GCS 或 Azure Blob Storage。在底层,Daft 的高性能并行 I/O 层读取 Delta Lake 表的基础 Parquet 文件
# Read Delta Lake table in S3 into a Daft DataFrame.
table_uri = (
"s3://daft-public-datasets/red-pajamas/"
"stackexchange-sample-north-germanic-deltalake"
)
df = daft.read_delta_lake(table_uri)这个 RedPajama StackExchange 子集仅包含北日耳曼语(瑞典语、丹麦语和挪威语)的记录。它由三个 Parquet 文件(每种语言一个)组成,Daft 将并行读取。
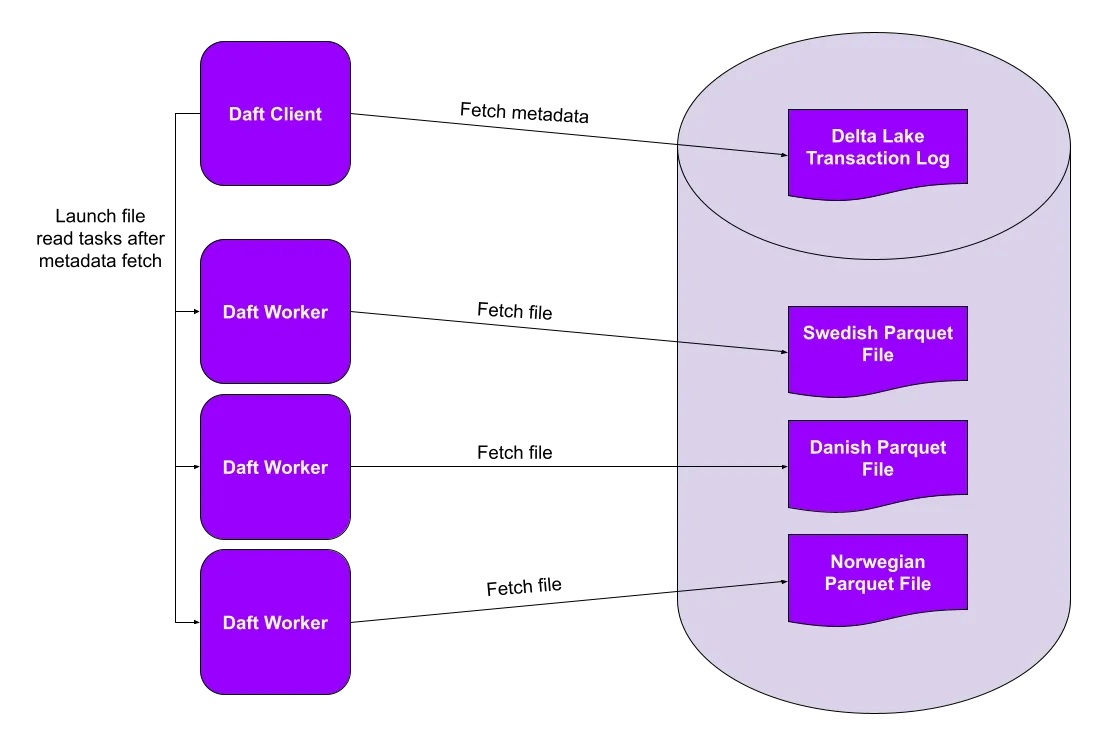
结合 Daft 的功能齐全的数据帧 API 和对多模态数据的一流支持,这个并行 Delta Lake 读取器无缝地将现代数据堆栈与当今的机器学习管道结合起来。在下一节中,我们将看到 Daft 针对湖仓量身定制的查询优化如何在大规模数据集上带来数量级的性能提升。
数据跳过优化——只读取您需要的数据
最快的读取是避免读取!智能优化器的查询引擎的一个显著优点是能够避免具体化查询不需要的数据。一个常见的例子是将 df.where() 中的过滤谓词推送到文件扫描中,在那里我们可以在完全将记录具体化到内存表之前删除不满足谓词的记录。对于像 Parquet 这样富含元数据的文件格式(包含列统计信息),我们甚至可能能够从元数据中确定我们不需要读取文件。
当与包含丰富分区和列统计元数据的湖仓结合使用时,我们可以进一步做到这一点,跳过文件甚至整个数据分区。最棒的是什么?这些元数据方便地存储在 Delta Lake 事务日志中,无论表中文件和分区的数量如何,都可以通过单个网络请求获取。这些数据跳过优化可以在读取具有选择性筛选器的大型表时带来数量级的性能提升。
让我们以以下简单查询为例,读取 RedPajama 数据集的 StackExchange 子集的 6 GB 样本,并对数据进行一些轻量级过滤,以返回问题分数高于 5 的英文数据
df = daft.read_delta_lake("s3://...")
df = df.where((df["language"] == "en") & (df["question_score"] > 5))
df.to_pandas()我们将比较从三个来源读取数据时的相对执行速度
-
单个 JSON 文件: Together AI 的工作人员为整个 StackExchange 数据集提供了一个 80 GB 的以换行符分隔的 JSON 文件。我们获取了 6 GB 的数据样本,并将其保存为 AWS S3 中的单个文件
s3://daft-public-datasets/red-pajamas/stackexchange-sample-jsonl/stackexchange.jsonl -
仅 Parquet 文件: 然后我们使用 Daft 将单个 JSON 文件重写为 Parquet 文件,没有任何分区或排序
s3://daft-public-datasets/red-pajamas/stackexchange-sample-parquet-2/ -
Delta Lake 表: 最后,我们使用 Delta Lake Python SDK 将 S3 中的 Parquet 文件写入 Delta Lake 表,按
"language"列分区,并按"question_score"列进行 z-order 排序s3://daft-public-datasets/red-pajamas/stackexchange-sample-deltalake-zorder/
与读取单个 JSON 文件的基线相比,从 Parquet 文件读取数据快 25 倍,从 Delta Lake 表读取数据快 50 倍。
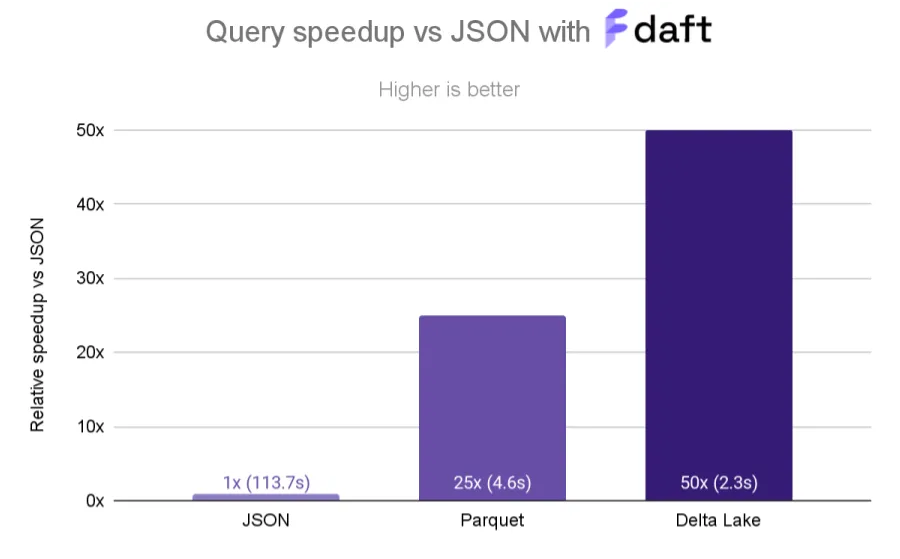
从 JSON 到 Parquet:113.7 秒 vs. 4.6 秒
正如预期的那样,从 JSON 文件读取耗时最长(迄今为止);它比从 Parquet 文件读取慢约 25 倍!这是因为 Parquet 的压缩和通过 Parquet 的“行组”进行并行访问的优化使 Daft 能够以极高的吞吐量访问数据。
从 Parquet 到 Delta Lake:4.6 秒 vs. 2.3 秒
由于 Delta Lake 表的分区和 z-order 排序,将数据存储在 Delta Lake 表中比 Parquet 进一步提速 2 倍。Daft 能够利用 Delta Lake 中的数据布局有效地跳过读取数据,最终对于此查询仅接触存储中 15% 的文件。
我们可以使用 df.explain() 来查看 Daft 在查询 Delta Lake 时在底层执行了哪些优化
df.explain(True)
# == Unoptimized Logical Plan ==
# * Filter: [col(language) == lit("en")] & [col(question_score) > lit(5)]
# |
# * PythonScanOperator: DeltaLakeScanOperator(None)
# | ...
# == Optimized Logical Plan ==
# * PythonScanOperator: DeltaLakeScanOperator(None)
# | Partitioning keys = [PartitionField(language#Utf8)]
# | Filter pushdown = col(question_score) > lit(5)
# | Partition Filter = col(language) == lit("en")
# | ...当使用 Delta Lake 执行此查询时,Daft 将 Filter 计划节点推送到 DeltaLakeScanOperator 中,然后 DeltaLakeScanOperator 能够利用此信息来确保只读取所需的数据
- Daft 将
Filter应用于它读取的每个文件,并在可用时利用文件级元数据执行过滤。由于数据按"question_score"列进行 z-order 排序(排序聚类),因此此数据将在过滤列上紧密聚类,Daft 可以轻松跳过与col(question_score) > lit(5)过滤器不匹配的整个文件/行组块。 - 我们的 Delta Lake 表按
"language"列分区,这允许 Daft 跳过读取与col("language") == "en"过滤器不匹配的整个分区。
本地基准测试
我们还将 Daft 从 S3 中的相同文件读取与其他本地查询引擎(pandas、Polars 和 DuckDB)进行了基准测试。Daft 与 Delta Lake、S3 和 Parquet 的原生集成使其能够以显著优势超越这些库。
所有基准测试均在 AWS EC2 c7g.4xlarge 机器上进行,该机器与我们数据所在的存储桶(us-west-2)位于同一区域。该机器拥有 16 个 CPU、128 GB 内存和 10 Gbps 网络带宽。有关本地基准测试代码,请参阅此 GitHub gist,并请注意我们使用了以下库版本
getdaft[deltalake]==0.2.19polars[deltalake]==0.20.15pandas==2.2.1duckdb==0.10.0deltalake==0.16.0pyarrow==15.0.2
对于单个 JSON 文件,Daft 比 Polars 快 3.5 倍,与 DuckDB 的速度大致相同。Pandas 在完成查询之前内存不足。
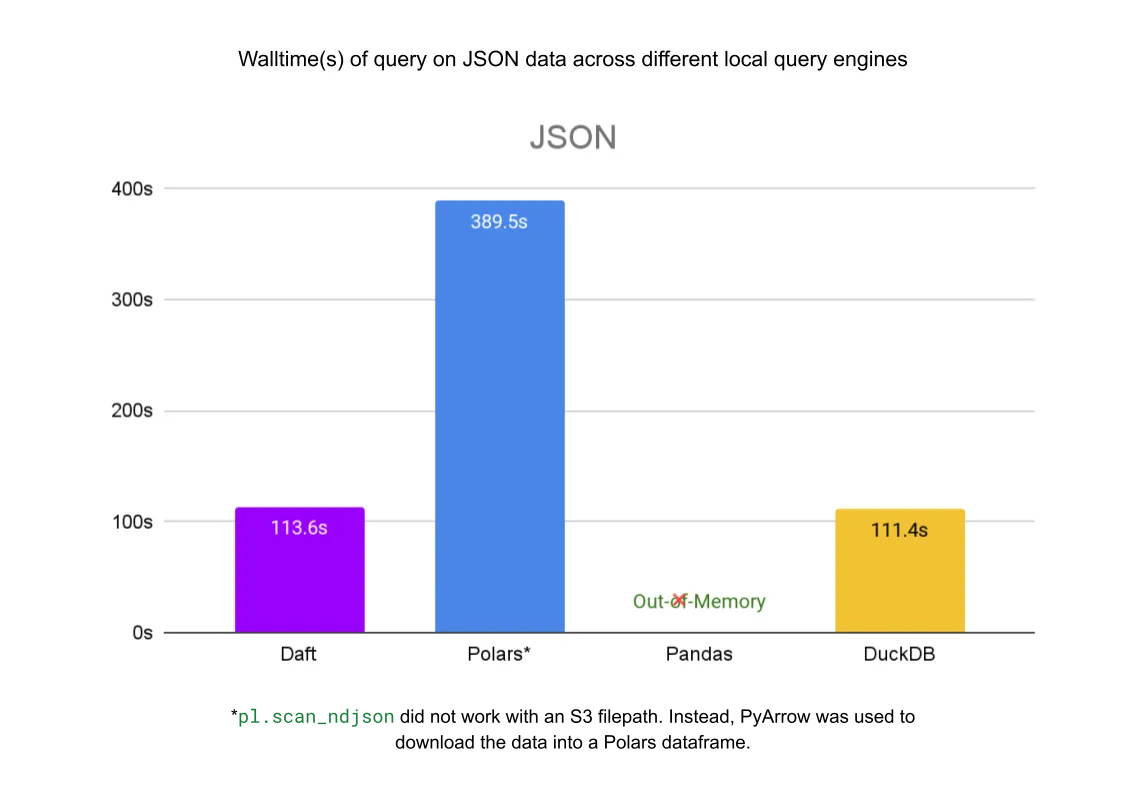
对于 Parquet 文件,Daft 比 Polars 快 2 倍,比 Pandas 快 4.7 倍,比 DuckDB 快 11 倍。
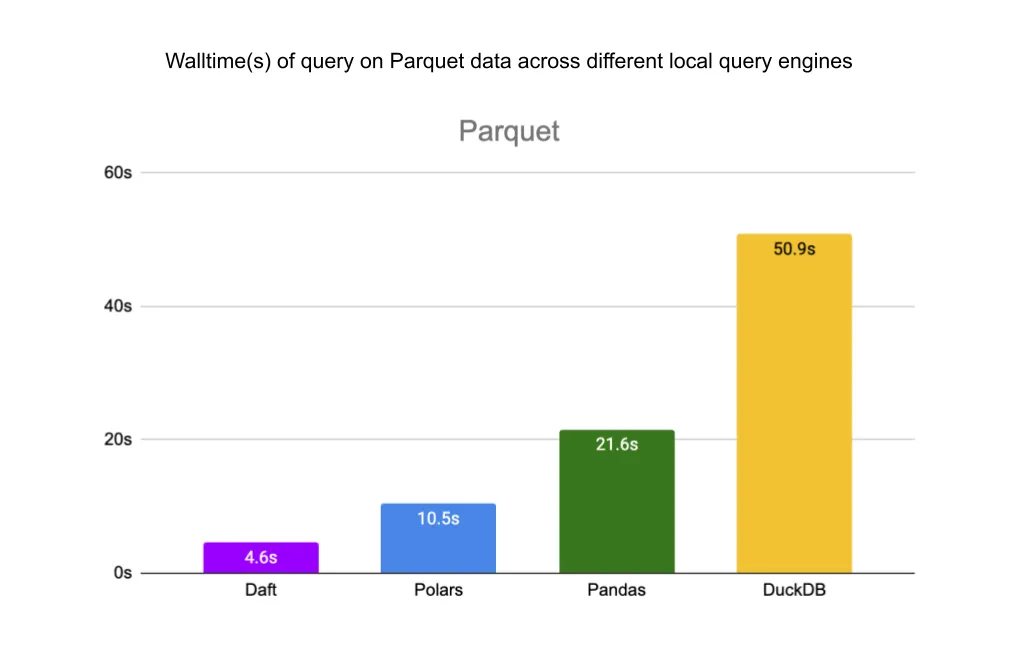
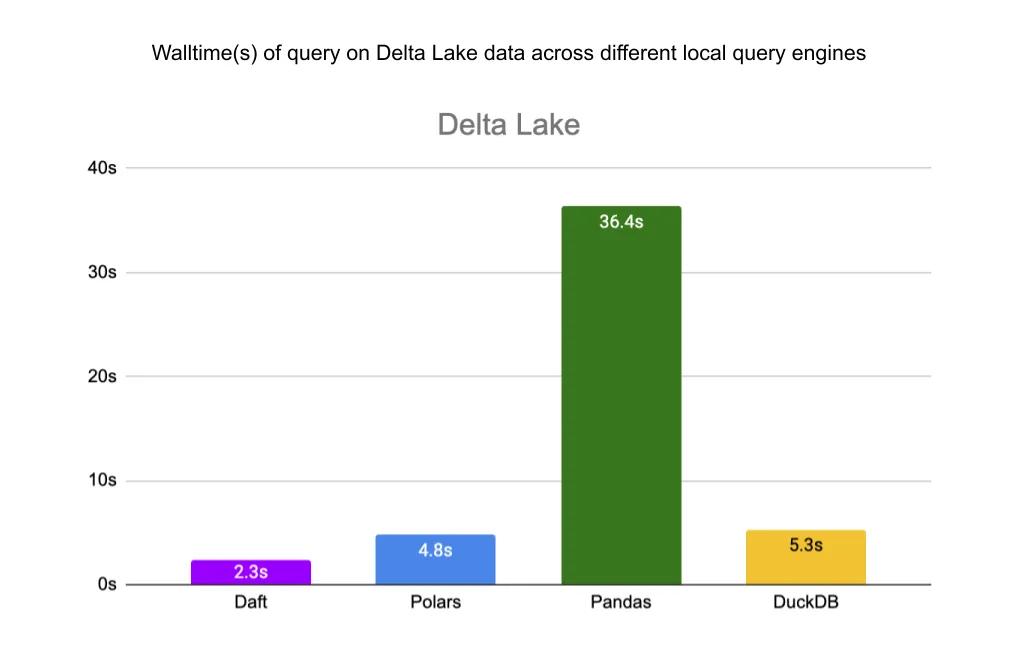
最后,对于 Delta Lake 表,Daft 比 Polars 快 2 倍,比 Pandas 快 15.8 倍,比 DuckDB 快 2.3 倍。
结论
Daft 实现了从 Delta Lake 快速且易于使用的并行读取,其数据跳过优化在大规模数据集上带来了数量级的性能提升。我们表明,在单机上,Daft 的并行读取器对于分区和 z-order 排序的 Delta Lake 表,性能优于 pandas 15.8 倍、DuckDB 2.3 倍 和 Polars 2 倍。
Daft 功能齐全的数据帧 API 和对多模态数据的一流支持,使得从目录和数据湖(仓)无缝读取数据、将其转换为机器学习就绪数据,并直接摄取到机器学习管道中成为可能,所有这些都在同一个集群上进行,无需中间持久化到存储。现代数据和机器学习堆栈,联合起来!
路线图
在未来的博客文章中,我们将深入探讨 Daft 读取无法适应单机的大规模 Delta Lake 表的能力,以及 Daft 与其他分布式查询引擎的比较。我们还将介绍一些已经推出的功能,例如 Daft 能够从 Databricks Unity Catalog 和 AWS Glue Data Catalog 读取 Delta Lake 表的能力。
我们也有一些关于 Delta Lake 的令人兴奋的新功能正在开发中。其中包括
如果您希望看到任何这些功能,请在链接的问题中告知我们,并加入我们的 Slack 社区以参与其中。
P.S.,如果您对探索现代数据和机器学习堆栈的交叉点感兴趣,我们的团队正在招聘!:)