Delta Lake 2.3.0 发布
Delta Lake 仍然是湖仓一体的最佳开源存储格式。Delta 2.0 版本取得了巨大成功并得到了广泛应用,我们将在这一成功的基础上继续前进。
通过 2.3 版本的发布,Delta 现已拥有更多功能,使部署湖仓一体变得超级容易。
这个新版本使从 Iceberg 迁移到 Delta Lake 更容易,可以编写高级的 MERGE 语句逻辑,查询变更数据流等等。以下列出的功能只是本次发布中包含的众多功能中的一小部分——更多内容请参阅Delta Lake 2.3 发布说明。
本文将向您展示为何以及如何升级到 Delta 2.3 并利用这些惊人的功能。
Delta Lake 浅层克隆 (SHALLOW CLONE)
Delta Lake SHALLOW CLONE 命令在不移动现有数据文件的情况下,在新位置创建 Delta 表。
您可以创建 Parquet 表、Delta 表甚至 Iceberg 表的浅层克隆。
让我们来看看 Delta 表的架构,以更好地理解浅层克隆的工作原理。Delta 表通常由 Parquet 文件和共同定位的事务日志组成,如下图所示。
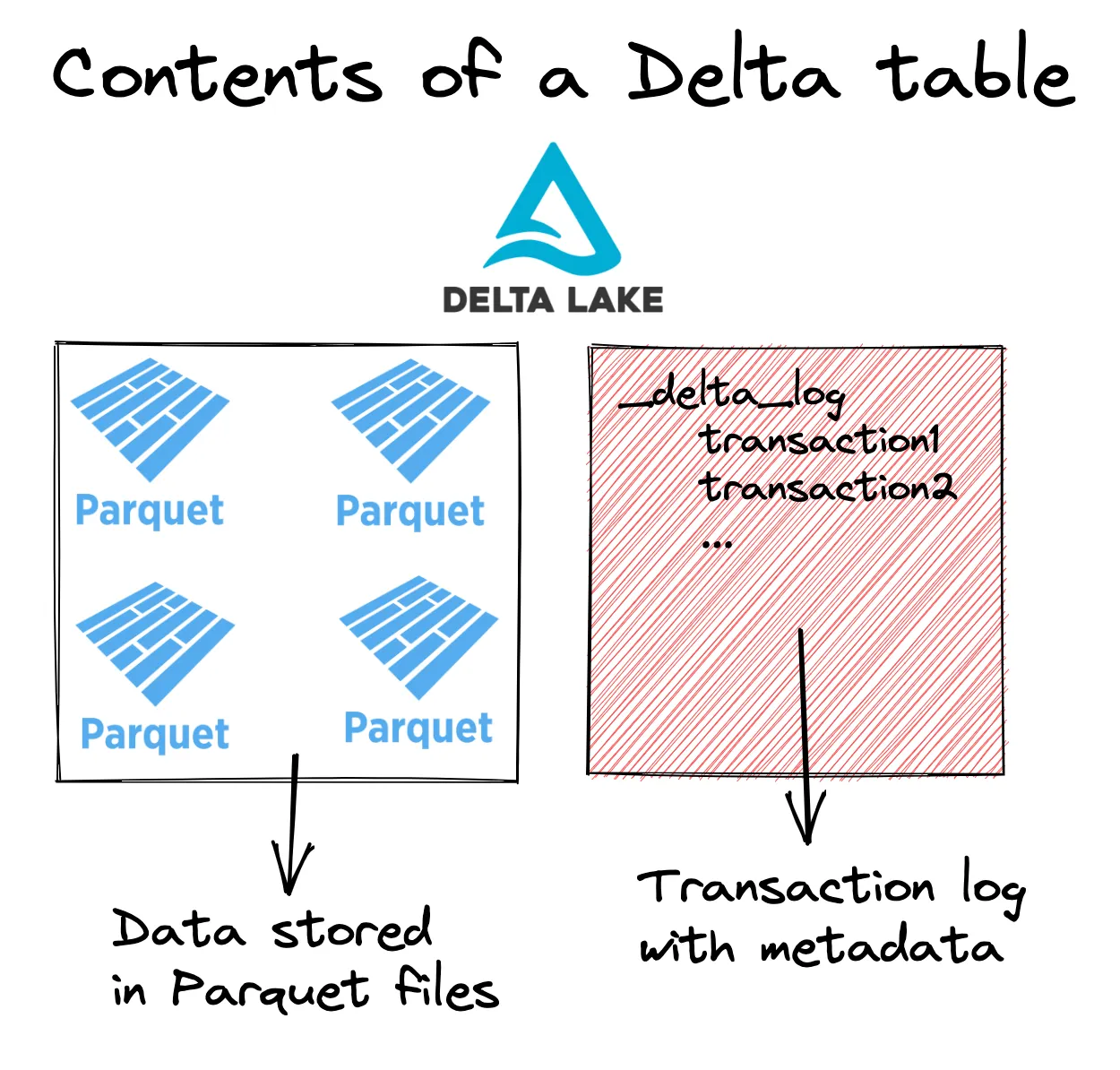
让我们创建一个 Delta Lake 表,然后将其克隆到另一个位置。首先使用 PySpark 创建一个 Delta Lake 表。
data = [(0, "Bob", 23), (1, "Sue", 25), (2, "Jim", 27)]
df = spark.createDataFrame(data).toDF("id", "name", "age")
df.write.format("delta").save("/tmp/my_people")Delta 表包含元数据文件和以 Parquet 格式存储的数据,如下所示:
/tmp/my_people
├── _delta_log
│ └── 00000000000000000000.json
├── part-00000-b33f79ee-473d-4b98-ad79-a8b087ae5c50-c000.snappy.parquet
├── part-00003-3de8e2cd-bb73-4ed6-af3c-2d61911670d0-c000.snappy.parquet
├── part-00006-206bd2a6-bc3f-47d4-9b6c-e9fb8d317732-c000.snappy.parquet
└── part-00009-1c687cd5-4515-4966-9aeb-27e03bc00818-c000.snappy.parquet现在将表克隆到另一个位置。
spark.sql("CREATE TABLE delta.`/tmp/my_cloned_people` SHALLOW CLONE delta.`/tmp/my_people`")对克隆运行查询以确保一切正常。
spark.read.format("delta").load("/tmp/my_cloned_people").show()
+---+----+---+
| id|name|age|
+---+----+---+
| 2| Jim| 27|
| 1| Sue| 25|
| 0| Bob| 23|
+---+----+---+克隆表只包含元数据文件,不包含任何数据文件。
/tmp/my_cloned_people
└── _delta_log
├── 00000000000000000000.checkpoint.parquet
├── 00000000000000000000.json
└── _last_checkpoint当您希望继续更新源表但想读取或写入其独立副本时,浅层克隆非常有用。例如,浅层克隆可用于在生产表上进行实验和测试。创建浅层克隆意味着您可以在克隆表上运行任意操作,而不会损坏生产表或中断任何生产工作负载。
我们将在未来的博客文章中深入探讨克隆的细节以及它如何与 CONVERT TO DELTA 一起使用。
将 Iceberg 转换为 Delta Lake
正如《分析和比较湖仓存储系统》论文中所解释的,公司正在寻求从 Iceberg 迁移到 Delta Lake,以获得更好的性能和可靠性。
在 Delta 2.3 中,您可以使用 CONVERT TO DELTA 轻松地将 Iceberg 表转换为 Delta Lake 格式。它执行一次性转换为 Delta Lake 格式,并支持转换 Parquet 表。
假设您有一个名为 some_table 的 Iceberg 表,存储在 /some/path/some_table。您可以使用以下命令将其转换为 Delta 表:
CONVERT TO DELTA iceberg.`/some/path/some_table`由于 Iceberg 表和 Delta 表都由元数据事务日志和以 Parquet 文件存储的数据组成,因此从 Iceberg 转换为 Delta Lake 是一个原地操作。转换 Iceberg 表只是创建 Delta 事务日志,而不会重写任何数据文件。将 Iceberg 表转换为 Delta Lake 后,它将看起来像这样:
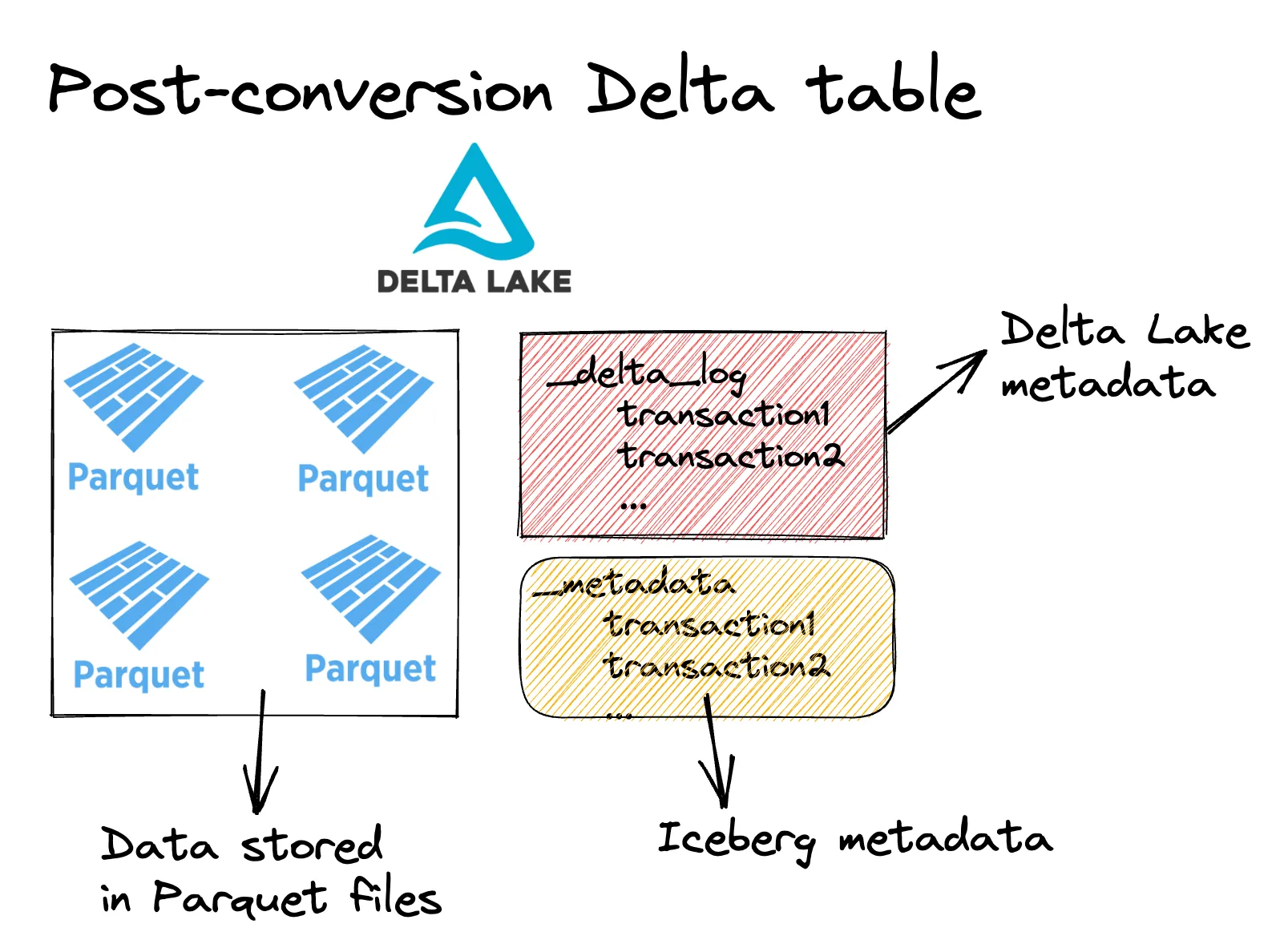
执行 CONVERT TO DELTA 后,该表现在是一个 Delta 表,可以利用所有出色的 Delta Lake 功能。请注意,任何后续的 Delta 操作都可能损坏 Iceberg 源表,并且不会更新 Iceberg 元数据。Convert to Delta 最适合用于一次性转换,即您不再计划以源格式更新源表的情况。
Merge 命令的“when not matched by source”子句
merge 命令可以使用源表中的信息更新现有 Delta 表(目标)。以前只支持两个子句:“when matched”(允许更新或删除目标行)和“when not matched”(允许插入源行)。“When not matched by source”使您能够 UPDATE 或 DELETE 目标表中没有对应源表记录的行。
假设您有以下目标表,其中包含客户、他们的年龄、上次来店时间以及一个活跃标志。如果客户在上个月到过您的商店,则认为他们是活跃的。
想象一下您正在 2023 年 4 月 12 日运行此分析。这是现有的客户表。
+---+----+---+----------+--------+
| id|name|age| last_seen| status|
+---+----+---+----------+--------+
| 0| Bob| 23|2022-01-02|inactive|
| 1| Sue| 25|2023-04-05| active|
| 2| Jim| 27|2023-02-07| active| # should be inactive now
+---+----+---+----------+--------+您希望使用以下信息更新 Delta 表:
+---+-----+---+------------+
| id| name|age|current_date|
+---+-----+---+------------+
| 0| Bob| 23| 2023-04-12| # update existing row
| 3|Sally| 30| 2023-04-12| # new row
+---+-----+---+------------+以下是所需更改的摘要:
- Bob 需要更新
last_seen并变为active - Sue 不应更改
- Jim 应被设置为
inactive - Sally 应被添加并设置为
active
使用新的“when not matched by source clause”,这是允许此合并逻辑的 Delta Lake 代码:
(
customers_table.alias("target")
.merge(new_df.alias("source"), "target.id = source.id")
.whenMatchedUpdate(
set={"target.last_seen": "source.current_date", "target.status": "'active'"}
)
.whenNotMatchedInsert(
values={
"target.id": "source.id",
"target.name": "source.name",
"target.age": "source.age",
"target.last_seen": "source.current_date",
"target.status": "'active'",
}
)
.whenNotMatchedBySourceUpdate(
condition="target.last_seen <= (current_date() - INTERVAL '30' DAY)",
set={"target.status": "'inactive'"},
)
.execute()
)检查以确保 MERGE 已正确执行:
DeltaTable.forPath(spark, "tmp/customers").toDF().show()
+---+-----+---+----------+--------+
| id| name|age| last_seen| status|
+---+-----+---+----------+--------+
| 0| Bob| 23|2023-04-12| active|
| 1| Sue| 25|2023-04-05| active|
| 2| Jim| 27|2023-02-07|inactive|
| 3|Sally| 30|2023-04-12| active|
+---+-----+---+----------+--------+新的 whenNotMatchedBySourceUpdate 对于将 Jim 的状态更新为 inactive 至关重要。如果没有“when not matched by source”子句,相同的操作将需要对表进行两次单独的写入:(1)一个 MERGE 操作,用新信息更新表;(2)一个 UPDATE 操作,将 30 天内未到店的客户状态设置为 inactive。
CREATE TABLE LIKE 创建空 Delta 表
CREATE TABLE LIKE 可以轻松地创建一个新表,使其具有与现有表相同的列和 schema。
让我们创建一个 Delta 表,然后创建另一个具有相同 schema 的表。
首先创建一个 Delta 表:
df = spark.createDataFrame(
[(0, "Bob", "Loblaw", 23), (1, "Sue", "Grafton", None), (2, "Jim", "Carrey", 61)]
).toDF("id", "first_name", "last_name", "age")
df.write.format("delta").saveAsTable("default.famous_people")现在使用 CREATE TABLE LIKE 创建一个具有相同列和数据类型的空表。
spark.sql("CREATE TABLE famous_people_duplicate LIKE famous_people")我们可以确认该表是空的:
spark.sql("select * from famous_people_duplicate").show()当您想要精确复制表 schema 而无需手动输入所有列名和列类型代码时,CREATE TABLE LIKE 是一个方便的功能。
在 SQL 查询中支持读取变更数据流 (CDF)
Delta Lake 支持变更数据流 (CDF),它跟踪 Delta 表随时间变化的行级更改。CDF 对于构建智能增量更新或作为审计日志非常有用。
您可以使用 table_changes SQL 函数在 SQL 查询中读取变更数据流。
以下是如何读取 students 表的整个变更数据流:
SELECT * FROM table_changes('students', 0)
+---+-----+---+------------+---------------+----------------------+
|id |name |age|_change_type|_commit_version|_commit_timestamp |
+---+-----+---+------------+---------------+----------------------+
|0 |Bob |23 |delete |3 |2023-04-19 12:06:11.5 |
|1 |Sue |25 |delete |3 |2023-04-19 12:06:11.5 |
|2 |Jim |27 |delete |3 |2023-04-19 12:06:11.5 |
|5 |Jack |18 |insert |2 |2023-04-19 12:06:06.24|
|6 |Nora |19 |insert |2 |2023-04-19 12:06:06.24|
|7 |Clare|20 |insert |2 |2023-04-19 12:06:06.24|
|0 |Bob |23 |insert |1 |2023-04-19 12:05:57.84|
|1 |Sue |25 |insert |1 |2023-04-19 12:05:57.84|
|2 |Jim |27 |insert |1 |2023-04-19 12:05:57.84|
+---+-----+---+------------+---------------+----------------------+以下是如何仅读取提交版本 2 和 3 的变更数据流:
SELECT * FROM table_changes('students', 2, 3)
+---+-----+---+------------+---------------+----------------------+
|id |name |age|_change_type|_commit_version|_commit_timestamp |
+---+-----+---+------------+---------------+----------------------+
|0 |Bob |23 |delete |3 |2023-04-19 12:06:11.5 |
|1 |Sue |25 |delete |3 |2023-04-19 12:06:11.5 |
|2 |Jim |27 |delete |3 |2023-04-19 12:06:11.5 |
|5 |Jack |18 |insert |2 |2023-04-19 12:06:06.24|
|6 |Nora |19 |insert |2 |2023-04-19 12:06:06.24|
|7 |Clare|20 |insert |2 |2023-04-19 12:06:06.24|
+---+-----+---+------------+---------------+----------------------+以前,变更数据流只能通过 Python 和 Scala 中的 Spark DataFrameReader API 轻松访问。现在,变更数据流也可以通过 SQL API 轻松访问。
结论
Delta Lake 2.3 版本为 Delta Lake 增加了各种新功能。
这些更改使得将工作负载迁移到 Delta Lake 变得更容易,并能够执行复杂的分析,构建高度可扩展、高性能、生产级别的湖仓。Delta Lake 是一个不断发展的项目,新功能会定期添加,使其持续改进。
如果您想参与其中,请随时在领英上关注我们,加入我们的Slack 社区,或阅读Delta Spark 贡献入门指南!