Delta Lake Spark 贡献入门
作者:Nick Karpov
在这篇文章中,我们将探索 Delta Lake Spark 连接器的完整开发流程。你将学习如何检索和导航代码库,进行更改,以及打包和调试 Delta Lake Spark 连接器的自定义构建。
这篇文章适用于任何想要开始开发 Delta Lake 功能,或者只是想更好地了解内部机制的人。如果你正在使用其他语言或不同的系统,你仍然可以从参考 Spark 连接器中学到很多,因为它目前是 Delta Lake 最成熟、功能最丰富的连接器。
如果你不是开发人员,你仍然可以从探索底层实现中受益,并在日常使用中遇到意外行为时以调试模式运行 Delta Lake Spark 连接器。这是开源软件的主要优势之一!
我们将使用 git 和 IntelliJ,这对于基于 Java 的项目很常见,因此你也可以将这些步骤应用于许多其他相关项目。
如果你使用的是 Mac,你可以在终端中执行本文中的所有命令。对于其他操作系统,你可能需要进行更改。如果你遇到任何问题,请加入我们的 Slack 频道 #deltalake-questions 或 #contributing。
让我们开始吧。
如何获取 Delta Lake Spark 代码
首先,让我们分叉 Delta Lake Spark 连接器存储库。前往 https://github.com/delta-io/delta 并点击 + Create a new fork。分叉存储库会在我们自己的 Github 帐户中创建它的副本,这使我们能够在自己隔离的副本上安全地遵循 git 工作流程。
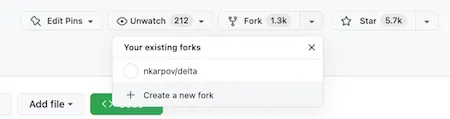
现在我们已经在自己的帐户中拥有了 Delta Spark 连接器存储库的副本,我们可以将代码克隆到本地环境。
克隆存储库并打开新的 delta 目录。
git clone https://github.com/nkarpov/delta
cd delta现在运行 git remote -v 并观察输出。git remote 命令用于管理一组跟踪的存储库。
➜ delta git:(dev) git remote -v
origin https://github.com/nkarpov/delta (fetch)
origin https://github.com/nkarpov/delta (push)你可以在这里看到,我们的本地存储库只跟踪一个远程,即 origin,它指向我们在 GitHub 中分叉的存储库。我们还希望我们的本地存储库跟踪原始的 delta-io/delta 存储库。这对于确保我们可以将分叉与原始存储库的任何更改同步至关重要。将上游远程命名为“upstream”很常见,我们可以使用以下命令完成此操作
git remote add upstream https://github.com/delta-io/delta现在让我们通过再次运行 git remote-v 来确认已添加新的“upstream”远程
➜ delta git:(dev) git remote -v
origin https://github.com/nkarpov/delta (fetch)
origin https://github.com/nkarpov/delta (push)
upstream https://github.com/delta-io/delta (fetch)
upstream https://github.com/delta-io/delta (push)我们的本地环境现在可以跟踪我们的分叉(我们称之为 origin)和原始的 Delta Lake Spark 连接器仓库(我们称之为 upstream)。你可以随意命名你的远程,但“origin”和“upstream”是许多开发人员遵循的常见命名约定。
现在让我们用这个命令获取所有标签
git fetch --all --tags标签是指向特定 git 提交的简单方法。Delta Spark 连接器版本已标记,例如:vX.X.X,我们可以可靠地使用这些标签来获取特定版本的确切代码,我们通过运行以下命令来完成此操作
git checkout tags/v2.2.0 -b dev此命令将标签 v2.2.0 引用的提交检出到一个名为“dev”的新本地分支。
我们的本地存储库现在已设置为 Delta Lake Spark 连接器的 2.2.0 版本。
我们希望尽快完成整个开发循环,所以稍后我们将回到这段代码。现在,让我们继续编译和打包我们的代码库。
如何编译和打包 Delta Lake Spark
Delta Lake Spark 连接器构建由 sbt 构建工具管理,这在 Scala 和 Java 项目中很常见。项目附带了一个 sbt 版本,因此我们可以从本地存储库目录中使用一个命令轻松编译和打包当前代码
build/sbt packagepackage 命令将编译并将代码打包成 JAR 文件,你可以与 Spark 一起使用这些文件来处理 Delta Lake 表。你第一次运行它时可能需要几分钟,但以后会更快。构建工具必须解析并下载项目的所有依赖项,这些依赖项你可能已经拥有也可能没有。
当你的 package 命令完成时,你应该在终端中看到一条最终消息,如下所示
[success] Total time: 22 s, completed Mar 2, 2023, 2:59:15 PM如果你之前没有使用过基于 JVM 的项目,你可能会遇到 Java 安装和/或版本错误。请确保你的机器上安装并提供了 JDK 8 或 JDK 11。你可以从本指南开始,并在此处查看提供 JDK 发行版的供应商列表这里
假设你成功运行了 package 命令,你现在应该有一些新的目录和文件,你可以使用以下 find 命令进行确认
➜ delta git:(dev) find . -name '*.jar'
... # you'll have a few more results; the important modules are:
./core/target/scala-2.12/delta-core_2.12-2.2.0.jar
./storage/target/delta-storage-2.2.0.jar
...你会注意到 package 不止生成了一个 JAR 文件。这是我们第一次看到 Delta Spark 连接器由少数独立但相关的模块组成。我们今天实际工作所需的两个模块列在上面:delta-core 和 delta-storage。
由于我们专注于让代码运行,稍后我们将回到这些模块进行扩展。现在你只需要知道 delta-core 模块包含核心 Delta 和 Spark 集成代码,而 delta-storage 模块包含存储相关代码,以确保 Delta 在 S3、Azure Data Lake 和 Google Cloud Storage 等存储服务中保持一致工作。
如何运行 Delta Lake Spark
我们已经检索了代码,从源代码编译,并打包了我们自己的 Delta Lake Spark 副本。现在让我们运行它。
我们需要 Apache Spark 来运行连接器。如果你还没有,可以使用以下命令从根目录下载并解压它。
curl -L https://dlcdn.apache.org/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz | tar xz
cd spark-3.3.2-bin-hadoop3导航到你的 Spark 安装目录,或确保它在你的 PATH 中可用,然后运行
bin/spark-shell \
--jars ../delta/core/target/scala-2.12/delta-core_2.12-2.2.0.jar,\
../delta/storage/target/delta-storage-2.2.0.jar \
--conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \
--conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"上述命令直接取自 Delta Lake 文档快速入门介绍,并进行了一点小改动。我们没有使用需要 Maven 坐标的 --packages 命令,而是使用了 --jars 命令,以便我们可以为 Spark 提供我们刚刚构建的确切 JAR 文件。请注意,我们在上面的示例中使用了相对路径,因此如果你在不同的目录结构中工作,你需要更新这些路径。
有很多方法可以改进我们提供正确打包代码的方式,但为了让你清楚地看到所有发生的事情,我们现在采用了最明确的方式。在这篇文章的最后,我们分享了一些有助于改进此工作流程的额外阅读链接。
现在让我们做一下 Delta Lake 等同于 Hello world 的操作,以确保一切都按预期工作
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.3.2
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 11.0.16.1)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.range(1).write.format("delta").save("/tmp/helloworld") // write a 1 row table
…
scala> spark.read.format("delta").load("/tmp/helloworld").show() // print our table
+---+
| id|
+---+
| 0|
+---+成功!我们已经完成了整个开发循环:获取代码、编译代码和运行代码。
让我们使用 IDE 设置项目,这将使我们能够以结构化的方式导航代码,并轻松地使用调试器运行它。
如何在 IntelliJ 中配置 Delta Lake Spark
IntelliJ 是使用 Delta Lake Spark 连接器的推荐 IDE。如果你还没有 IntelliJ,你可以在这里下载。社区版是完全免费的。
创建 Delta Lake Spark IntelliJ 项目
创建一个新的 Project from Existing Sources 并选择你运行构建的文件夹
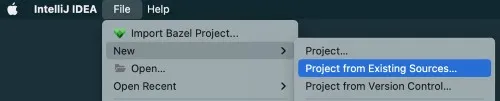
选择 sbt 作为外部模型
并确保选择合适的 Project JDK(JDK 1.8 或 JDK 1.11)
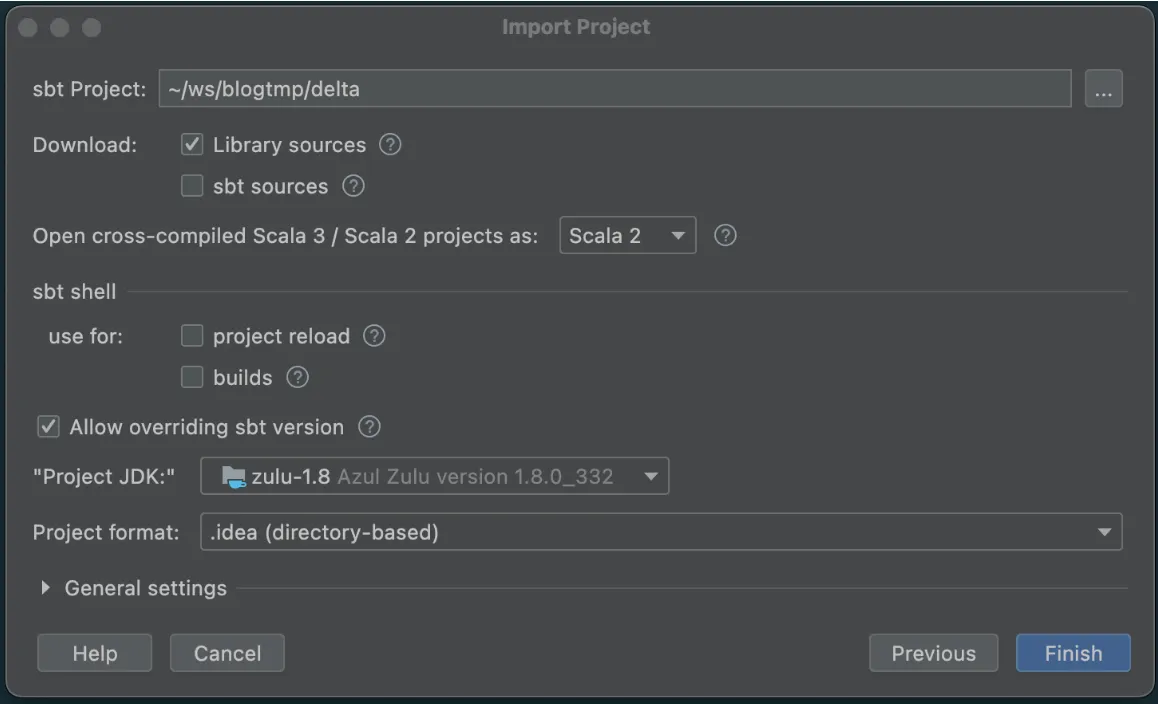
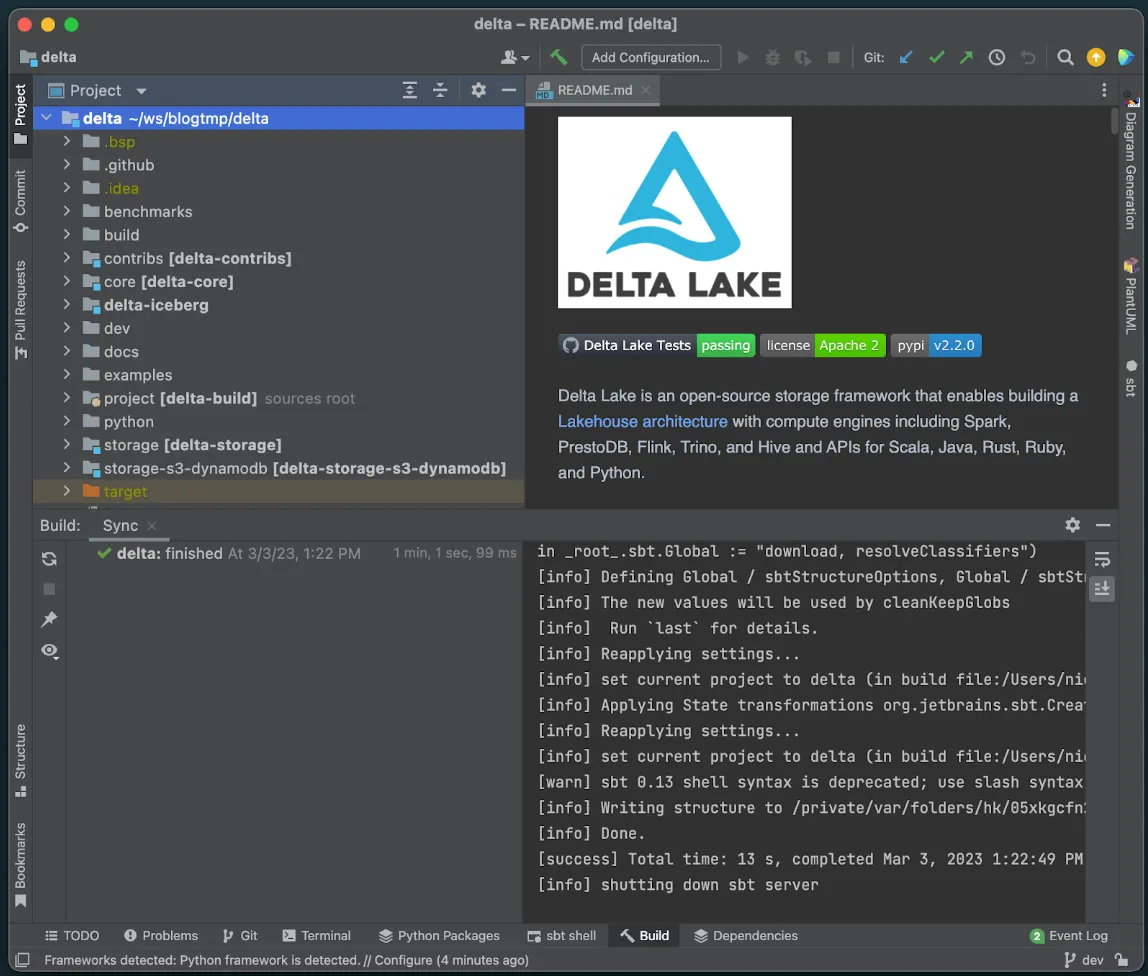
点击完成,IntelliJ 将使用项目定义加载项目。加载过程完成后,你应该会看到一个如下所示的屏幕,请注意左下角面板中的绿色勾号,表明我们的同步成功。
在 IntelliJ 中添加新的调试配置
现在让我们进行调试的最终配置。
在顶部面板上,点击 Add Configuration

在出现的窗口中点击 Add new > Remote JVM Debug
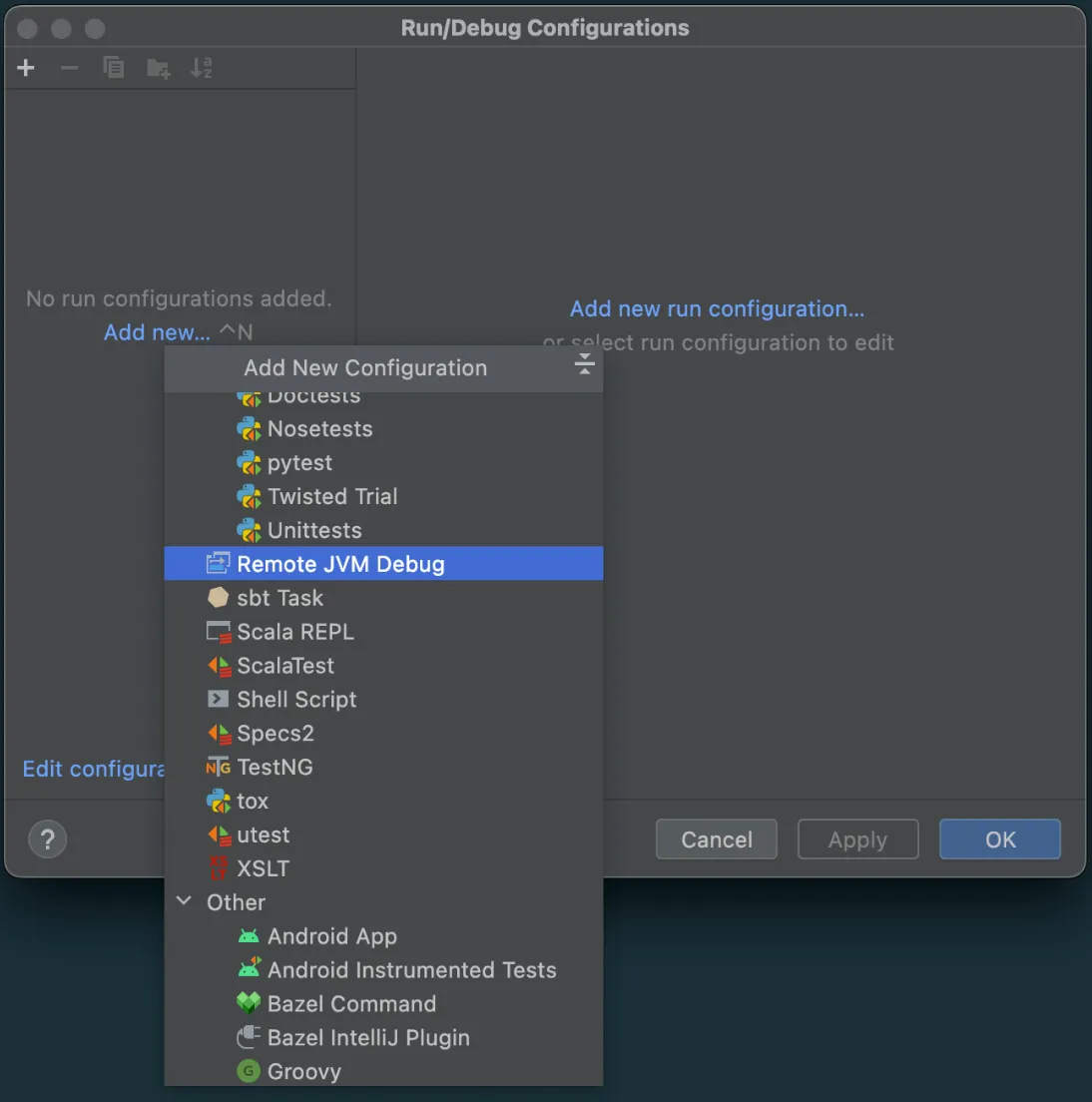
将出现一个新窗口来设置此 Remote JVM Debug。我们现在不需要更改任何内容。只需复制并保存 Command line arguments for remote JVM。
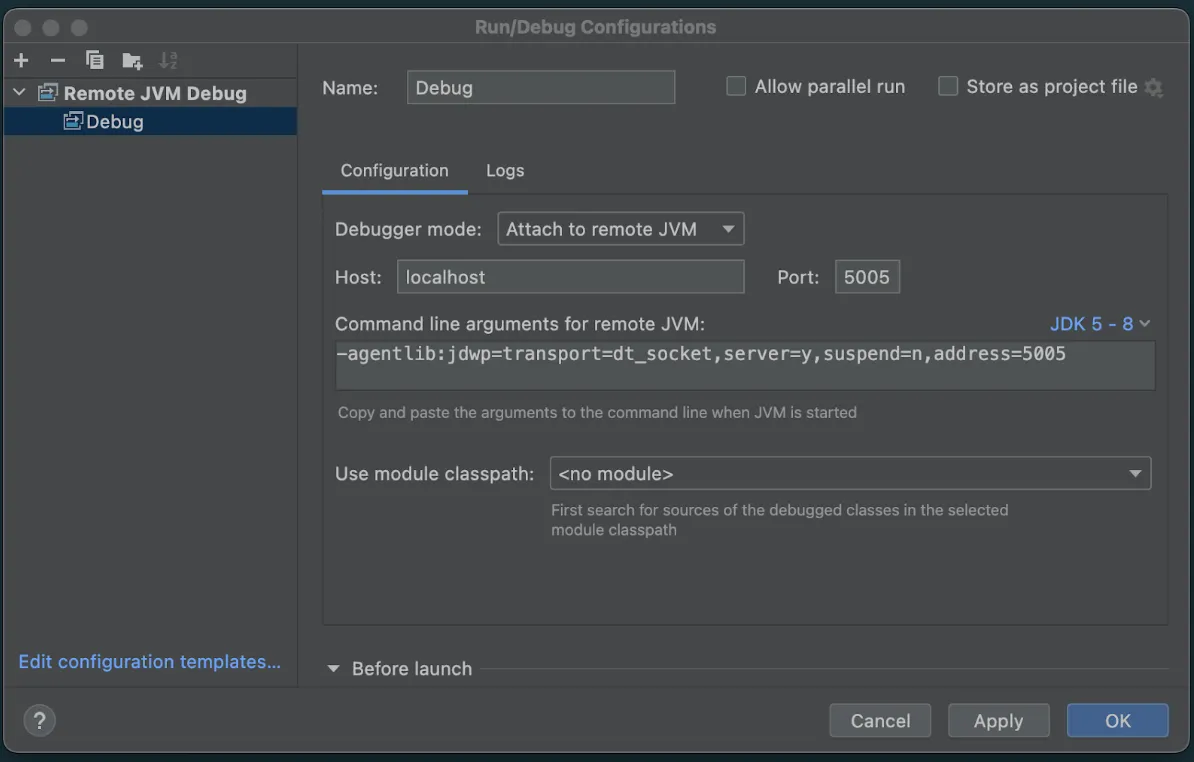
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005下次运行时,我们将把此配置属性传递给 Spark,以便它知道监听端口 5005 以进行 IntelliJ 调试会话。
如何修改 Delta Lake Spark
让我们对代码进行一些更改,并以调试模式演示它们的执行。我们将使这些更改微不足道,以便我们可以专注于开发循环,而不会迷失在实现细节中。我们的主要目标是在这个环境中感到舒适。
我们将进行两项更改。
1. 更改 SHOW COLUMNS 命令
首先,导航到 ShowTableColumnsCommand.scala 类,并将第 53 行从
snapshot.schema.fieldNames.map { x => Row(x) }.toSeq改为
snapshot.schema.fieldNames.map { x => Row(x.concat("COLUMN")) }.toSeq这是一个微不足道的更改,用于为 SHOW COLUMNS 返回的每个字段添加单词“COLUMN”。
你可以在 IntelliJ 中使用 CMD+O 快捷键来搜索类并轻松跳转到它们。你也可以按照下面的 GIF 手动到达那里。请注意,许多 Delta Lake 命令的实现都位于同一个包中,因此你也可以查看它们。
其次,如以下 GIF 所示,点击行号右侧以设置断点。你将看到一个鲜红色的圆圈出现,以确认已创建断点。断点指示 JVM 字面意义上“中断”或“暂停”执行。这将允许我们在下一节执行此命令时环顾四周并探索运行时环境。
2. 更改我们自定义构建的版本号
第二个更改纯粹是表面上的。我们将版本从 2.2.0 更改为 9.9.9-SNAPSHOT。导航到根目录中的 version.sbt 并相应地更改版本号。此步骤并非严格必要,但它将帮助我们跟踪我们的开发构建。如果我们不更改此版本号,我们可能会不小心使用了自定义构建,但由于我们的版本仍然是 2.2.0 而没有意识到。
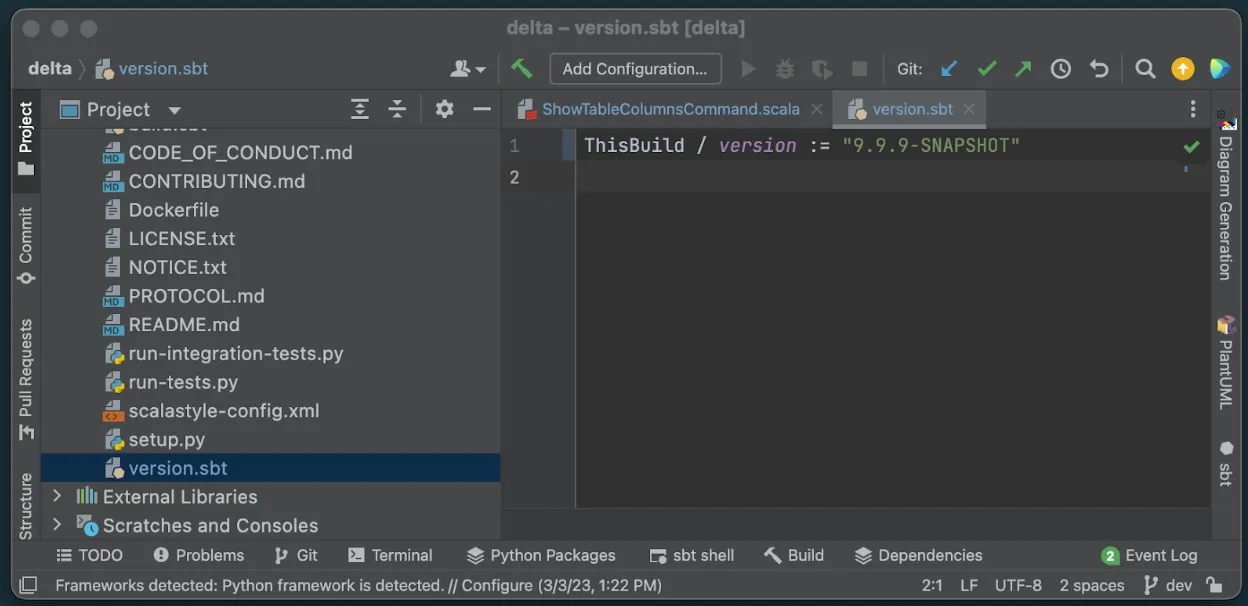
现在是最后一步,让我们使用与以前相同的 sbt 命令构建我们的新 9.9.9-SNAPSHOT 包
build/sbt package并观察到我们现在有了适当标记的新 JAR 文件
➜ delta git:(dev) ✗ find . -name '*.jar'
...
./core/target/scala-2.12/delta-core_2.12-9.9.9-SNAPSHOT.jar
./storage/target/delta-storage-9.9.9-SNAPSHOT.jar如何在 IntelliJ 中调试 Delta Lake Spark
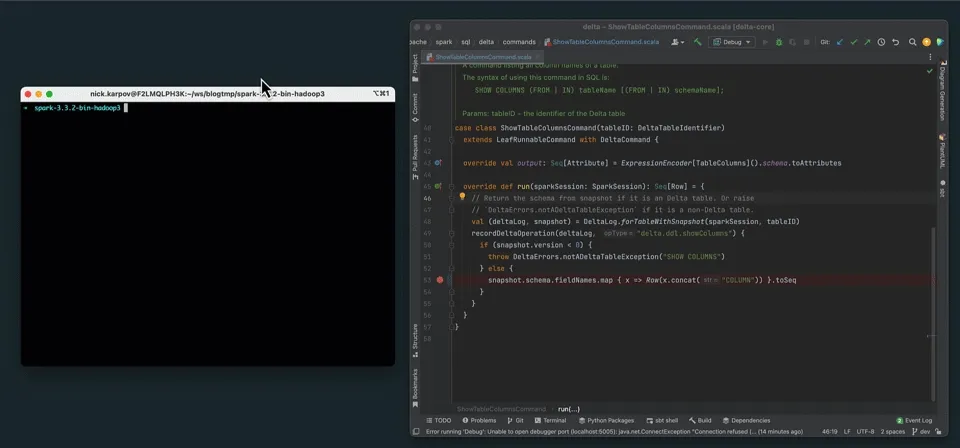
让我们在 IntelliJ 以调试模式运行时,从 Spark Shell 运行我们新打包的代码。
首先,返回到我们的 Spark 目录,并按如下方式运行更新的 spark-shell 命令
bin/spark-shell \
--conf 'spark.driver.extraJavaOptions=-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005' \
--jars ../delta/core/target/scala-2.12/delta-core_2.12-9.9.9-SNAPSHOT.jar,\
../delta/storage/target/delta-storage-9.9.9-SNAPSHOT.jar \
--conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \
--conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"请注意,我们已将 jar 的版本号更改为我们的 9.9.9-SNAPSHOT 版本,并从 IntelliJ 调试配置中添加了我们的调试字符串作为额外的 --conf 参数。我们必须添加此配置,以便运行 Spark 的 JVM 知道要侦听端口 5005 以进行 IntelliJ 连接。
现在,在 IntelliJ 中,点击调试图标以启动调试器
![]()
你应该会在 IntelliJ 中看到一条消息,确认它已连接到正在运行 Spark 的目标 JVM。

最后,在运行 Spark shell 的终端中,执行以下命令。
spark.range(5).write.format(“delta”).saveAsTable(“demo”)
spark.sql(“SHOW COLUMNS IN demo”).show()提交 SHOW COLUMNS 命令后,IntelliJ 应该会弹到前台并突出显示我们设置断点的代码行。这意味着调试器已在此行成功暂停执行,并已准备好供我们使用。
以下是一个演示整个过程的片段,包括在断点处停止,并显示我们新的 SHOW COLUMNS 的结果。
结论和后续步骤
在这篇文章中,我们逐步介绍了 Delta Lake Spark 连接器的完整开发流程。我们学习了如何在本地设置项目、构建和打包代码、配置 IntelliJ 调试器,以及在调试模式下运行我们自定义的 Delta Lake Spark 连接器。
从这里开始的可能性简直无穷无尽。我们可以在代码中的任何位置设置断点,从 Spark shell 交互式执行命令,并根据需要逐步执行整个执行路径。
在未来的文章中,我们将以此工作为基础,更深入地探讨 Delta Lake Spark 连接器的其他领域。
在这篇文章中,我们遵循了一个非常手动的设置过程,以突出所有可移动的部件。有很多方法可以改进我们的设置,但它们超出了本文的范围。以下是一些后续尝试的建议
-
直接从 IntelliJ 终端运行 spark-shell。你可以在这里阅读如何做到这一点
-
使用
build/sbt publish发布我们的构建。这允许我们使用包名而不是 JAR 路径,并且还允许我们通过简单地使用调整后的版本号(在本例中为 `9.9.9-SNAPSHOT)将我们的自定义构建作为依赖项包含在其他项目中。 -
探索 调试器中可用的完整功能。我们只演示了如何使用基本断点来停止执行。