Delta Lake 删除向量
作者:Nick Karpov
本博客介绍了 Delta Lake 表的全新删除向量表功能,并解释了删除向量如何加速修改湖仓中现有数据的操作。
要开始使用,您只需在 Delta Lake 表上设置以下表属性
ALTER TABLE tblName SET TBLPROPERTIES ('delta.enableDeletionVectors' = true);删除向量为 Delta Lake 协议引入了一种新范式,即“读时合并”(MoR),其中现有数据文件在 DELETE、UPDATE 和 MERGE 等更改操作期间保持不变。更改会单独写入,供读取器在实际读取数据时合并。因此称为“读时合并”。
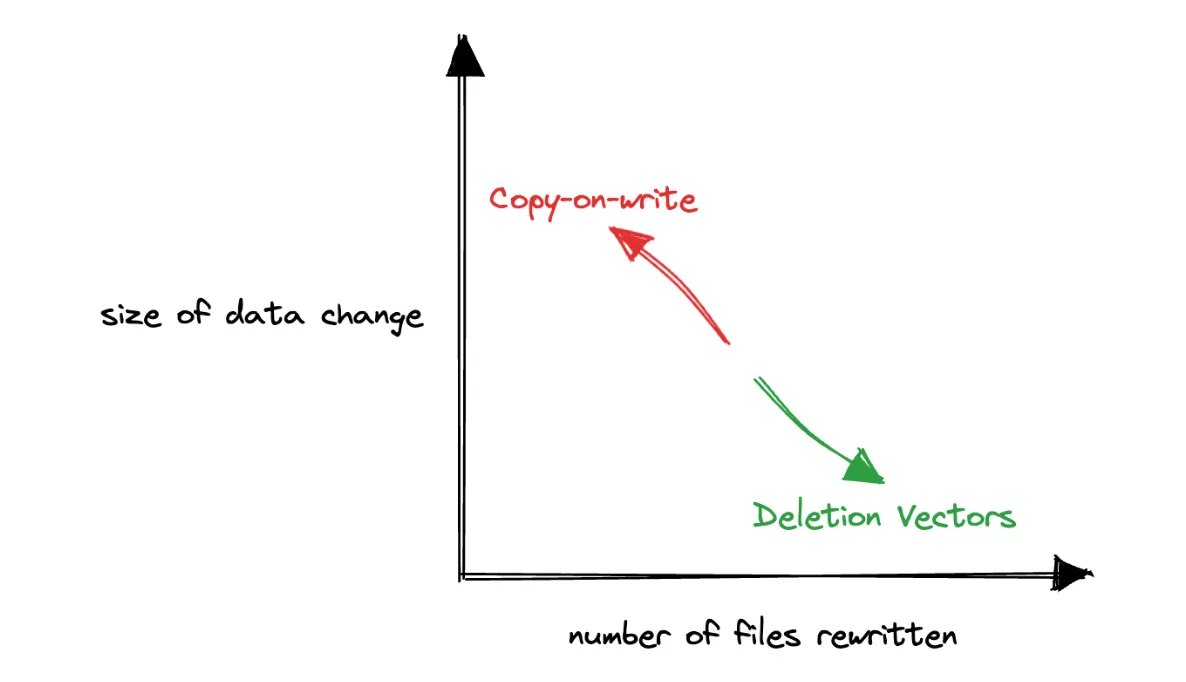
传统上,Delta Lake 协议只支持“写时复制”(CoW)范式,其中底层数据文件在每次更改时都会被重写。
这两种范式都不是所有用例的灵丹妙药,但总的来说,写时复制最适合不经常更新但经常读取的数据,而读时合并最适合频繁更新且广泛分散在表底层文件中的数据。
在这篇文章的其余部分,我们将展示为 Delta Lake 表启用删除向量表功能时需要考虑的主要优点和权衡。我们还将使用 DELETE 深入探讨删除向量的工作原理,DELETE 是最近发布的 Delta Lake 2.4 和 3.0 中第一个支持删除向量的更改操作。
Delta Lake 删除向量使删除操作更快
删除向量极大地提高了 Delta Lake 表上 DELETE 操作的性能。它们通过指定写入器将已删除行的位置与数据文件本身分开标记来实现这一点。这也被称为“软删除”。已删除行的位置以高度压缩的位图格式 RoaringBitmap 进行编码,该格式可以在以后单独压缩到数据文件中。
下面的热力图说明了 DELETE 命令的性能改进,随着涉及的文件数量和每个文件中删除的行数增加。我们发现,在几乎所有情况下,启用删除向量的 DELETE 性能都比传统的写时复制模式有了显著提高,尤其是在涉及的文件数量增加时(右下角)。这种关系具有直观的意义,因为传统的写时复制模式必须重写越来越多的文件,而带有删除向量的读时合并模式则推迟了重写成本。
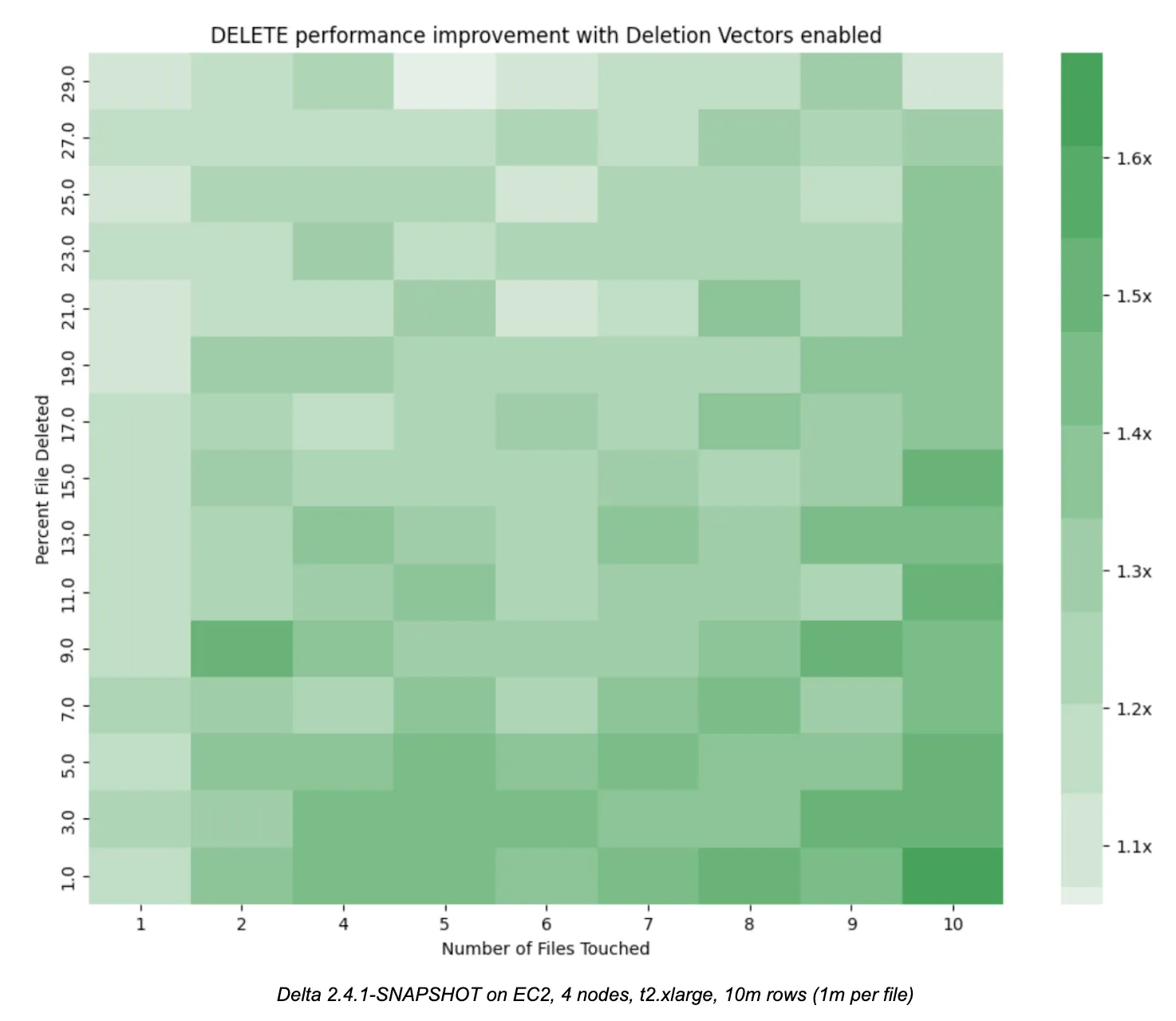
用于生成这些结果的代码和数据可在随附的笔记本中找到。您可以在本地机器上轻松运行它以确认结果。在大规模数据中,数据量可能更大,文件数量更多,云存储的成本更高,效益只会更好。
我何时应该启用删除向量?
Delta Lake 中删除向量的设计和实现旨在使删除向量成为大多数工作负载的明显选择。尽管如此,总有一些重要的权衡需要理解和考虑。
DELETE 操作通过避免急于重写文件所节省的时间,最终会被读取器和压缩命令消耗掉。当您在 Delta Lake 表上启用删除向量表功能时,您会将更改数据所需的成本摊销或分散。
为了充分利用此表功能,您应该考虑以下几点
-
写入频率和延迟 SLA: 当写入频率高,或需要低写入延迟时,请使用删除向量,特别是对于在传统写时复制模式下导致大量写入放大的小数据更改。在写入频率低且延迟要求灵活的场景中,删除向量可能不那么有利。
-
读取频率和延迟 SLA: 在高读取场景中,使用删除向量时要谨慎,因为处理额外的删除向量文件所需的额外执行时间累计成本可能会很高。
-
数据布局和更改分布: 当数据更改分散在许多文件中时,删除向量表现出色,这使得传统写时复制方法带来的写入放大变得异常昂贵。请特别注意数据更改的匹配谓词。Levi 库提供了帮助方法,可以轻松访问底层文件统计信息。
考虑这些维度如何随时间变化也很重要。具有持续更改的高使用率表将具有不断演变的数据布局,因此您可能需要相应地调整策略。
为了解决高使用率表布局演变的这种动态,Databricks 推出了用于更新的预测性 I/O,它利用机器学习智能地优化数据读取和写入,无需用户干预。请参阅官方公告和文档,了解更多关于 Databricks 上用于更新的预测性 I/O。
Delta Lake 中删除向量的工作原理
让我们探讨一下此表功能如何与 Spark Delta Lake 连接器协同工作。
考虑一个基础 Delta Lake 表 `daily_user_actions`,它表示我们的用户每天可以执行的可能操作。每个用户每天只执行一个操作,总共 10 天。该表按天分区,因此有 10 个分区,每个分区包含一个文件
SELECT * FROM daily_user_actions WHERE day = 9
+---+-------+-------------+
|day|user_id| action|
+---+-------+-------------+
| 9| 0|profileUpdate|
| 9| 1| post|
| 9| 2| reply|
...
├── _delta_log
│ └── 00000000000000000000.json
├── day=0
│ └── part-00000-805a80ba-1086-4ecd-97eb-d7ff92359f13.c000.snappy.parquet
├── day=1
│ └── part-00000-0e02935c-f84d-4b8a-ae09-db76f74a44ff.c000.snappy.parquet
├── day=2, day=3, etc...假设我们需要删除 user_id 为 3 的用户的所有操作。
DELETE FROM daily_user_actions WHERE user_id = 3由于该表按天分区,传统的写时复制模式会在每个分区中生成新的 Parquet 数据文件。换句话说,要删除单个用户,我们需要重写整个表!
├── _delta_log
│ ├── 00000000000000000000.json # CREATE TABLE ...
│ └── 00000000000000000001.json # DELETE FROM .. WHERE user_id = 3
├── day=0
│ ├── part-00000-805a80ba-1086-4ecd-97eb-d7ff92359f13.c000.snappy.parquet
│ └── part-00001-6750aa5c-ff6f-4579-aa55-7b4c2ad0907e.c000.snappy.parquet
├── day=1
│ ├── part-00000-0e02935c-f84d-4b8a-ae09-db76f74a44ff.c000.snappy.parquet
│ └── part-00000-7e750ace-9b85-431d-bc20-896e0a856347.c000.snappy.parquet
├── day=2, day=3, etc. ...因此,虽然时间分区表对于可以利用数据时间局部性的分析非常有用,但它们在非时间维度(如用户 ID)上更新时也出了名的昂贵,正如我们在上面的文件列表中所看到的。
启用删除向量表功能后,我们的数据和日志目录列表将如下所示
├── _delta_log
│ ├── 00000000000000000000.json # CREATE TABLE ...
│ ├── 00000000000000000001.json # ALTER TABLE enableDeletionVectors ...
│ └── 00000000000000000002.json # DELETE FROM .. WHERE user_id = 3
├── day=0
│ └── part-00000-54b2c529-1314-42d7-b5e3-10b43e1892ea.c000.snappy.parquet
├── day=1
│
│ ...
│
├── day=9
│ └── part-00000-973fb3cf-4d0b-4bc9-adf4-5c3bed552ecb.c000.snappy.parquet
└── deletion_vector_856b2bfe-81b7-4d86-ac9a-25d6a9bb272a.bin这次只写入了一个新文件,即删除向量,以表示跨所有分区的删除!将来自多个数据文件的行级别删除标记在一个删除向量中是一项重要的优化,可以避免写入许多小的删除向量文件。
仔细查看日志目录中最新的 JSON 提交条目会发现,每个包含 `user_id = 3` 的数据文件现在都带有一个 `remove` 操作。
{
"remove": {
"path": "day=0/part-00000-54b2c529-...parquet",
"deletionTimestamp": 1684789501794,
"dataChange": true,
"extendedFileMetadata": true,
"partitionValues": {
"day": "0"
},
"size": 802
}
}
这是因为,虽然受影响的数据文件仍然有效,但它们以前的元数据条目没有引用新写入的删除向量文件,因此这些条目必须标记为无效。取而代之的是,为每个受影响的文件添加了一个更新的元数据条目,形式如下
{
"add": {
"path": "day=0/part-00000-54b2c529-...parquet",
...
"deletionVector": {
"storageType": "u",
"pathOrInlineDv": "G>&jrFWXvdTEpD^SK<Jc",
"offset": 85,
"sizeInBytes": 34,
"cardinality": 1
}
}
}add 操作现在有一个嵌套的描述符对象,其键为 `deletionVector`,其中包含元数据以帮助读取器正确处理删除向量。
- storageType 指示删除向量的存储方式:相对、绝对或内联。Delta 事务日志协议支持将删除向量直接序列化到元数据中,而不是作为单独的文件。
- pathOrInlineDV 在使用“内联”存储选项时,包含删除向量文件的位置或序列化的删除向量本身
- offset 是此特定文件的已删除行索引的起始位置。这就是单个删除向量如何支持来自多个数据文件的已删除行索引。
- cardinality 是此删除向量标记的行数
完整的删除向量规范超出了本文的范围。更多详细信息可在官方的Delta 事务日志协议和删除向量高级设计文档中找到。
如何应用或压缩删除向量?
删除向量最终必须应用于底层 Parquet 文件。这是写入器推迟的步骤,它使删除向量的写入速度比传统的写时复制模式快得多。
为了重写具有关联删除向量的文件,我们引入了新的 `REORG TABLE` 命令
REORG TABLE daily_user_actions APPLY (PURGE);
REORG TABLE daily_user_actions
WHERE day >= current_timestamp() - INTERVAL '1' DAY
APPLY (PURGE);将删除向量应用于其底层数据文件会使数据文件更小,因此 `REORG TABLE` 也足够智能,可以将小文件合并成更少的大文件,类似于 `OPTIMIZE`。事实上,如果我们检查 `REORG TABLE` 生成的 JSON 提交,我们会发现它在底层利用了 `OPTIMIZE` 命令。
{
"commitInfo": {
"operation": "OPTIMIZE",
...
}注意:REORG TABLE 不会删除删除向量或数据文件本身。运行 VACUUM 以物理删除文件。
功能状态、限制和路线图
在之前的 Delta Lake 2.3 版本中,我们引入了对启用删除向量的表的完整读取支持。最新的 Delta Lake 2.4 和 3.0 版本在此读取支持的基础上,增加了对 DELETE 命令的写入支持。
在您的 Delta Lake 表上启用删除向量表功能是不可逆的,并且该表只能由支持读取(Delta Spark 为 2.3)的 Delta Lake 客户端读取。
在启用删除向量的表上,UPDATE 和 MERGE 命令在 2.4 中仍然受支持,但默认为传统的写时复制模式。社区正在积极开发对这些命令的支持,我们很高兴能在未来的版本中包含它们!
结论
在这篇文章中,我们介绍并探讨了 Delta Lake 表的全新删除向量表功能。
删除向量是 Delta Lake 的一项重大进步,引入了读时合并(MoR)范式,以实现更高效的写入。与传统的写时复制方法不同,MoR 在修改期间保持现有数据文件不变,仅在读取时合并更改。
删除向量对于应用于缺乏可通过分区利用的自然顺序的数据,或当所需更改远小于实际表时,特别有效。
最终,每种范式都有其自身的优势,是否启用删除向量取决于您独特的数据需求和用例。
您可以通过查看官方文档、Delta 事务日志协议中的删除向量部分以及原始删除向量高级设计文档来了解更多关于删除向量的信息。