Delta Lake Z 排序
这篇博文解释了如何对 Delta 表进行 Z 排序,以及这种设计模式如何显著加快您的查询速度。
对数据进行 Z 排序会重新组织存储中的数据,并允许某些查询读取更少的数据,从而运行得更快。当数据适当地排序后,可以跳过更多的文件。
Z 排序对于多列的排序尤为重要。如果您只需要按单列排序,那么简单的排序就足够了。如果有多个列,但我们总是/只查询这些列的公共前缀,那么分层排序就足够了。当查询一列或多列时,Z 排序效果很好。您稍后会看到一个具体的示例,以进一步说明何时 Z 排序更适合。
让我们从一个简单的示例开始,然后探讨如何为您的数据制定最佳的 Z 排序策略。如果您想跟着计算过程,请参阅此笔记本。
Delta Lake Z 排序示例
让我们使用 h2o 基准测试中的数据集,并演示 Z 排序数据如何使查询更快。
假设您有一个包含九列的十亿行数据集,如下所示
+-----+-----+------------+---+---+------+---+---+---------+
| id1| id2| id3|id4|id5| id6| v1| v2| v3|
+-----+-----+------------+---+---+------+---+---+---------+
|id016|id046|id0000109363| 88| 13|146094| 4| 6|18.837686|
|id039|id087|id0000466766| 14| 30|111330| 4| 14|46.797328|
|id095|id078|id0000584803| 56| 92|213320| 1| 9|63.464315|
+-----+-----+------------+---+---+------+---+---+---------+您想运行以下查询:select id1, sum(v1) as v1 from the_table where id1 = 'id016' group by id1。
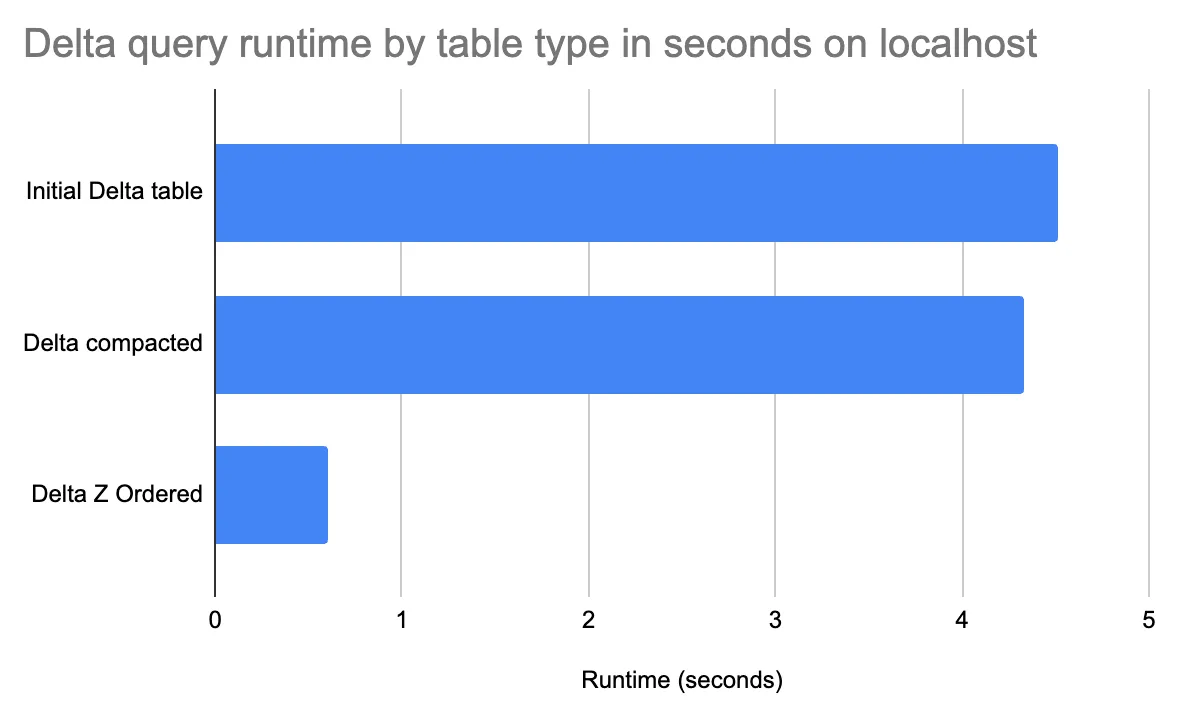
Delta 表最初存储在 395 个文件中,其中 id1 = 'id016' 的行分散在所有文件中,因此在运行查询时无法跳过任何文件。
最初创建 Delta 表时,运行查询需要 4.51 秒
(
spark.read.format("delta")
.option("versionAsOf", "0")
.load(delta_path)
.createOrReplaceTempView("x0")
)
spark.sql(
"select id1, sum(v1) as v1 from x0 where id1 = 'id016' group by id1"
).collect()现在让我们压缩 Delta 表,使其不包含不必要的小文件。
delta_table = DeltaTable.forPath(spark, delta_path)
delta_table.optimize().executeCompaction()压缩后的 Delta 表包含 27 个文件。现在查询只需要 4.33 秒即可运行。
(
spark.read.format("delta")
.option("versionAsOf", "1")
.load(delta_path)
.createOrReplaceTempView("x1")
)
spark.sql(
"select id1, sum(v1) as v1 from x1 where id1 = 'id016' group by id1"
).collect()在这么小的数据集上,将 395 个小文件压缩成 27 个大文件对查询运行时间没有太大帮助。在拥有更多小文件的较大数据集上,压缩可以显著加快查询运行时间。
现在让我们按 id1 对数据进行 Z 排序,这样 id1 = 'id016' 的行就会被组合在一起,而不是分散在所有文件中。
(
delta.DeltaTable.forPath(spark, table_path)
.optimize()
.executeZOrderBy("id1")
)现在我们只有 25 个文件中的 1 个文件包含 id1 = 'id016' 的行。现在查询执行只需要 0.6 秒。
(
spark.read.format("delta")
.option("versionAsOf", "2")
.load(delta_path)
.createOrReplaceTempView("x2")
)
spark.sql(
"select id1, sum(v1) as v1 from x2 where id1 = 'id016' group by id1"
).collect()Z 排序数据可以显著提高查询性能。此图显示了按 Delta 表版本划分的查询时间
文件跳过为何能提高查询性能
从存储传输数据到内存代价高昂,因此最大程度地减少传输的数据量可以加快查询速度。
Delta 表在事务日志中存储每个文件的元数据,引擎在运行查询时可以查阅这些元数据,并利用它们跳过那些不包含查询所需数据的文件。
为了实现这一点,Delta 表存储了每个文件中列的最小值/最大值。让我们可视化存储的 id1 列的最小值/最大值统计信息如何用于执行文件跳过。
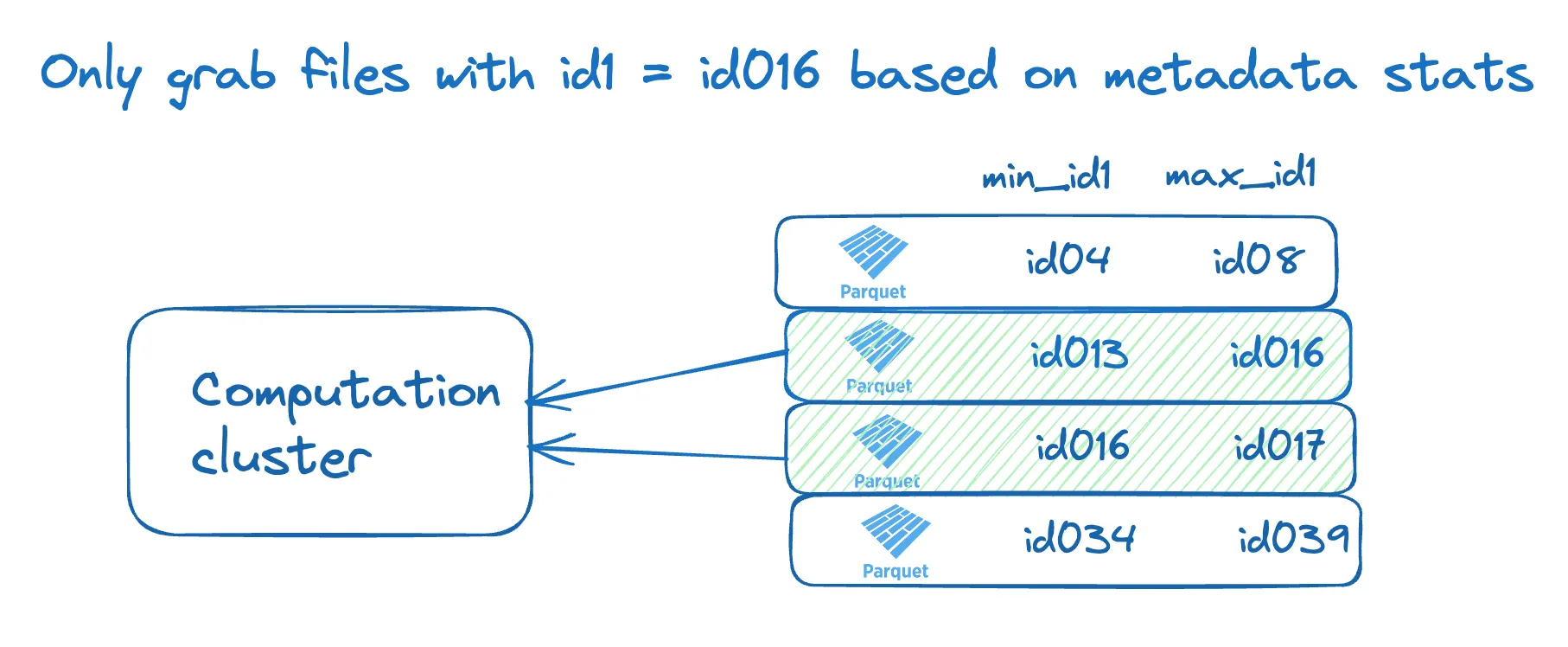
当读取 id1=id016 的数据时,我们只需要获取那些包含在 min_id1 和 max_id1 值之间包含 'id016' 行的文件。我们知道,min_id1=id034 的文件不包含与我们查询相关的任何数据行。
Z 排序有助于您的查询运行得更快,因为它使数据更有可能被跳过。
Delta Lake 按多列 Z 排序
您还可以对 Delta 表的多个列进行 Z 排序。让我们看看一组查询模式以及与对不同列进行 Z 排序相关的权衡。
假设您经常运行以下类型的查询
- query_a:
select id1, sum(v1) as v1 from x1 where id1 = 'id016' group by id1 - query_b:
select id2, sum(v1) as v1 from x1 where id2 = 'id047' group by id2 - query_c:
select id1, id2, sum(v1) where id1 = 'id016' and id2 = 'id047' group by id1, id2
对于这种查询模式,对 id1 和 id2 进行 Z 排序可能不错。以下是如何运行 Z 排序命令
(
delta.DeltaTable.forPath(spark, table_path)
.optimize()
.executeZOrderBy("id1", "id2")
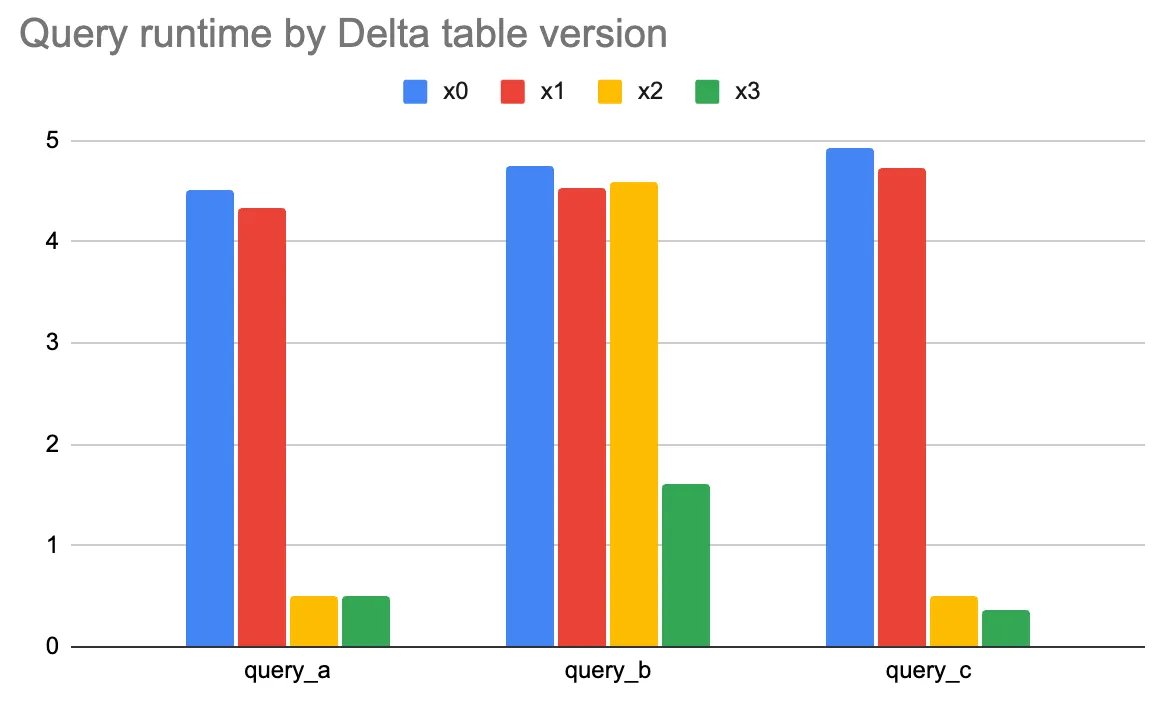
)让我们观察我们的 Delta 表的四个版本上的查询运行时间。
- x0:最初创建的 Delta 表
- x1:已压缩的 Delta 表
- x2:按
id1Z 排序的 Delta 表 - x3:按
id1和id2Z 排序的 Delta 表
如前所述,在此示例中,由于数据集相对较小,小文件压缩帮助不大。当存在大量小文件时,压缩可以显著加快查询速度。
对 Delta 表按 id1 进行 Z 排序可以改进基于 id1 过滤的查询,但对仅基于 id2 过滤的 query_b 则没有帮助。对表按 id1 和 id2 进行 Z 排序有助于过滤 id1、id2 以及 id1 和 id2 两者的查询。
对于这种查询模式,按 id1 和 id2 进行 Z 排序可以为所有查询提供不错的性能提升。仅按 id1 进行 Z 排序并不能加快 query_b 的速度。
需要注意的是,对于更大的数据集,仅按 id1 Z 排序的 Delta 表的 query_a 会运行得更快,而按 id1 和 id2 Z 排序的 Delta 表的 query_a 则会运行得更慢。按多列进行 Z 排序会限制 id1 数据共置的能力。Z 排序有其权衡,因此在对数据进行 Z 排序时,分析查询模式并选择正确的列至关重要。
Delta Lake Z 排序 vs. Hive 风格分区
Delta Lake Z 排序和 Hive 风格分区都是将相似数据分组到相同文件中的技术,以便在执行特定查询时只读取文件的一个子集。
Hive 风格分区将相似数据存储在存储中的同一目录中。Z 排序将相似数据分组到同一文件中,而无需创建目录。
假设您希望重新排列 Delta 表,以便以下查询执行得更好:select id2, sum(v1) as v1 from x1 where id2 = 'id047' group by id2。
您可以按 id2 进行 Z 排序,也可以按 id2 进行分区。
按 id2 分区保证了完全的数据分离。对于 id2 中的每个值,将有一个单独的目录,因此 id2=id07 目录将只包含具有该确切数据值的行。
完全的数据分离有时非常好,但也可能成为一个负担。当您按具有太多不同值(即高基数列)的列进行分区时,可能会创建大量小文件,具体取决于数据集的大小和倾斜情况。
更新在高基数列上分区的DS数据集会迅速加剧小文件问题。
决定最佳数据布局取决于查询模式、数据量、列基数和数据倾斜。一般来说,您不应该对小于一 TB 的表进行分区。您也不应该按分区数据小于 1 GB 的列进行分区。如果您正在分区一个频繁更新的表,请测量创建的新文件数量,以评估小文件问题的潜在影响。
Hive 风格分区不一定会导致小文件泛滥。假设您每 8 小时将数据写入按 ingestion_date 列分区的表。这种写入不一定会比写入未分区的数据湖产生更多的小文件。如果您将数据写入按 medical_code 列(具有 10,000 个不同的值)分区的表,那么每次写入操作最多可以创建 10,000 个文件,小文件问题可能会像滚雪球一样越来越大。
您始终可以进行 Z 排序并增量追加,以避免 Hive 风格分区创建的一些小文件问题。
Hive 风格分区和 Z 排序并非互斥,因为您也可以同时进行。
Delta Lake Z 排序与 Hive 风格分区
您可以对存储中的 Delta 表进行分区,并在给定分区内对数据进行 Z 排序。
例如,您可以按 ingestion_date 进行分区,并按 user_id 进行 Z 排序。这种设计将是随着时间推移运行用户活动查询的绝佳方式。
这篇帖子没有涵盖 Z 排序与数据分区的复杂细节。我们将在未来的帖子中详细讨论这个主题。
Z 排序何时不会提高查询性能
Z 排序只有在能帮助您跳过文件时才能提高查询性能。
让我们看看以下查询,它不会受益于我们按 id1 进行 Z 排序的 Delta 表:select id3, sum(v1) as v1 from x1 group by id3
对 id1 进行 Z 排序不会改善此特定查询的运行时间。
关键是选择正确的列进行 Z 排序,才能为最常见的查询模式获得性能提升。
结论
Z 排序是一种强大的数据排序方式,可将数据持久化存储,以便引擎在运行查询时可以跳过更多文件,从而使查询执行更快。
Z 排序是 Delta Lake 的一项惊人功能,在数据湖中不可用。
这篇博文向您展示了如何按一列或多列对数据进行 Z 排序。您了解了在对数据进行 Z 排序时要使用的最佳列,以及在对多列进行 Z 排序时的权衡。
您还学习了如何使用 Z 排序以及如何替代 Hive 风格分区。Z 排序和 Hive 风格分区之间的权衡很复杂,我们将在未来的文章中详细介绍。Delta 表的架构与数据湖从根本上不同,改变了从业者分区的成本/效益方程。