Delta Lake 如何使用元数据使某些聚合更快
本篇博客文章解释了 Delta Lake 如何更新以利用元数据,从而使某些聚合基准测试在大型数据集上运行得更快。
这些聚合改进已添加到 Delta Lake 2.2.0 中,因此基准测试将比较 Delta Lake 2.2.0 与 Delta Lake 2.1.1。
我们来看看这些基准测试是如何运行的。
基准测试设置
我们生成了一个包含五列的合成数据集。以下是数据集中的几行:
+------+------------------------------------+----+-----+---+-----+
|id |uuid |year|month|day|value|
+------+------------------------------------+----+-----+---+-----+
|20470 |09797ddf-13ab-4ccd-bb6a-d6b1693e8123|2010|10 |2 |470 |
|148546|864b31b5-f337-4e08-afe3-d72c834efa1f|2002|10 |6 |546 |
|459007|08a60ad9-664a-4609-bf25-2598bef92520|2021|7 |3 |7 |
|248874|1ebee359-4548-4509-9bc0-5e11bcc49336|2010|6 |10 |874 |
|139382|5eee63fe-d559-4002-857b-3251a8e4df80|2012|2 |26 |382 |
+------+------------------------------------+----+-----+---+-----+我们将此数据集写入了 100、1_000、10_000 和 100_000 个不同的文件,以便为运行基准测试提供不同的场景。请参阅附录中用于生成合成数据集的脚本。
查询是在一台配备 64GB 内存的 Macbook M1 笔记本电脑上运行的。我们来看看结果。
计算 Delta Lake 表中的所有数据行
我们来看看 Delta Lake 2.2+ 如何让以下查询运行得更快:select count(*) from the_table。
此查询在 100、1_000、10_000 和 100_000 个文件上针对 Delta Lake 2.1.1 和 Delta Lake 2.2 运行,如下图所示:
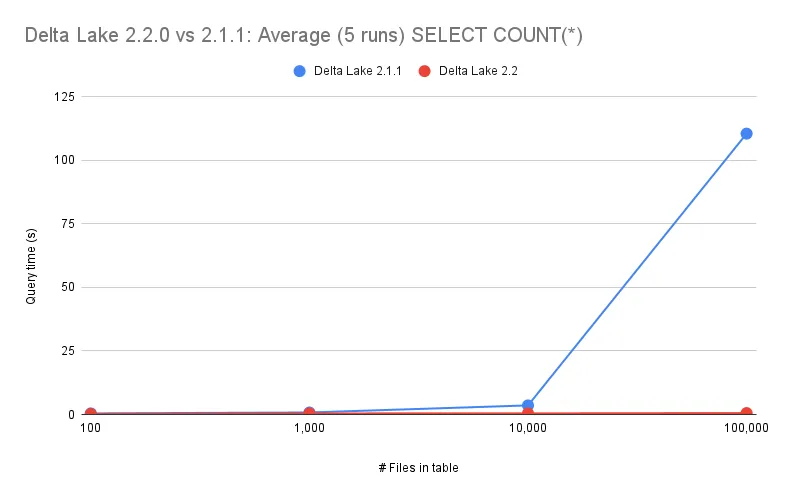
对于 Delta Lake 2.1.1 及更早版本,查询运行时随着文件数量的增加而增加。随着 Delta Lake 2.2 中添加的新优化,查询时间不会随着文件数量的增加而增加。
Delta 表中每个文件的记录数包含在 Delta 事务日志中。您无需实际查询数据来计算记录数,只需查阅元数据即可。
Delta Lake 2.2+ 将此查询作为纯元数据操作执行,这就是它能够扩展到更多文件而无需更长时间运行的原因。
我们来看看 Delta Lake 2.2 中添加的另一个查询性能增强功能。
从 Delta 表中选择单行数据
我们来看看 Delta Lake 2.2+ 如何让以下查询运行得更快:select * from the_table limit 1。
此查询在 100、1_000、10_000 和 100_000 个文件上针对 Delta Lake 2.1.1 和 Delta Lake 2.2 运行,如下图所示:
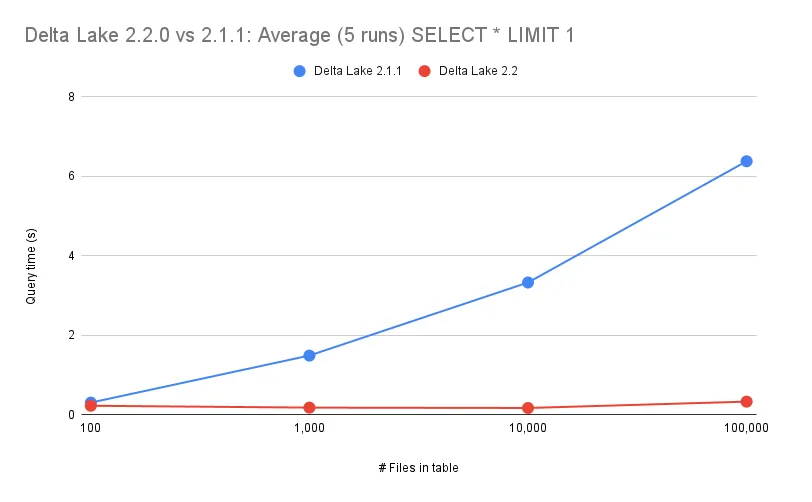
Delta Lake 2.1.1 在查询规划期间从未考虑过限制。因此,Delta Lake 生成的物理计划涉及扫描表中的所有数据。然后 Spark 将把 LIMIT 应用到该结果上。
而 Delta Lake 2.2 在查询规划期间确实考虑了限制,并内部使用每个文件的统计信息来确定需要读取的最小数据文件量。有了这个小得多的集合,Spark 可以只读取几个文件,然后将 LIMIT 应用到那个小得多的结果上。请在此处查看实现此功能的提交:https://github.com/delta-io/delta/commit/1a94a585b74477896cbcae203fc26eaca733cbaa。
在这个使用 select * from the_table limit 1 的示例中,Spark 只需从单个文件中读取一行。无论 Delta 表中有多少文件,此查询都将能够以同样的速度运行。
我们来看看 Delta Lake 事务日志的内容,以直观了解如何通过利用事务日志中的信息来优化 Delta 表查询。
Delta Lake 事务日志直观理解
我们来看看 Delta 表的基本结构
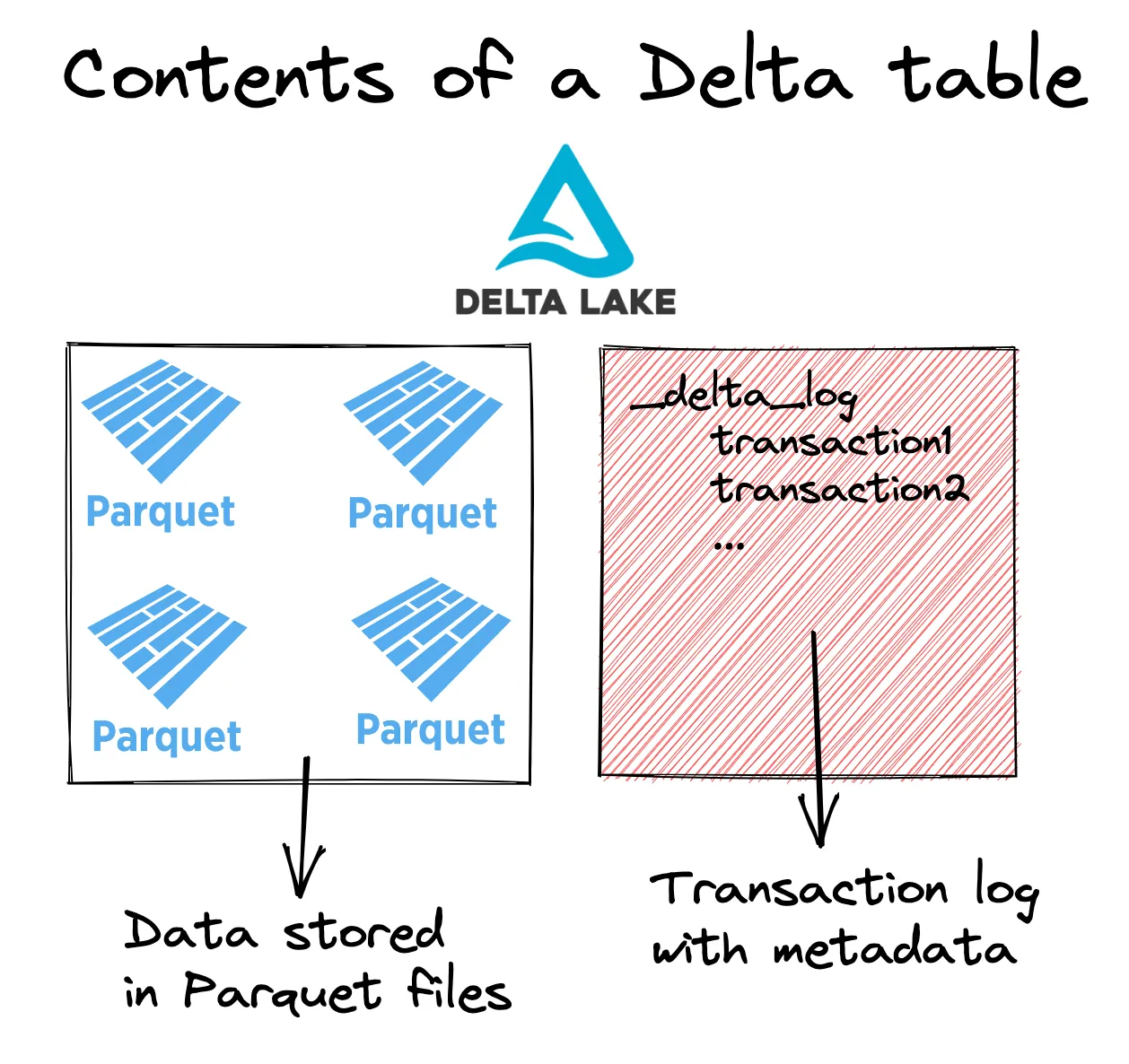
数据存储在 Parquet 文件中,事务元数据信息存储在事务日志(又名 _delta_log)中。
某些类型的查询可以通过仅查阅事务日志来解决。我们来看看一个具有代表性的事务日志条目:
{
"commitInfo": {
"delta-rs": "0.8.0",
"timestamp": 1679608176735
}
}
{
"protocol": {
"minReaderVersion": 1,
"minWriterVersion": 1
}
}
{
"metaData": {
"id": "efc48132-57a7-4b93-a0aa-7300bb0bdf94",
"name": null,
"description": null,
"format": {
"provider": "parquet",
"options": {}
},
"schemaString": "{\"type\":\"struct\",\"fields\":[{\"name\":\"x\",\"type\":\"long\",\"nullable\":true,\"metadata\":{}}]}",
"partitionColumns": [],
"createdTime": 1679608176735,
"configuration": {}
}
}
{
"add": {
"path": "0-66a9cef6-c023-46a4-8714-995cad909191-0.parquet",
"size": 1654,
"partitionValues": {},
"modificationTime": 1679608176735,
"dataChange": true,
"stats": "{\"numRecords\": 3, \"minValues\": {\"x\": 1}, \"maxValues\": {\"x\": 3}, \"nullCount\": {\"x\": 0}}",
"tags": null
}
}仔细查看事务日志中包含 numRecords 的 "stats" 部分。您可以通过查看 numRecords 来获取文件中的行数。select count(*) from some_table 查询可以通过简单地汇总给定 Delta 表版本中所有文件的 numRecords 来执行。
结论
这篇博客文章展示了 Spark 如何使用 Delta Lake 事务日志,使某些查询在 Delta 表中文件数量增长时运行得更快。
Delta Lake 是一个不断发展的项目,新功能和性能增强不断被添加。作为用户,您无需更改任何代码即可利用本文介绍的聚合优化。您只需升级您的 Delta Lake 版本即可立即享受这些性能增强带来的好处。
在 LinkedIn 上关注我们,获取有关新版本和 Delta Lake 功能的高质量信息。我们定期发布有用的信息,这将帮助您提升 Delta Lake 技能!
附录:数据生成脚本
我们使用以下代码片段生成了用于此基准分析的合成数据集:
import pyspark.sql.functions as F
from pyspark.sql.types import StringType
def create_table(total_rows, total_files, table_base_path):
rows_per_commit = 10_000_000
num_commits = int(total_rows / rows_per_commit)
num_files_per_commit = int(total_files / num_commits)
table_path = (
f"{table_base_path}/{int(total_rows / 1_000_000)}_mil_rows_{total_files}_files"
)
for i in range(num_commits):
(
spark.range(rows_per_commit)
.withColumn("uuid", F.expr("uuid()"))
.withColumn("year", F.col("id") % 22 + 2000)
.withColumn("month", F.col("id") % 12)
.withColumn("day", F.col("id") % 28)
.withColumn("value", (F.col("id") % 1000).cast(StringType()))
.repartition(num_files_per_commit)
.write.format("delta")
.mode("append")
.save(table_path)
)
create_table(100_000_000, 100, "/Users/matthew.powers/benchmarks/tables")
create_table(100_000_000, 1000, "/Users/matthew.powers/benchmarks/tables")
create_table(100_000_000, 10000, "/Users/matthew.powers/benchmarks/tables")
create_table(100_000_000, 100000, "/Users/matthew.powers/benchmarks/tables")