如何将 CSV 转换为 Delta Lake
这篇博文解释了如何将 CSV 转换为 Delta Lake,以及使用 Delta Lake 将享受到的诸多好处。CSV 数据湖有许多限制,这些限制在 Parquet 数据湖中得到了改进,并在 Delta Lake 表中得到了进一步增强。
从 CSV 切换到 Delta Lake 将使您立即获得更好的性能、重要的功能,并允许您构建更可靠的数据管道。
CSV 对于需要人类可读性的小型数据集来说尚可,但通常应避免用于生产数据工作流。CSV 速度慢,容易损坏,这可能会破坏您的数据管道。
让我们看一个例子,了解将 CSV 转换为 Delta Lake 是多么容易。
将 CSV 转换为 Delta Lake 示例
让我们看看如何将三个 CSV 文件转换为 Delta Lake 表。
假设您有三个 CSV 文件,其中包含学生数据,包括 student_name、graduation_year 和 major。这是 data/students/students1.csv 文件的内容。
student_name,graduation_year,major
someXXperson,2023,math
liXXyao,2025,physics首先将所有 CSV 文件读取到 PySpark DataFrame 中。
df = spark.read.format("csv").option("header", True).load("data/students/*.csv")
df.show()
+------------+---------------+-------+
|student_name|graduation_year| major|
+------------+---------------+-------+
| chrisXXborg| 2025| bio|
|davidXXcross| 2026|physics|
|sophiaXXraul| 2022| bio|
| fredXXli| 2025|physics|
|someXXperson| 2023| math|
| liXXyao| 2025|physics|
+------------+---------------+-------+现在将此 DataFrame 写入 Delta Lake 表。
df.write.format("delta").save("tmp/students_delta")查看 Delta 表中输出的文件。
tmp/students_delta
├── _delta_log
│ └── 00000000000000000000.json
├── part-00000-55546730-18ac-4e4a-9c1a-da728de2a9eb-c000.snappy.parquet
├── part-00001-b62820a2-5641-43e5-bc02-f46c035900f1-c000.snappy.parquet
└── part-00002-2ebf1899-3e7c-4182-bfe2-2f68c6d4f826-c000.snappy.parquet您可以看到 Delta 表由三个存储数据的 Parquet 文件和一个包含已发生事务元数据的 _delta_log 表组成。到目前为止,唯一发生的事务是将这三个 Parquet 文件添加到 Delta 表中。
读取 Delta 表并确保它按预期工作。
spark.read.format("delta").load("tmp/students_delta").show()
+------------+---------------+-------+
|student_name|graduation_year| major|
+------------+---------------+-------+
| chrisXXborg| 2025| bio|
|davidXXcross| 2026|physics|
|someXXperson| 2023| math|
| liXXyao| 2025|physics|
|sophiaXXraul| 2022| bio|
| fredXXli| 2025|physics|
+------------+---------------+-------+是的,这完美运行。
您可以看到 student_name 列用 XX 分隔名字和姓氏。在生产摄取管道中,您可以在将 CSV 数据转换为 Delta Lake 表时,将此字段拆分为 student_first_name 和 student_last_name。
以下是您在写入 Delta 表之前如何清理 student_name 列的方法。
from pyspark.sql.functions import col, split
clean_df = (
df.withColumn("student_first_name", split(col("student_name"), "XX").getItem(0))
.withColumn("student_last_name", split(col("student_name"), "XX").getItem(1))
.drop("student_name")
)
clean_df.write.format("delta").save("tmp/clean_students_delta")让我们读取 clean_students_data 表并检查其内容。
spark.read.format("delta").load("tmp/clean_students_delta").show()
+---------------+-------+------------------+-----------------+
|graduation_year| major|student_first_name|student_last_name|
+---------------+-------+------------------+-----------------+
| 2025| bio| chris| borg|
| 2026|physics| david| cross|
| 2022| bio| sophia| raul|
| 2025|physics| fred| li|
| 2023| math| some| person|
| 2025|physics| li| yao|
+---------------+-------+------------------+-----------------+有时您会希望将原始数据添加到 Delta 表中,然后稍后清理。其他时候,您会希望在将数据添加到 Delta 表之前进行清理。只需确保在将数据传递给最终用户之前对其进行清理即可。
让我们看看为什么从 CSV 切换到 Delta Lake 会给您带来许多好处。
Delta Lake 相对于 CSV 的优势
Delta Lake 将数据存储在 Parquet 文件中,因此它具有 Parquet 相对于 CSV 的所有优势,例如:
- Parquet 文件在文件尾部包含模式信息
- Parquet 文件更易于压缩
- Parquet 文件是基于列的,并允许列裁剪,这是一项重要的性能增强
- Parquet 文件包含列元数据,允许谓词下推过滤
- Parquet 文件是不可变的
请参阅此视频,详细讨论 Parquet 相对于 CSV 的优势。
Delta Lake 相对于 Parquet 文件还有几个额外的优势。
- Delta Lake 允许时间旅行/回滚并恢复
- Delta Lake 支持版本化数据
- Delta Lake 具有 ACID 事务
- Delta Lake 允许模式强制/模式演进
- 以及更多……
请查看以下图表以总结这些优势。
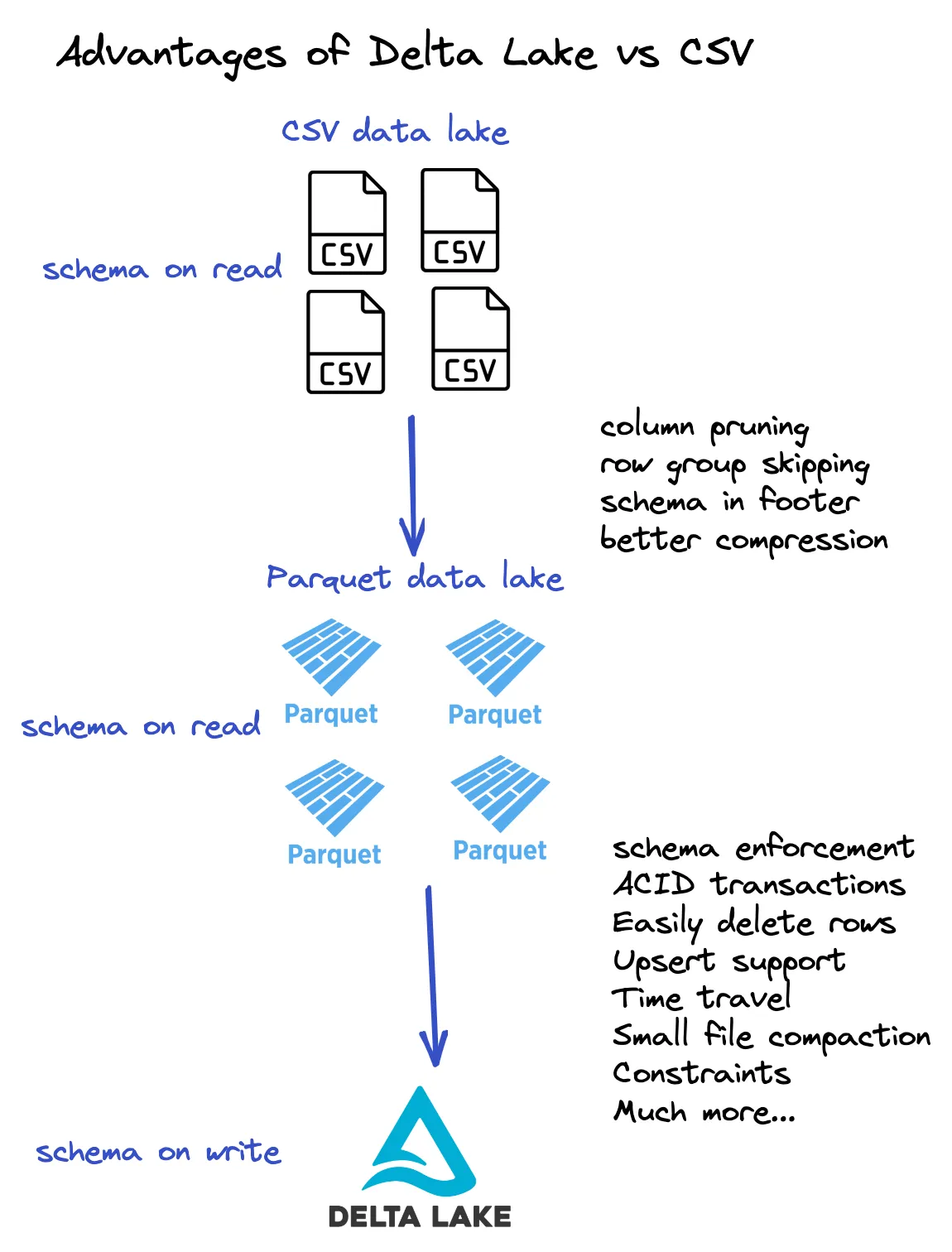
Delta Lake 将元数据信息存储在事务日志中,并将底层数据存储在 Parquet 文件中。因此,Delta Lake 也具有 Parquet 相对于 CSV 的所有优势。此图表让您更好地了解 Delta 表的结构。
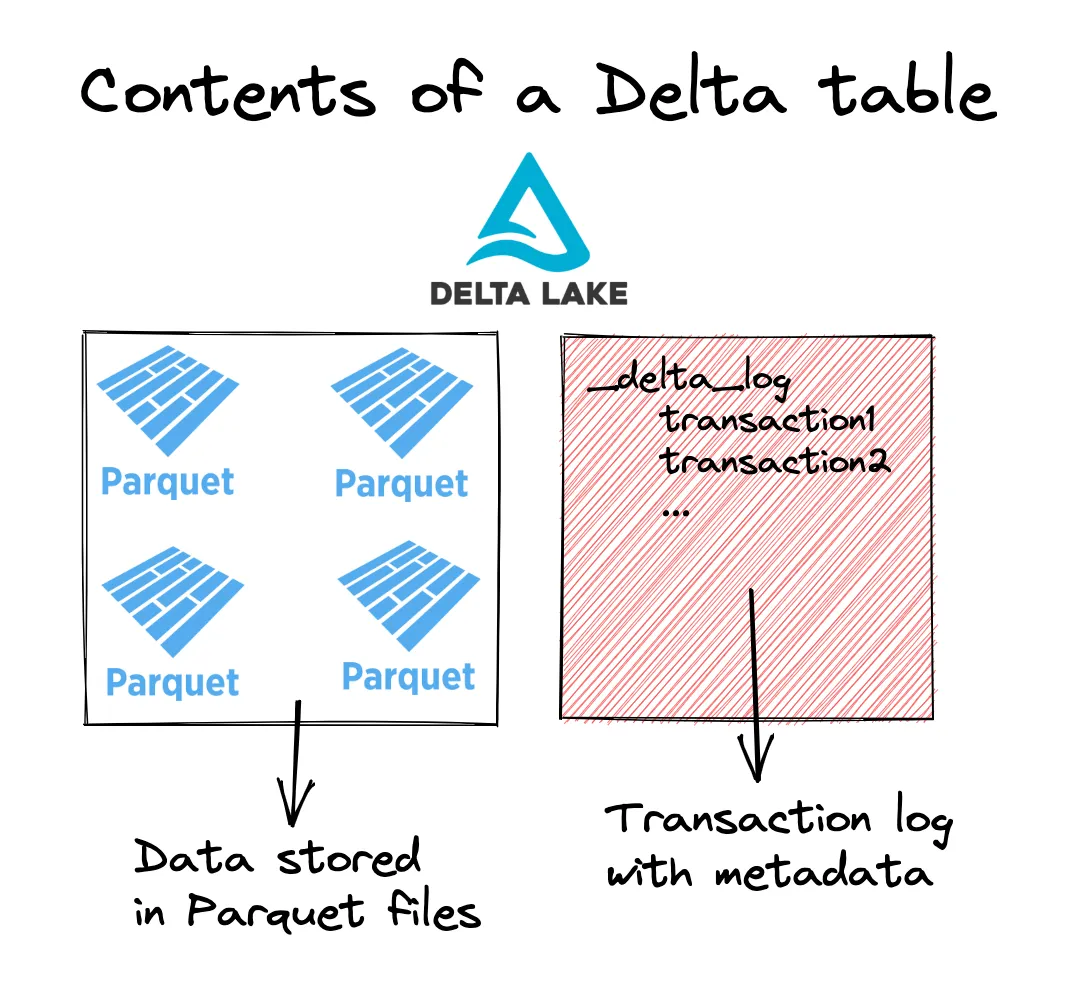
让我们看看模式强制,这是 Delta Lake 相对于 CSV/Parquet 数据湖的一个优势。
突出 Delta Lake 相对于 CSV 的一个优势:模式强制
让我们将一个模式不匹配的 DataFrame 写入 CSV 数据湖,看看它如何轻易损坏。然后,让我们尝试将相同的模式不匹配的 DataFrame 写入 Delta 表,看看 Delta Lake 如何通过模式强制防止错误的追加。
首先创建一个 DataFrame,其模式与现有学生表的模式不匹配。
mismatched_df = spark.range(0, 3)
mismatched_df.show()
+---+
| id|
+---+
| 0|
| 1|
| 2|
+---+将此 DataFrame 追加到 CSV 数据湖。
mismatched_df.repartition(1).write.mode("append").format("csv").option(
"header", True
).save("data/students")现在尝试将 CSV 数据湖读取到 DataFrame 中。
spark.read.format("csv").option("header", True).load("data/students/*.csv").show()
+------------+---------------+-------+
|student_name|graduation_year| major|
+------------+---------------+-------+
| chrisXXborg| 2025| bio|
|davidXXcross| 2026|physics|
|sophiaXXraul| 2022| bio|
| fredXXli| 2025|physics|
|someXXperson| 2023| math|
| liXXyao| 2025|physics|
| 0| null| null|
| 1| null| null|
| 2| null| null|
+------------+---------------+-------+此读取操作还会输出以下警告消息:
22/12/24 16:40:46 WARN CSVHeaderChecker: Number of column in CSV header is not equal to number of fields in the schema:
Header length: 1, schema size: 3
CSV file: file://…/data/students/part-00000-988a286d-a024-4612-8b6e-89cce5f2556e-c000.csv警告消息很好,但它并不理想。我们的 CSV 数据湖现在已经被错误数据损坏了!
让我们尝试将这个模式不匹配的 DataFrame 追加到我们的 Delta 表中,看看会发生什么。
mismatched_df.repartition(1).write.mode("append").format("delta").save(
"tmp/students_delta"
)这会因以下消息而报错:
AnalysisException: A schema mismatch detected when writing to the Delta table (Table ID: 740d4bb1-d539-4d56-911e-18a616a37940).
To enable schema migration using DataFrameWriter or DataStreamWriter, please set: '.option("mergeSchema", "true")'. For other operations, set the session configuration
spark.databricks.delta.schema.autoMerge.enabled to "true". See the documentation
specific to the operation for details.
Table schema:
root
-- student_name: string (nullable = true)
-- graduation_year: string (nullable = true)
-- major: string (nullable = true)
Data schema:
root
-- id: long (nullable = true)Delta Lake 不会通过追加模式不匹配的数据来让您损坏您的 Delta 表。它会拒绝追加,并使您的表保持正确和正常工作状态。
请参阅这篇博文,了解有关模式强制的更多信息。出于演示目的,我们只强调了 Delta Lake 相对于 CSV 文件的这一个功能,但还有许多其他同样有用的功能。
从 CSV 转换为 Delta Lake 结论
将 CSV 数据湖转换为 Delta Lake 表非常容易。您只需将 CSV 文件读取到 DataFrame 中,然后以 Delta 文件格式将其写入。
Delta 表比 CSV 文件具有许多优点。Delta Lake 是构建可靠且高性能数据管道的更好技术。
CSV 文件真正只适用于必须人类可读的小型数据集。使用 CSV 文件构建生产数据管道是危险的——有各种操作可能会损坏您的数据集或导致数据丢失。幸运的是,从 CSV 切换到 Delta Lake 并享受生产级数据管理的优势很容易。