AWS Lambda 对 Delta Lake 表的支持
作者:Nick Karpov
我们很高兴地宣布,随着 AWS SDK for pandas (2.20) 层的最新发布,AWS Lambda 现在支持 `deltalake` 软件包,用于对 Delta Lake 表进行读写访问。Delta Lake 社区一直努力使其成为现实,我们很高兴与您分享。在这篇博文中,我们将重点介绍从 AWS Lambda 使用 Delta Lake 的好处,并逐步介绍如何使用 `deltalake` 构建您自己的 Lambda 层。
读写 Delta Lake 表
从 AWS Lambda 函数读写 Delta Lake 表的代码与在本地和其他环境中的代码相同。这是一个 AWS Lambda 兼容代码块的最小示例,演示了 Delta Lake 表的读取、转换和写入
import json
from deltalake import DeltaTable
from deltalake.writer import write_deltalake
def lambda_handler(event, context):
# Read data from Delta Lake table
# Assume that `event` has value for the key `path`
path = event.get('path')
dt = DeltaTable(path)
df = dt.to_pandas()
# Example: Add a new column with the length of the values in column 'A'
df['B'] = df['A'].apply(len)
# Write the dataframe to a new Delta table on S3
new_path = 's3://your-bucket/new-delta-table'
write_deltalake(new_path, df, mode='append')
return {
'statusCode': 200,
'body': json.dumps(f"Data successfully written to: {new_path}")
}此 Lambda 函数从 Delta Lake 表读取数据,使用 Pandas 添加新列,并将修改后的数据写入 S3 上的新 Delta 表。
从 AWS Lambda 使用 Delta Lake 表的好处
借助 AWS Lambda 对 Python `deltalake` 软件包的新支持,用户现在可以享受以下好处
-
可扩展性:AWS Lambda 允许您运行代码而无需预置或管理服务器,使您能够构建可轻松根据请求数量进行扩展的应用程序。借助 Delta Lake 表支持,您现在可以轻松构建和扩展数据处理应用程序。
-
成本效益:AWS Lambda 会根据请求数量自动扩展您的应用程序,您只需为您消耗的计算时间付费。通过在 AWS Lambda 中利用 deltalake 软件包,您可以减少为较小用例过度预置大型集群的开支。
-
易用性:Delta Lake 表与 AWS Lambda 的集成简化了数据处理工作流,使您能够专注于应用程序逻辑,而不是管理基础设施。
-
提高兼容性:通过扩展 AWS pandas SDK 中的 PyArrow 构建,我们为其他软件包从该依赖项中受益铺平了道路,从而促进了兼容应用程序和工具的更广泛生态系统。
安装
您可以通过将 zip 文件存档作为 Lambda 层上传,或通过创建容器映像并将其上传到 Amazon ECR 来使用 Lambda 函数配置 deltalake。在这篇文章中,我们将重点介绍易于使用的Lambda 层方法。
将 deltalake 软件包构建为 AWS Lambda 层
首先,为该层创建一个新目录和 `python` 子目录,并导航到该子目录。AWS Lambda 需要该子目录才能正确识别依赖项。
mkdir -p deltalake_lambda_layer/python
cd deltalake_lambda_layer其次,将 deltalake 软件包(不带其依赖项,即 `--no-deps`)安装到 python 子目录中。所有必要的依赖项都包含在 AWS SDK for pandas 层中,我们将在稍后的步骤中将其与 Lambda 函数一起配置。请注意,我们还显式指定了 `--platform` 以确保我们获得兼容的基于 Linux 的构建。
pip install -t ./python --no-deps --platform manylinux2014_x86_64 deltalake==0.8.0最后,将安装包打包成一个 zip 文件并相应命名
zip -r deltalake_layer.zip .您现在有了一个 `deltalake_layer.zip` 文件,您可以将其作为层上传到 AWS Lambda。
将 deltalake Lambda 层 zip 文件上传到 AWS
使用 AWS CLI
如果您尚未安装和配置 AWS CLI,请先进行安装和配置,然后运行以下命令以上传我们在上一步中构建的层。
aws lambda publish-layer-version \
--layer-name deltalake_layer \
--zip-file fileb://deltalake_layer.zip \
--compatible-runtimes python3.7 python3.8 python3.9使用 AWS 管理控制台
要使用 AWS 管理控制台上传 Lambda 层,请按照以下步骤操作。您可以在 AWS 文档中阅读有关配置 AWS Lambda 层的更多信息。
- 登录 AWS 管理控制台。
- 导航到 Lambda 服务。
- 单击左侧边栏中的“层”。
- 单击“创建层”按钮。
- 为该层提供一个名称,例如“deltalake_layer”。
- 单击“上传”按钮并选择 deltalake_layer.zip 文件。
- 选择合适的运行时,然后单击“创建”按钮。
记下响应中的 LayerVersionArn,因为您在配置 Lambda 函数时将需要它。
配置 AWS Lambda 函数
在使用 lambda 函数中的 `deltalake` 之前,我们还需要配置几个步骤。
向 lambda 函数添加层
如前所述,我们依赖 AWS SDK for pandas 来提供 `deltalake` 所需的依赖项。这意味着我们需要将这两个层添加到我们的函数中。
首先,添加 AWS SDK for pandas 层。如下图所示,该层是完全托管的,可以直接在 AWS 控制台中获得,因此我们不需要像 deltalake 层那样打包任何东西。您可以在官方文档中阅读更多相关信息。
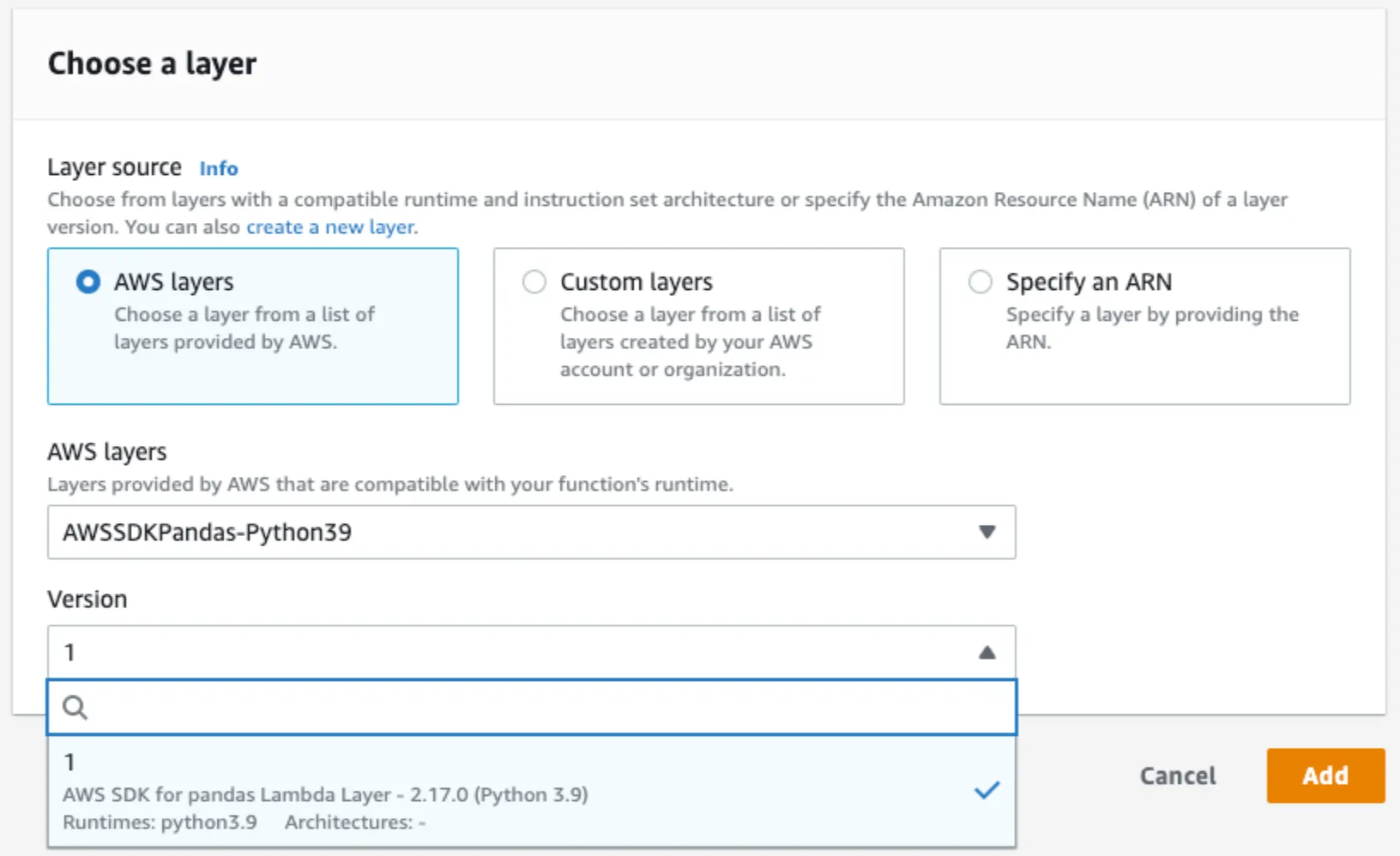
IAM 角色
我们需要确保我们的函数能够读写 S3。推荐的方法是使用 IAM 角色,因此请确保您的执行角色具有适当的权限。您可以在官方文档中阅读有关 AWS Lambda 的 IAM 角色配置的更多信息。
环境变量
如果您不打算让多个写入器同时访问 Delta Lake 表,则必须在Lamda 函数环境变量配置中设置以下环境变量。否则,函数将抛出错误以保护您的数据免受意外写入。
AWS_S3_ALLOW_UNSAFE_RENAME false如果您确实计划有多个写入器,则必须添加以下环境变量,以确保 `deltalake` 写入器不会相互覆盖。
AWS_S3_LOCKING_PROVIDER dynamodb
DYNAMO_LOCK_PARTITION_KEY_VALUE key
DYNAMO_LOCK_TABLE_NAME delta_rs_lock_table请注意上面分区键值和表名称的值,并确保它们与您在下一步中预置的 DynamoDB 表一致!
DynamoDB 多写入器支持
如果您计划同时支持多个写入器,则必须预置一个 DynamoDB 表并使用 IAM 角色授予访问权限。此表对于支持 S3 中的并发写入器是必要的。
以下是使用 AWS CLI 快速创建 DynamoDB 表的代码片段
aws dynamodb create-table --table-name delta_rs_lock_table \
--attribute-definitions \
AttributeName=key,AttributeType=S \
--key-schema \
AttributeName=key,KeyType=HASH \
--provisioned-throughput \
ReadCapacityUnits=10,WriteCapacityUnits=10
限制和未来工作
Delta Lake 的三种主要多进程写入解决方案,即 Databricks Runtime、带有 DynamoDB 的 Delta Lake Spark 连接器和带有 DynamoDB 的 Delta Rust,正在不断发展以增强兼容性。虽然所有这三个连接器目前都支持并发读取表,但尚无法从不同的连接器同时写入 AWS S3 上的同一表。用户必须一次使用一个连接器以确保数据正确性。目前的限制是由于 S3 上确保互斥的不同方法:Databricks Runtime 使用托管的内部服务,带有 DynamoDB 的 Delta Rust 采用基于租约的锁定机制,而带有 DynamoDB 的 Delta Spark 则依赖于条件写入。Delta 社区正在积极开发统一的兼容解决方案,以确保所有连接器都将同时支持所有 Delta 连接器的多进程写入。
结论
我们很高兴地宣布 AWS Lambda 中对 deltalake 软件包的支持,以及 AWS SDK for pandas 层。我们相信这种集成将使客户能够在 AWS 生态系统中构建更具可扩展性、成本效益和用户友好的数据处理应用程序。我们要感谢 AWS SDK for pandas 团队的协作和愿意调整其 AWS Lambda 层构建,从而使这项支持成为可能!
我们鼓励您在 AWS Lambda 函数中试用 deltalake 软件包支持,并亲身体验其好处。我们期待看到用户使用这项新集成开发出创新的解决方案。
编码愉快,尽情享受 AWS Lambda 中 Delta Lake 表的强大功能!