将 Delta Lake 表读取到 Polars DataFrame 中
将 Delta Lake 表读取到 Polars DataFrame 中
本文将向您展示如何使用 Polars DataFrame 库读取 Delta Lake 表,并解释使用 Delta Lake 而非其他数据集格式(如 AVRO、Parquet 或 CSV)的优势。
Polars 是一个主要用 Rust 编写的优秀 DataFrame 库,它使用 Apache Arrow 格式作为其内存模型。Delta Lake 是一个 Lakehouse 存储系统,为流式和批处理操作提供可靠性、安全性和性能。
Polars 具有极快的性能,而 Delta Lake 具有 ACID 事务、时间旅行、Schema 强制等强大功能,因此它们是天作之合。让我们深入研究一些代码!
创建 Delta 表
让我们创建一个具有三个不同版本的 Delta 表。这将使我们能够使用 Polars 轻松演示 Delta 表不同版本之间的时间旅行。
这是我们将要创建的具有三个版本的 Delta 表。
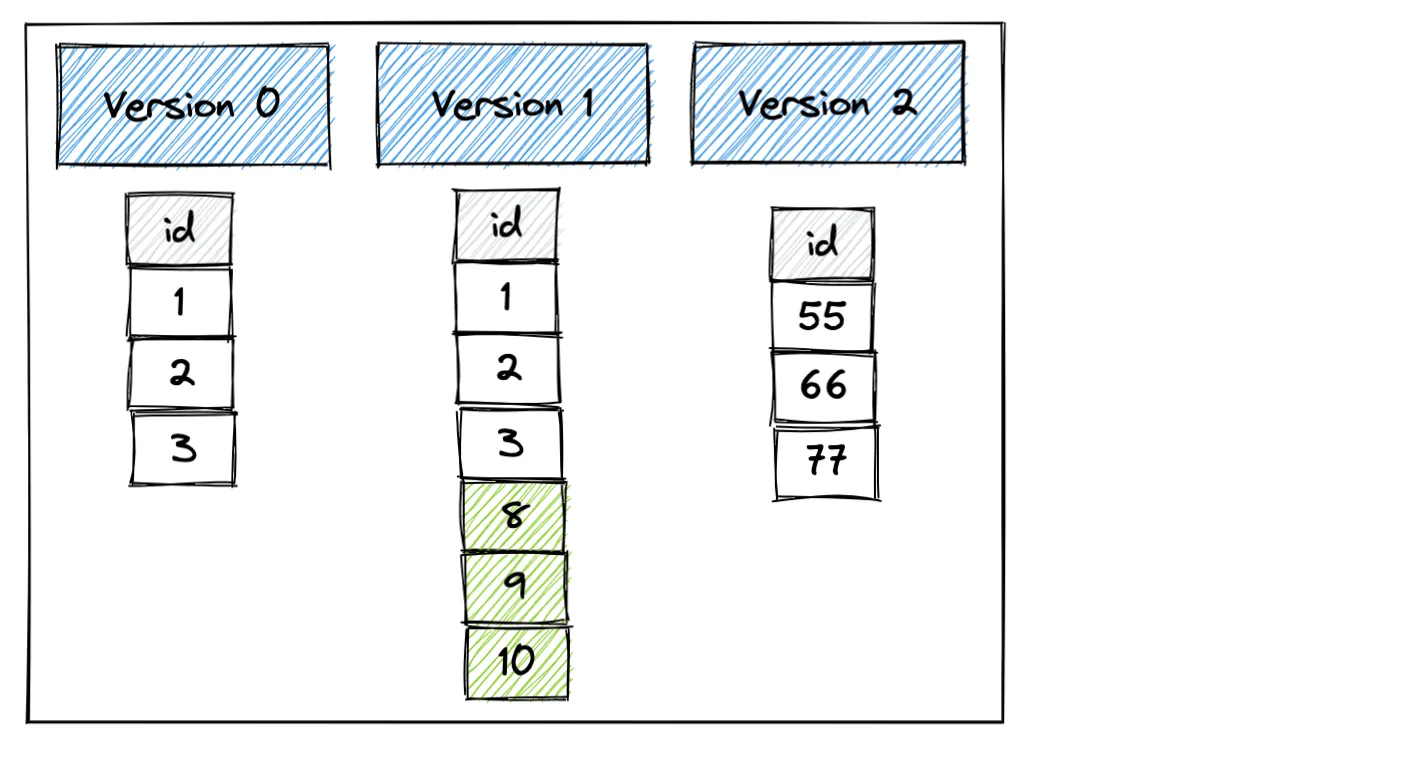
让我们首先使用 pandas 创建 Delta 表的第 0 个版本。
from deltalake.writer import write_deltalake
import pandas as pd
df = pd.DataFrame({"x": [1, 2, 3]})
write_deltalake("/tmp/bear_delta_lake", df)现在,让我们将另一个 DataFrame 附加到现有的 Delta 表中,这将创建第 1 个版本。
df2 = pd.DataFrame({"x": [9, 8, 10]})
write_deltalake("/tmp/bear_delta_lake", df2, mode="append")现在,让我们覆盖 Delta 表,这将删除现有数据并添加新数据。此操作将创建 Delta 表的第 2 个版本。
df3 = pd.DataFrame({"x": [55, 66, 77]})
write_deltalake("/tmp/bear_delta_lake", df3, mode="overwrite")我们已经创建了一个包含三个版本的 Delta 表。现在让我们使用 Polars 读取 Delta 表。
使用 Polars 读取 Delta 表
以下是如何使用 Polars 读取 Delta 表的最新版本。
import polars as pl
print(pl.read_delta("/tmp/bear_delta_lake"))这是打印出来的 DataFrame
+-----+
| x |
| --- |
| i64 |
+=====+
| 55 |
|-----|
| 66 |
|-----|
| 77 |
+-----+您还可以使用 scan_delta 读取 DataFrame,它将惰性地读取 Delta 表。另一方面,read_delta 方法会立即将 Delta 表加载到内存中。
ldf = pl.scan_delta("/tmp/bear_delta_lake")
print(ldf.collect())
+-----+
| x |
| --- |
| i64 |
+=====+
| 55 |
|-----|
| 66 |
|-----|
| 77 |
+-----+Polars 将使用 Delta 表事务日志仅读取所需的文件。Polars 将在对惰性 DataFrame 执行任何工作之前优化计算。
使用 Polars 时间旅行到不同版本
scan_delta 和 read_delta 方法默认会读取 Delta 表的最新版本。让我们看看如何通过设置版本参数轻松地在 Delta 表的不同版本之间进行时间旅行。
首先读取 Delta 表的第 0 个版本。
print(pl.read_delta("/tmp/bear_delta_lake", version=0))
+-----+
| x |
| --- |
| i64 |
+=====+
| 1 |
|-----|
| 2 |
|-----|
| 3 |
+-----+现在读取 Delta 表的第 1 个版本。
print(pl.read_delta("/tmp/bear_delta_lake", version=1))
+-----+
| x |
| --- |
| i64 |
+=====+
| 1 |
|-----|
| 2 |
|-----|
| 3 |
|-----|
| 9 |
|-----|
| 8 |
|-----|
| 10 |
+-----+Polars Delta Lake 连接器非常智能,只会读取每个版本所需的数据文件。Delta 表的第 0 个版本只需要一个数据文件,所以 Polars 只会读取它。时间旅行的执行效率很高。
Polars 如何在 Delta Lake 表上执行查询
Delta 表将数据存储在 Parquet 文件中,并将元数据信息存储在事务日志中。下图显示了 Delta 表的高级架构。
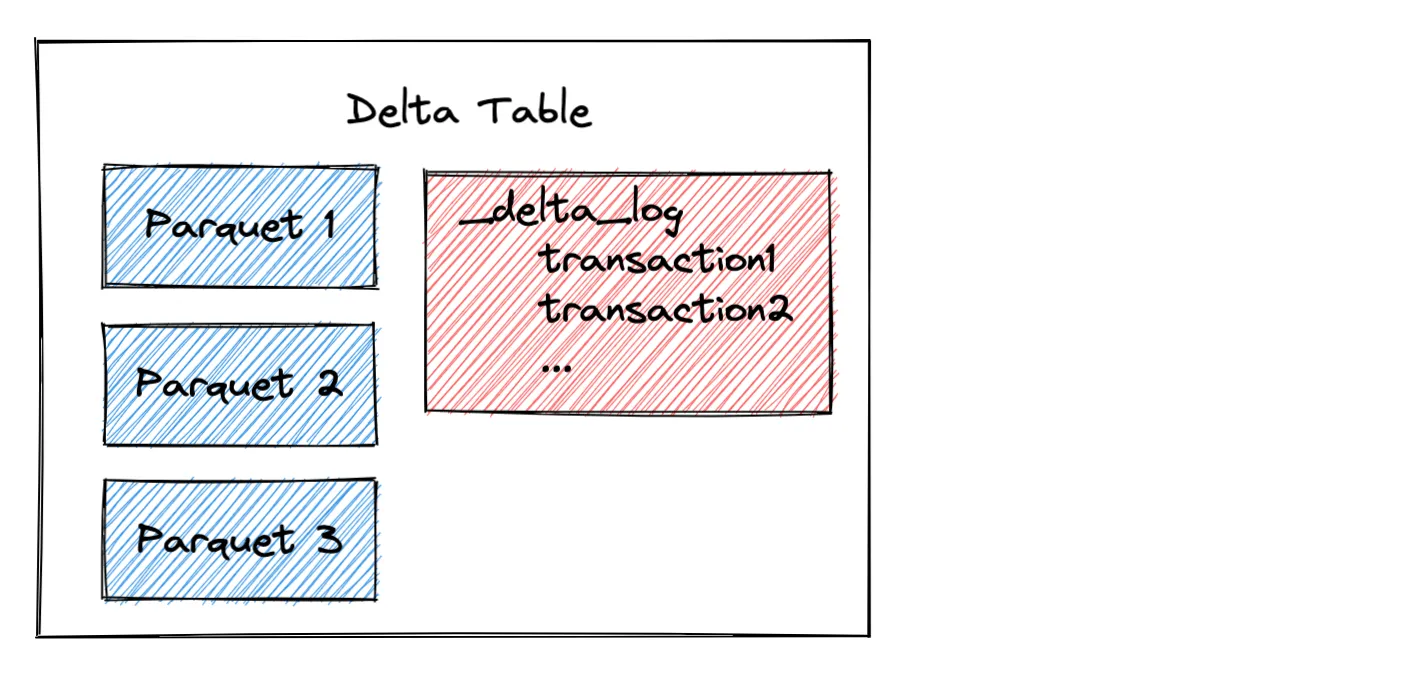
Polars 不会天真地运行您的查询,而是会优化您的查询并确保只从 I/O 中读取所需的列和行。这与 delta 表非常契合,因为 Polars 可以查询事务日志以查看需要哪些数据文件。
查询事务日志比读取每个单独 Parquet 文件的页脚、构建所有数据表元数据然后执行查询要高效得多。对于云对象存储上的嵌套目录尤其如此。
为什么 Delta Lake 有助于 Polars 用户
Delta Lake 为 Polars 用户在各种不同的存储系统(包括流行的云)上提供可靠的 ACID 事务保证。ACID 事务向用户保证操作将完全完成或根本不完成。用户不希望操作部分完成然后中途出错,从而损坏他们的数据集。
此博客演示了用户如何有效地时间旅行到现有 Delta 表的不同版本,这是生产数据工作负载的另一个强大功能。
随着更多功能的添加,Delta Lake 将为 Polars 用户带来更多价值。
未来工作
Polars Delta Lake 连接器依赖于 delta-rs,这是 Delta Lake 协议的 Rust 实现。
Delta Rust 正在积极开发中,新功能包括 DML 事务、回滚、列映射、Z ORDER、优化等。对写入 Delta Lake 表和其他高级功能的支持将很快添加。
安装 Delta Lake 和 Polars
安装 Polars 和 Delta Lake 最简单的方法是通过 pip
$ pip install polars[deltalake].
您也可以使用 conda 安装。以下是如何使用 Delta Lake、Polars、Jupyter 和其他方便的依赖项创建 conda 环境。首先创建一个包含依赖项的 YML 文件。
name: delta-polars
channels:
- conda-forge
- defaults
dependencies:
- python=3.9
- ipykernel
- nb_conda
- jupyterlab
- jupyterlab_code_formatter
- isort
- black
- pytest
- pandas
- pip
- pip:
- deltalake==0.6.4
- polars==0.15.7注意:使用 Polars 集成时,请使用 deltalake >= 0.6.2。
使用 conda env create -f envs/delta-polars.yml 创建环境。
使用 conda activate delta-polars 激活环境。
运行 jupyter lab 启动一个笔记本,访问此环境和所需的依赖项。
结论
Polars 是一个很棒的 DataFrame 库。它具有优雅的 API 和快速的性能。
Delta Lake 是一个很棒的 Lakehouse 存储系统,它为用户提供可靠的事务保证和许多便捷的数据管理功能。感谢 Delta Rust 项目,将 Delta Lake 支持添加到 Polars 相对容易。
这两个项目也是 Rust 原生库的绝佳示例,它们在 Python 领域突破了界限。
有关不同 Delta Lake 读取和扫描场景的更多信息,请参阅 Polars 文档。