使用 OPTIMIZE 命令进行 Delta Lake 小文件压缩
这篇博客文章将向您展示如何使用 Delta Lake OPTIMIZE 命令将小文件压缩成大文件。您将了解为什么小文件压缩很重要,以及与普通数据湖相比,使用 Delta Lake 压缩小文件为什么更容易。
小文件之所以有问题,是因为它们会导致数据查询运行缓慢。它们需要大量的 I/O 开销,这在计算上是昂贵的。它们还会创建大型元数据事务日志,导致规划时间缓慢。Delta Lake 提供了一个 OPTIMIZE 命令,允许用户将小文件压缩成大文件,从而使他们的查询不会受到小文件开销的困扰。
下图展示了 Delta Lake 如何轻松地将小文件打包成合适大小的文件。
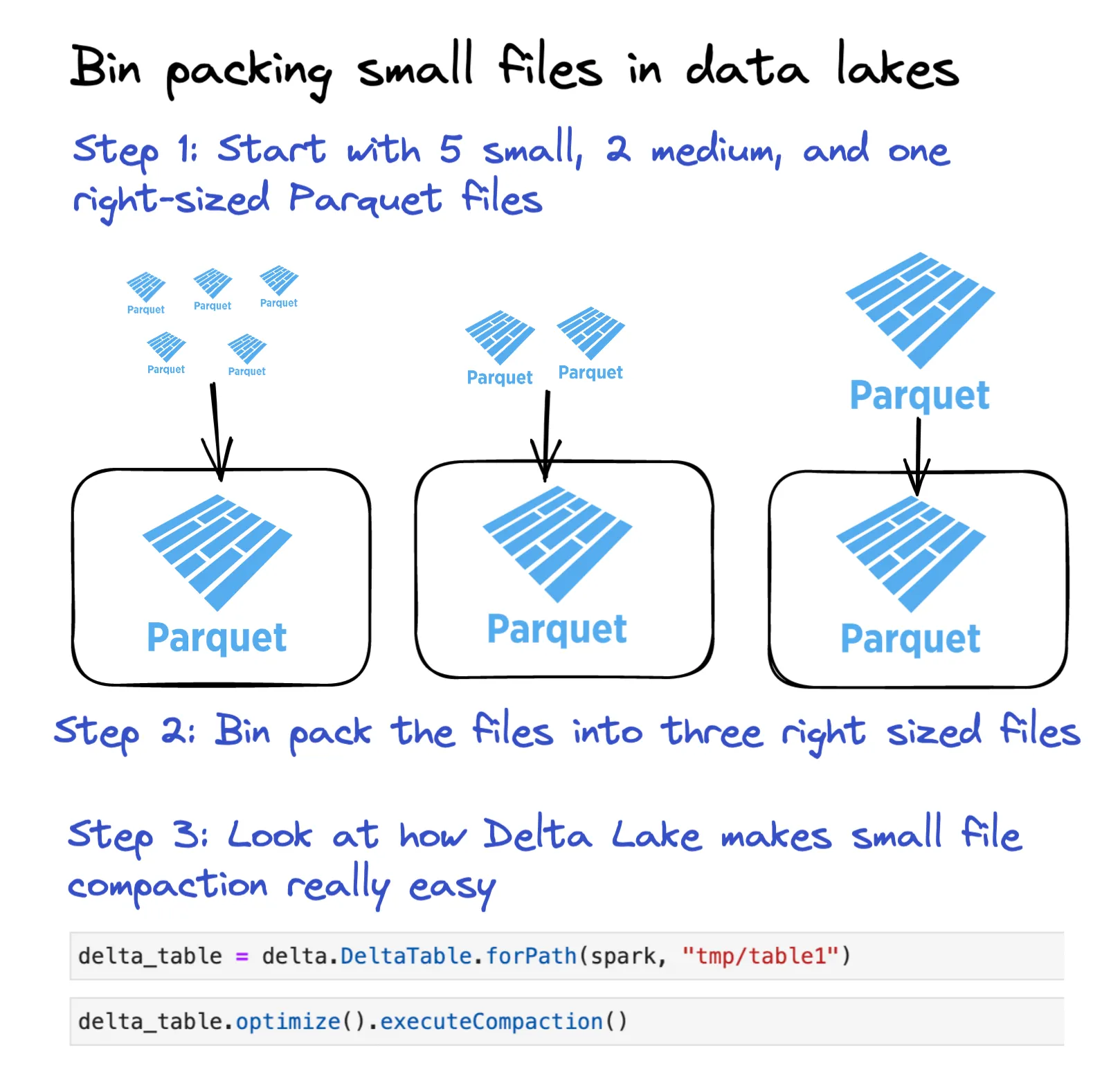
让我们通过一个例子来看看这个命令是如何工作的。
Delta Lake 使用 OPTIMIZE 进行小文件压缩示例
创建一个包含 5 行数据的 DataFrame。
df = spark.range(0, 5)将此 DataFrame 写入 Delta 表的多个文件中。
df.repartition(5).write.format("delta").save("tmp/table1")注意:我们使用 repartition(5),因此会输出多个文件。通常在写入数据时,您不会想使用 repartition(5)。
查看存储中持久化的文件。
tmp/table1
├── _delta_log
│ └── 00000000000000000000.json
├── part-00000-4dc9742a-7c76-4527-a2c6-d7904f56d05d-c000.snappy.parquet
├── part-00001-18179b66-48f0-4d47-8f21-762678a7df66-c000.snappy.parquet
├── part-00002-03f9116e-189e-4e55-bfe7-d501fffe4ced-c000.snappy.parquet
└── part-00003-81cad732-eeaf-4708-9111-aa2e8136e304-c000.snappy.parquet每个文件一行数据显然太小了。让我们使用 OPTIMIZE 命令将这些小文件压缩成更少、更大的文件。
from delta.tables import DeltaTable
delta_table = DeltaTable.forPath(spark, "tmp/table1")
delta_table.optimize().executeCompaction()我们可以看到这些小文件已经被压缩成一个文件。当然,一个只有 5 行数据的单个文件仍然太小了——我们只是使用这个微型示例来演示 OPTIMIZE 的功能。
让我们清理 Delta 表并列出文件,以证明所有数据现在都在一个文件中。
spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled", "false")
delta_table.vacuum(0)注意:将保留期设置为零将阻止您回滚和时间旅行到以前的版本。我们这样做只是为了演示 OPTIMIZE 命令的功能。
这是清理后的 Delta 表中的文件。
tmp/table1
├── _delta_log
│ ├── 00000000000000000000.json
│ └── 00000000000000000001.json
└── part-00000-2b164d47-0f85-47e1-99dc-d136c784baaa-c000.snappy.parquet事务日志包含两个条目。第一个条目是 Delta 表最初创建时的,第二个条目是 OPTIMIZE 命令的。让我们看看 00000000000000000001.json 文件的内容。
{
"add": {
"path": "part-00000-2b164d47-0f85-47e1-99dc-d136c784baaa-c000.snappy.parquet",
"partitionValues": {},
"size": 504,
"modificationTime": 1671468211798,
"dataChange": false,
"stats": "{\"numRecords\":5,\"minValues\":{\"id\":0},\"maxValues\":{\"id\":4},\"nullCount\":{\"id\":0}}"
}
}
{
"remove": {
"path": "part-00003-81cad732-eeaf-4708-9111-aa2e8136e304-c000.snappy.parquet",
"deletionTimestamp": 1671468210066,
"dataChange": false,
"extendedFileMetadata": true,
"partitionValues": {},
"size": 478
}
}
The other small files are also removed…OPTIMIZE 命令将所有小数据文件标记为已删除,并添加了一个包含所有压缩数据的大文件。请注意,对于所有添加和删除的文件,dataChange 都设置为 false。
压缩操作不会向 Delta 表添加任何新数据。它只是将现有数据从小文件重新组织到大文件中。当您有下游作业监视您的 Delta 表并在新文件到达时进行增量更新时,这非常有用。dataChange 标志区分了为了压缩目的而重新组织到大文件中的数据与已摄取到 Delta 表中的全新数据。
让我们看看 Delta Lake 在运行 OPTIMIZE 时目标文件大小是多少。
Delta Lake 目标文件大小
Delta Lake 在运行 OPTIMIZE 时目标是 1 GB 的文件。1 GB 的默认文件大小是根据多年客户使用经验选择的,表明此文件大小在常见的计算实例上运行良好。
您可以通过设置 spark.databricks.delta.optimize.maxFileSize 属性来配置此属性。这使您可以设置与默认值不同的目标文件大小。
经过多年在大量 Spark 工作负载上的测试,1 GB 的默认文件大小已被证明是稳健的。除非您有充分的理由使用不同的文件大小,否则您应该坚持使用默认值。
带有谓词过滤的 Delta Lake OPTIMIZE
您可以指定谓词来只压缩数据的一个子集。这是一个好主意,特别是如果您每天在同一个数据集上运行压缩作业。您不需要浪费计算资源来分析已经压缩过的数据文件。
假设您有一个按天分区的 Delta 表,并且您有一个每日作业来压缩小文件。以下是如何只压缩前一天(本例中为 2021 年 11 月 18 日)添加的新文件。
deltaTable.optimize().where("date='2021-11-18'").executeCompaction()这是一种在增量更新的 Delta 表上构建压缩作业的好方法,因为它避免了您扫描已经压缩过的文件。您应该尽可能地压缩最小数据集。
Delta Lake 1.2 版本之前的小文件压缩
OPTIMIZE 在 Delta Lake 1.2 版本中添加(Python 绑定在 2.0 版本中添加)。以下是您如何在 1.2 版本之前的 Delta Lake 版本中手动压缩小文件。让我们创建一些文件来演示一个例子。
创建一个包含大量小文件的独立 Delta 表
df = spark.range(0, 5)
df.repartition(5).write.format("delta").save("tmp/table2")以下是如何在不使用 OPTIMIZE 命令的情况下压缩小文件。
path = "tmp/table2"
numFiles = 1
(
spark.read.format("delta")
.load(path)
.repartition(numFiles)
.write.option("dataChange", "false")
.format("delta")
.mode("overwrite")
.save(path)
)让我们清理表以证明数据已被压缩到一个文件中。
delta_table = delta.DeltaTable.forPath(spark, "tmp/table2")
delta_table.vacuum(0)只剩下一个数据文件。
tmp/table2
├── _delta_log
│ ├── 00000000000000000000.json
│ └── 00000000000000000001.json
└── part-00000-2f60eca6-07ba-4f66-a89c-eab5caa94d25-c000.snappy.parquet手动压缩文件效率低下且容易出错。
- 用户需要正确设置文件数量。找出在压缩 Delta 表时应该使用的最佳文件数量并不容易。
- 用户需要重写整个数据集,包括小文件和大文件。这可能效率非常低,特别是如果大多数数据都在大小合适的文件中,而只有一些小文件。
OPTIMIZE 命令提供了更好的用户体验。
什么导致小文件?
小数据文件有三个主要原因:
- 用户错误:用户可以重新分区数据集并以任意数量的文件写入数据。假设您有一个 500 GB 的数据集。用户可以使用
repartition(100000)将该数据集写入 100,000 个文件。这将导致小文件问题。 - Hive 分区或过度分区的数据集:磁盘分区需要按分区键将数据分割到不同的文件中。如果数据集在基数高的列上分区,或者存在深度嵌套的分区,那么将创建更多的小文件。假设您有一个 1 GB 的数据集。如果它被写入一个非分区表,那么数据可以作为一个文件写入。如果数据被写入一个带有 5,000 个唯一值的分区键的 Hive 分区表,那么在写入时将创建多达 5,000 个文件。
- 频繁增量更新的表:表更新越频繁,创建的小文件就越多。每 2 分钟更新一次表的作业将比每 8 小时运行一次的作业创建更多的小文件。请记住,有些表会频繁更新以提供查询的新鲜度。
“解决”小文件问题的理想方法是构建系统,使其首先不创建小文件。有时,考虑到业务和查询延迟要求,小文件是不可避免的,但有时它们是可以避免的。例如,您可以通过使用 Z ORDER 来避免由 Hive 样式分区引起的小文件问题,Z ORDER 可以提供类似的文件跳过功能。
让我们深入探讨端到端查询延迟与小文件之间的权衡。
ETL 延迟与小文件的权衡
假设您有一个 ETL 管道,每天摄取 5GB 数据。流式数据被摄取到 Delta 表中,并通过 BI 应用程序由最终用户查询。
如果增量更新作业设置为每 5 分钟运行一次,那么管道每天将创建至少 288 个小文件。
如果增量更新作业设置为每天运行,那么它可以配置为追加五个 1GB 的文件。这种设置不会创建任何小文件。
最佳解决方案取决于 BI 用户的需求。
- 如果 BI 用户需要全天刷新他们的仪表板并根据最新数据做出决策,那么需要频繁更新。
- 如果 BI 用户每天只加载仪表板一次以生成报告,那么不需要每 5 分钟更新一次。
具有更长更新延迟的 ETL 管道具有更少的小文件。通常,您应该构建 ETL 管道,使其具有业务要求可接受的最高延迟,以最大程度地减少创建的小文件数量。
何时在 Delta Lake 上运行 OPTIMIZE
OPTIMIZE 命令用于解决小文件问题,并且只要有足够的小文件来证明运行压缩操作是合理的,就应该运行它。
如果只有少量小文件,那么您不需要运行 OPTIMIZE。小文件开销只有在存在大量小文件时才会开始成为性能问题。
您也不需要对已经压缩过的数据运行 OPTIMIZE。如果您有一个增量更新作业,请确保指定谓词以仅压缩新添加的数据。
为什么 Delta Lake 的 OPTIMIZE 优于数据湖压缩
压缩小文件对于数据湖来说是一个出人意料的难题。
- 在您运行压缩操作时,您的数据湖将处于不可用的状态,供读取器使用。数据湖不支持 ACID 事务。
- 在数据湖上运行压缩操作具有风险。您需要在压缩后手动删除小文件,这容易出错。
- 数据湖没有
dataChange=false标志来区分包含新数据的文件和包含已压缩到新文件中的现有数据的文件。监视新数据文件的下游 ETL 进程将像处理新数据一样重新处理压缩的数据文件,而对于数据湖,它们会重新处理所有文件。
像大多数数据操作一样,OPTIMIZE 命令受益于 Delta Lake 支持的 ACID 事务。使用 Delta Lake,您可以通过一个命令安全地压缩小文件。而对于数据湖,您必须编写自定义逻辑并以危险的方式压缩小文件。
Delta Lake Bin Packing(装箱)
压缩小文件是装箱问题的一个例子:如何将大小不等的物品放入有限数量的容器中。
装箱是计算机科学中的一个通用挑战,即构建一种算法,能够有效地将文件组织成大小相等的容器。Delta Lake 的 OPTIMIZE 命令使用装箱算法将小文件压缩成大小合适的文件。以下是装箱算法的高级工作原理:
- 过滤所有文件,只选择小于 maxFileSize (默认 1GB) 的文件。
- 将它们按顺序添加到“箱子”中,直到箱子达到约 1GB。
- 每次箱子溢出时,都会开始一个新的箱子。
- 这针对每个分区发生。
Delta Lake OPTIMIZE 与 Z ORDER
Delta Lake 的 OPTIMIZE 和 Z ORDER 命令服务于完全不同的目的,但它们经常结合使用。
Optimize 用于压缩 Delta 表中的小文件。Z ORDER 用于智能排序数据,以便在运行常见查询时更有可能跳过文件。
有关更多信息,请参阅Z ORDER 文档。
结论
这篇文章教您如何压缩小数据文件,为什么这会提高您的查询时间,以及 Delta Lake 如何通过 OPTIMIZE 命令使此操作变得容易。
您了解了小数据文件的常见原因以及如何构建不太可能创建小数据文件的 ETL 管道。
您还了解了为什么 Delta Lake 是小文件压缩的绝佳技术。Delta Lake 的 ACID 事务使 OPTIMIZE 命令安全。Delta Lake dataChange 标志还允许您构建管道,以区分最近摄取的数据和实际上只包含您已经处理过的旧数据的“新”数据文件。
OPTIMIZE 是一项重要的性能优化,您现在已经掌握了充分利用该命令的强大功能。