Python deltalake 0.7.0 版本 delta-rs 中的新特性
deltalake 0.7.0 版本包含激动人心的新特性,包括更简洁的文件列表操作 API,手动创建检查点的能力,以及获取 Delta 表所有添加操作的强大功能。
本文将演示这些新特性,并解释何时可以在生产工作流中使用它们。所有代码片段都可以在此笔记本中找到,以防您想跟着操作!
更简洁的文件列表操作 API
以前有四个不同的 DeltaTable 方法来获取文件列表:files()、file_paths()、file_uris() 和 files_by_partition()。这些方法在是否可以传递过滤器(以选择分区子集)以及它们返回相对路径还是绝对 URI 方面有所不同。在 0.7.0 中,我们将它们合并为两个函数:
DeltaTable.files():获取文件中存储的路径,它们存储在 Delta Log 中(通常是相对路径,但也可以是绝对路径,尤其是在它们位于 Delta 表根目录之外时)。例如,使用 SHALLOW CLONE 命令创建的 Delta 表将具有绝对文件路径。DeltaTable.file_uris():获取文件的绝对 URI。
这两个函数都可以选择接受分区过滤器。让我们创建一个 Delta 表来演示此功能:
import pandas as pd
from deltalake import DeltaTable, write_deltalake
example_df = pd.DataFrame({
"part": ["a", "a", "b", "b"],
"value": [1, 2, 3, 4]
})
write_deltalake(
"example_table",
example_df,
partition_by=["part"],
mode="overwrite"
)此 Delta 表按 part 列分区,该列有两个不同的值,因此数据将按如下方式写入。
example_table
├── _delta_log
│ └── 00000000000000000000.json
├── part=a
│ └── 0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquet
└── part=b
└── 0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquetfiles() 方法返回 Delta 表中所有文件的列表:
table = DeltaTable("example_table")
table.files() # ['part=b/0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquet',
'part=a/0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquet']您还可以向 files() 方法传递谓词以返回文件子集。以下是列出 part=a 分区中所有文件的方法:
table.files([('part', '=', 'a')]) # ['part=a/0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquet']files() 方法将返回相对路径或 URI,具体取决于路径在 Delta 表中的存储方式。您可以使用 file_uris() 方法始终获取完整路径,即使 Delta 表仅包含相对路径。
table.file_uris() # ['/Users/matthew.powers/Documents/code/my_apps/delta-examples/notebooks/delta-rs-python/example_table/part=b/0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquet',
'/Users/matthew.powers/Documents/code/my_apps/delta-examples/notebooks/delta-rs-python/example_table/part=a/0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquet']file_uris() 方法也可以通过谓词调用以获取文件子集。
table.file_uris([('part', '=', 'a')]) # ['/Users/matthew.powers/Documents/code/my_apps/delta-examples/notebooks/delta-rs-python/example_table/part=a/0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquet']手动创建检查点的能力
我们现在允许手动创建检查点。如果您执行了多次创建和删除许多文件(例如连续覆盖)的操作,但尚未达到自动检查点,这会很有用。
让我们查看上一节中创建的 Delta 表中的文件:
example_table
├── _delta_log
│ └── 00000000000000000000.json
├── part=a
│ └── 0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquet
└── part=b
└── 0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquet让我们使用新命令强制创建检查点。
table = DeltaTable("example_table")
table.create_checkpoint()这是创建检查点后 Delta 表中的文件:
example_table
├── _delta_log
│ ├── 00000000000000000000.checkpoint.parquet
│ ├── 00000000000000000000.json
│ └── _last_checkpoint
├── part=a
│ └── 0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquet
└── part=b
└── 0-49068bca-183d-4d15-89a8-9f9b90f609c0-0.parquet请注意,此命令将 00000000000000000000.checkpoint.parquet 和 _last_checkpoint 文件添加到了 Delta 表中。
检查点文件是一种从元数据条目快速重建表快照的方法。元数据也可以是“大数据”。读取和处理大量 JSON 元数据文件可能很慢。更有效的方法是定期将 JSON 元数据文件折叠到可以更快读取的 Parquet 检查点中。此命令使开发人员可以灵活地在需要时创建检查点,并使他们能够更好地控制其 Delta 表。
获取活动添加操作的 DataFrame
我们还有一个新的实验性 API,用于提供活动添加操作的表。活动添加操作是有关作为表一部分的文件集的元数据。这使您可以查看其分区值、记录计数和统计信息。此数据有助于了解压缩和 Z-order 对您的表的效果。
让我们创建一个包含三个事务的 Delta 表,并逐步查看每个步骤的添加操作。这是我们将创建的表:
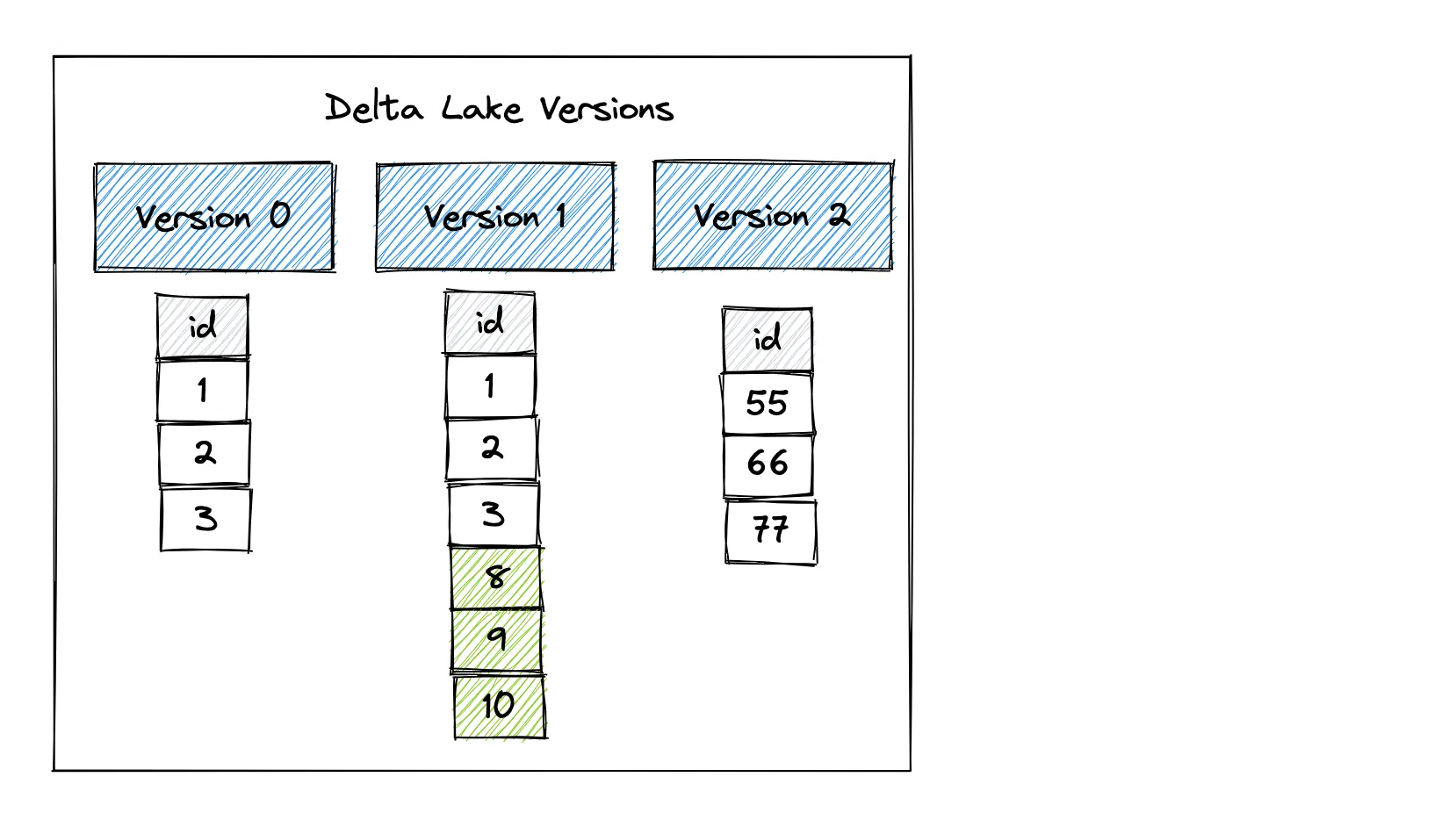
这是三个事务:
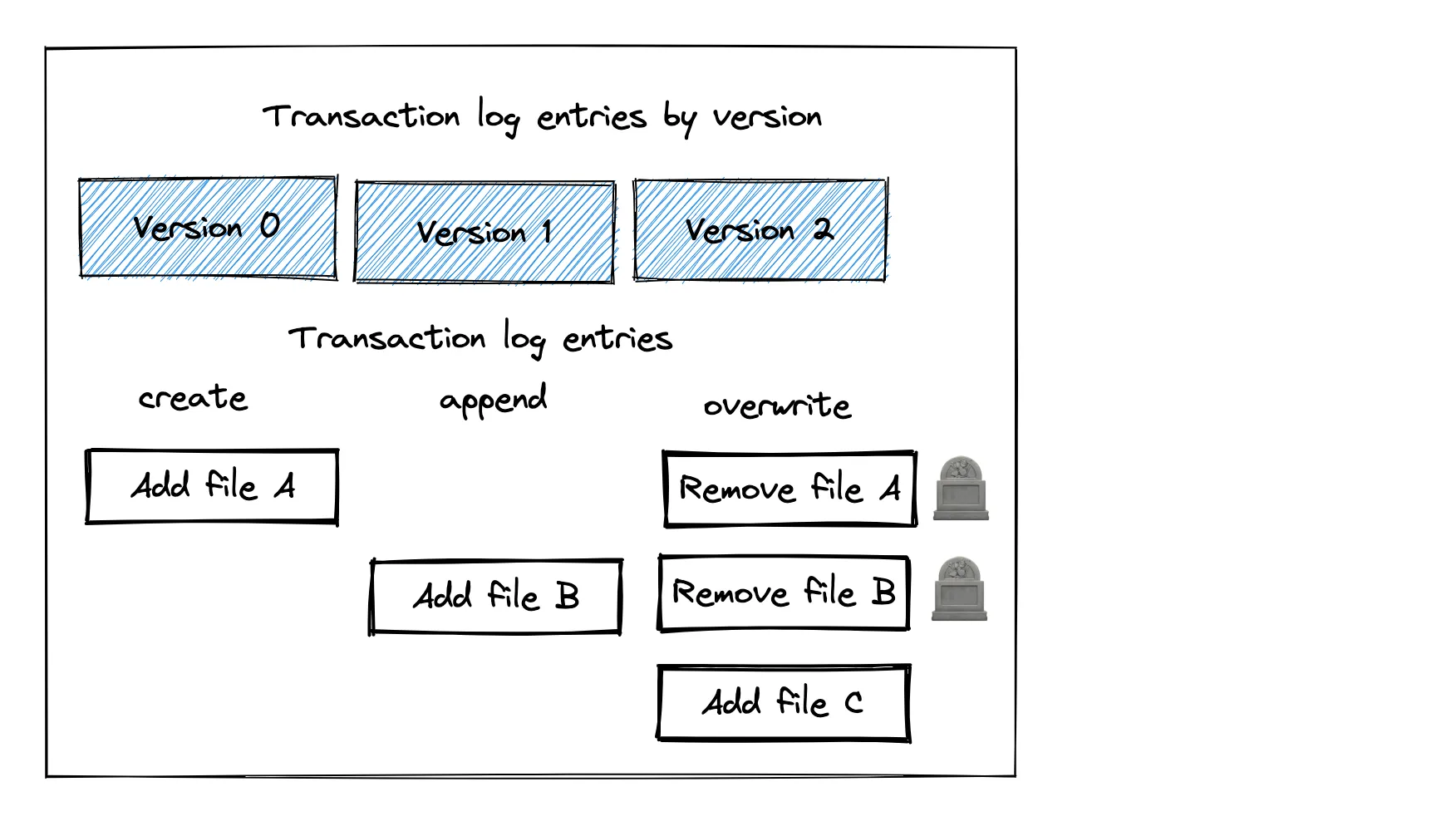
- 创建表
- 将数据追加到表
- 覆盖表
以下是每个操作的事务日志条目图示:
让我们从创建 Delta 表开始。
df = pd.DataFrame({"x": [1, 2, 3]})
write_deltalake("tmp/delta-table", df)现在让我们看一下添加操作:
table.get_add_actions(flatten=True).to_pandas()
+-------+------------+-------------+-------------+--------------+-------+-------+
| | size_bytes | data_change | num_records | null_count.x | min.x | max.x |
+-------+------------+-------------+-------------+--------------+-------+-------+
| fileA | 1654 | True | 3 | 0 | 1 | 3 |
+-------+------------+-------------+-------------+--------------+-------+-------+Delta 表最初只包含一个文件。字节数、行数以及 x 列的最小值/最大值都存储在添加操作日志中。请注意,我们使用“fileA”而不是真实的 Parquet 文件名来简化说明。
让我们将另一个 DataFrame 追加到 Delta 表。
df2 = pd.DataFrame({"x": [9, 8, 10]})
write_deltalake("tmp/delta-table", df2, mode="append")让我们看一下追加此 DataFrame 后的添加操作:
table = DeltaTable("tmp/delta-table")
table.get_add_actions(flatten=True).to_pandas()
+-------+------------+-------------+-------------+--------------+-------+-------+
| | size_bytes | data_change | num_records | null_count.x | min.x | max.x |
+-------+------------+-------------+-------------+--------------+-------+-------+
| fileA | 1654 | True | 3 | 0 | 1 | 3 |
| fileB | 1654 | True | 3 | 0 | 8 | 10 |
+-------+------------+-------------+-------------+--------------+-------+-------+Delta 表现在包含两个文件。您可以立即看到此元数据信息有多么有用。例如,假设您想获取 Delta 表中 x>5 的所有记录计数。您可以看到 Delta Lake 在执行此操作时如何跳过 fileA,因为 5 大于 max.x。添加操作表为您提供了关于在运行查询时可以跳过多少数据的强大洞察力。
现在让我们用不同的 DataFrame 覆盖 Delta 表。
df3 = pd.DataFrame({"x": [55, 66, 77]})
write_deltalake("tmp/delta-table", df3, mode="overwrite")让我们再次查看带有添加操作的表。
table = DeltaTable("tmp/delta-table")
table.get_add_actions(flatten=True).to_pandas()
+-------+------------+-------------+-------------+--------------+-------+-------+
| | size_bytes | data_change | num_records | null_count.x | min.x | max.x |
+-------+------------+-------------+-------------+--------------+-------+-------+
| fileC | 1654 | True | 3 | 0 | 55 | 77 |
+-------+------------+-------------+-------------+--------------+-------+-------+添加操作表不显示被覆盖操作墓碑化的文件。它只显示 Delta 表最新版本的活动文件。
结论
deltalake 0.7.0 版本为 Delta Lake 用户添加了激动人心的新功能。这些功能为高级用户提供了更多自定义 Delta Lake 工作流的能力。
文件列表 API 更简洁,您现在可以按命令手动检查点您的 Delta 表。您现在还可以访问添加操作表,该表可让您识别 Delta 表中小型文件的数量,并更深入地了解不同类型查询跳过的数据量。
添加操作提供了对 Delta 表的更多控制,而且它是一个仅限元数据的操作,因此速度很快。
delta-rs 团队在不断改进 deltalake 项目方面做得非常出色!