在 Delta Lake 表中添加和删除分区
作者:Matthew Powers 、 Ryan Zhu
这篇博文将向您展示如何在 Delta 表中添加和删除分区。您将了解为什么 Delta Lake 没有像 Hive 那样的 ADD PARTITION 和 DROP PARTITION 命令,以及 Delta Lake 如何以不同方式处理 Hive 风格的分区。
让我们从创建分区 Delta 表开始,然后看看如何添加和删除分区。如果您想跟着操作,这篇博文中的所有代码都在此笔记本中。
创建带分区的 Delta Lake 表
首先创建一个包含 first_name、last_name 和 country 列的 DataFrame。
df = spark.createDataFrame(
[
("Ernesto", "Guevara", "Argentina"),
("Maria", "Sharapova", "Russia"),
("Bruce", "Lee", "China"),
("Jack", "Ma", "China"),
]
).toDF("first_name", "last_name", "country")将 DataFrame 写入名为 country_people 的 Delta 表
df.repartition(F.col("country")).write.partitionBy("country").format(
"delta"
).saveAsTable("country_people")这是 Delta 表的内容
spark-warehouse/country_people
├── _delta_log
│ └── 00000000000000000000.json
├── country=Argentina
│ └── part-00000-03ceafc8-b9b5-4309-8457-6e50814aaa8b.c000.snappy.parquet
├── country=China
│ └── part-00000-9a8d67fa-c23d-41a4-b570-a45405f9ad78.c000.snappy.parquet
└── country=Russia
└── part-00000-c49ca623-ea69-4088-8d85-c7c2de30cc28.c000.snappy.parquetDelta 表由一个包含事务条目的 _delta_log 文件夹组成。数据存储在嵌套目录中的 Parquet 文件中,完全遵循 Hive 分区约定。
让我们看看如何向 Delta 表添加一个额外的分区。
向 Delta Lake 表添加分区
让我们创建另一个包含一些哥伦比亚人的 DataFrame。
df = spark.createDataFrame(
[
("Orlando", "Cabrera", "Colombia"),
("Carlos", "Vives", "Colombia"),
]
).toDF("first_name", "last_name", "country")将此 DataFrame 追加到分区 Delta 表
df.repartition(F.col("country")).write.mode("append").partitionBy("country").format(
"delta"
).saveAsTable("country_people")查看 Delta 表的内容。您会注意到 Delta 表现在包含一个 country=Colombia 分区,其中包含新追加的数据。
spark-warehouse/country_people
├── _delta_log
│ ├── 00000000000000000000.json
│ └── 00000000000000000001.json
├── country=Argentina
│ └── part-00000-03ceafc8-b9b5-4309-8457-6e50814aaa8b.c000.snappy.parquet
├── country=China
│ └── part-00000-9a8d67fa-c23d-41a4-b570-a45405f9ad78.c000.snappy.parquet
├── country=Colombia
│ └── part-00000-7e3d3d49-39e9-4eb2-ab92-22a485291f91.c000.snappy.parquet
└── country=Russia
└── part-00000-c49ca623-ea69-4088-8d85-c7c2de30cc28.c000.snappy.parquet您可以使用 ADD PARTITION 命令向 Hive 中的表添加分区。使用 Delta Lake,您只需追加数据,它就会自动创建新分区。如果分区已存在,数据将追加到现有分区。
从 Delta Lake 表中删除分区
您可以删除给定分区中的所有行,以从 Delta 表中删除该分区。
以下是删除所有阿根廷人行的方法。
dt = delta.DeltaTable.forName(spark, "country_people")
dt.delete(F.col("country") == "Argentina")让我们运行两次 vacuum 并观察阿根廷分区如何从文件系统中删除。
spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled", "false")
spark.sql("VACUUM country_people RETAIN 0 HOURS")
spark.sql("VACUUM country_people RETAIN 0 HOURS")注意:在此示例中,我们仅将保留期设置为 0 小时,以演示磁盘结构更改。保留期通常应至少为 7 天。0 小时的保留期是危险的,因为它可能会破坏并发写入操作和时间旅行。
查看文件系统内容并确保阿根廷分区已被删除。
spark-warehouse/country_people
├── _delta_log
│ ├── 00000000000000000000.json
│ ├── 00000000000000000001.json
│ └── 00000000000000000002.json
├── country=China
│ └── part-00000-9a8d67fa-c23d-41a4-b570-a45405f9ad78.c000.snappy.parquet
├── country=Colombia
│ └── part-00000-7e3d3d49-39e9-4eb2-ab92-22a485291f91.c000.snappy.parquet
└── country=Russia
└── part-00000-c49ca623-ea69-4088-8d85-c7c2de30cc28.c000.snappy.parquet您需要运行两次 vacuum 才能完全删除阿根廷分区。第一次 vacuum 运行会删除包含阿根廷数据的文件,阿根廷目录变空。第二次 vacuum 运行会删除空的阿根廷目录。通常您不需要运行两次 vacuum 才能使所有更改生效,但这是一个特殊的边缘情况。请参阅这篇博文以了解有关 vacuum 命令的更多信息。
Delta Lake 与 Hive 处理分区的方式有何不同
分区用于跳过某些查询的数据,这是一种性能优化。假设您要运行此查询:SELECT * FROM country_people where country = 'China'。执行引擎可以识别表已分区,并且只读取 country=China 目录中的文件。以这种方式跳过数据可以极大地优化查询性能。
然而,与 Hive 依赖目录结构来组织分区并需要执行文件列表操作来查找分区中的文件不同,Delta 表在事务日志中存储带有表元数据信息的元数据信息,如下图所示
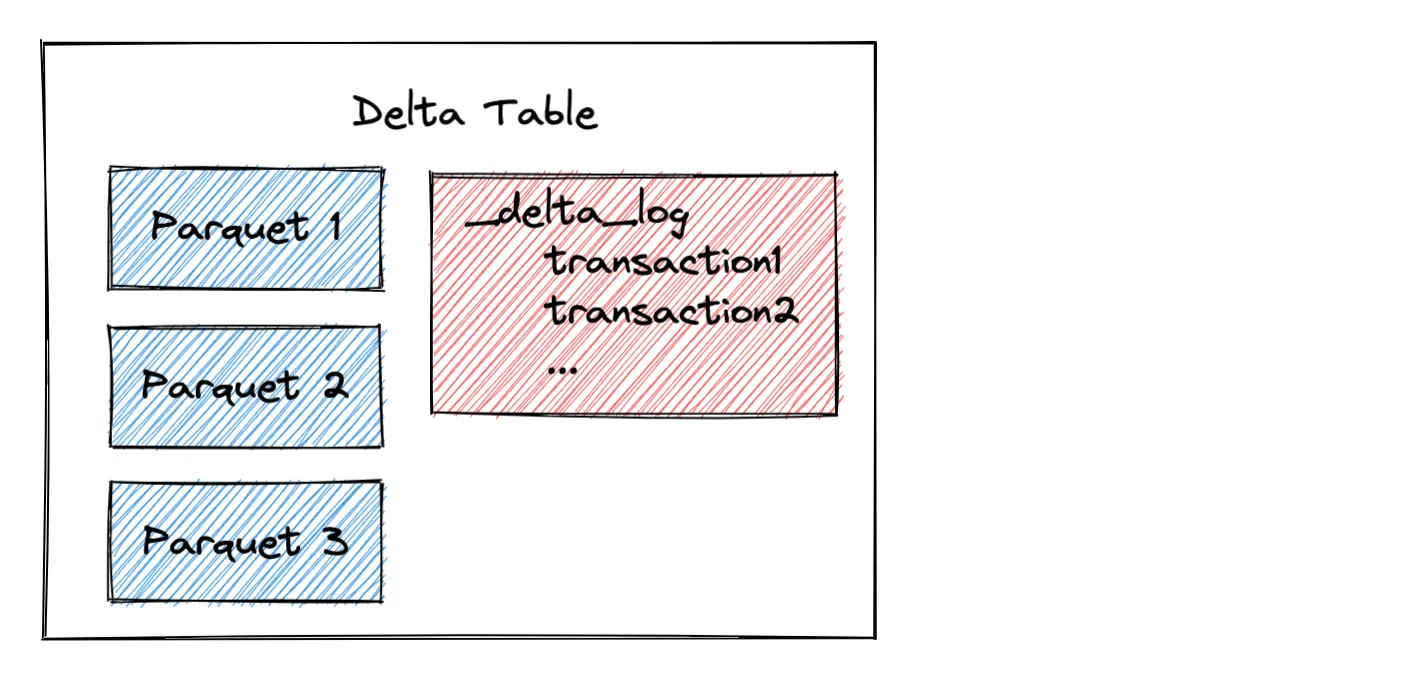
当 Delta Lake 读取分区数据集时,它会分析事务日志以识别查询的相关文件。Delta Lake 可以从事务日志中识别给定分区的相关文件——它不需要像 Hive 那样查看文件系统并执行文件列表操作。
文件列表操作可能很慢,即使对于给定分区也是如此。有些分区包含大量文件。最好直接从事务日志中获取文件,而不是执行文件列表操作。
为什么 Delta Lake 遵循 Hive 风格的磁盘布局
Delta Lake 遵循 Hive 风格的磁盘布局,即使在读取文件时未使用磁盘布局,因为 Delta Lake 旨在与旧系统兼容。Delta Lake 可以通过将保留期设置为零、运行 vacuum 命令和删除 _delta_log 目录来转换为“常规 Parquet 数据湖”。使用 Delta Lake 不存在锁定——您可以转换为 Parquet 表。
Delta Lake 不需要像 Hive 那样特殊的磁盘布局来进行性能优化。Delta Lake 依赖事务日志中的文件元数据信息来识别查询的相关文件。它不使用目录和文件列表操作来读取数据。
为什么 Hive 需要 ADD PARTITION 和 DROP PARTITION 命令
Hive 需要 ADD PARTITION 和 DROP PARTITION 命令来处理以下类型的情况
- 当用户对磁盘上的目录执行未反映在 Hive 元存储中的操作时(这对于外部表来说并不少见)
- 当查询崩溃导致 Hive 元存储中的目录和分区信息不一致时。用户需要手动在 Hive 元存储中添加/删除分区以反映磁盘上的更改。否则,Hive 将忽略新目录或尝试读取已删除的目录。
ADD PARTITION 和 DROP PARTITION Hive 命令用于手动将磁盘上的数据与 Hive 元存储同步(一些服务提供商将其作为自动发现过程提供)。不用说,这是一种糟糕的用户体验。
Delta Lake 将分区数据存储在事务日志中。得益于 ACID,Delta Lake 表中的元数据和日期文件始终一致,不会出现不同步的情况。更好的设计消除了对传统分区命令的需求。
结论
使用 Delta Lake,创建 Hive 风格的分区数据集、添加分区和删除分区都非常容易。Delta Lake 不明确支持 ADD PARTITION 和 DROP PARTITION 等传统 Hive 分区命令语法,因为它们是不必要的。您只需运行常规 Delta 表命令,分区将根据需要自动添加和删除。