如何从 Delta Lake 表中删除行
Delta Lake 可以轻松高效地从 Delta 表中删除行。
本文将向您展示如何从 Delta 表中删除行,以及事务在底层是如何实现的,以便您了解 Delta Lake 如何快速执行计算。
您还将了解为什么 Delta Lake 的删除操作比数据湖更好。如果您想在学习的同时在您的机器上运行这些计算,所有计算都可以在此笔记本中找到。
重要提示:启用删除向量后,删除行会显著加快,更多信息请参阅这篇博客文章。
Delta Lake 删除行示例
让我们创建一个 Delta 表,其中包含来自两个写入事务的数据。首先创建一个 DataFrame,然后将其写入 Delta 表
df = spark.createDataFrame([("bob", 3), ("sue", 5)]).toDF("first_name", "age")
df.repartition(1).write.format("delta").save("tmp/sunny-table")注意:我们使用 repartition(1) 输出单个文件以简化演示。
现在创建另一个 DataFrame 并将其追加到现有的 Delta 表
df = spark.createDataFrame([("ingrid", 58), ("luisa", 87)]).toDF("first_name", "age")
df.repartition(1).write.mode("append").format("delta").save("tmp/sunny-table")让我们检查 Delta 表的内容,确保它包含所有数据。
spark.read.format("delta").load("tmp/sunny-table").show()
+----------+---+
|first_name|age|
+----------+---+
| ingrid| 58|
| luisa| 87|
| bob| 3|
| sue| 5|
+----------+---+我们的 Delta Lake 目前包含两个文件,如下图所示
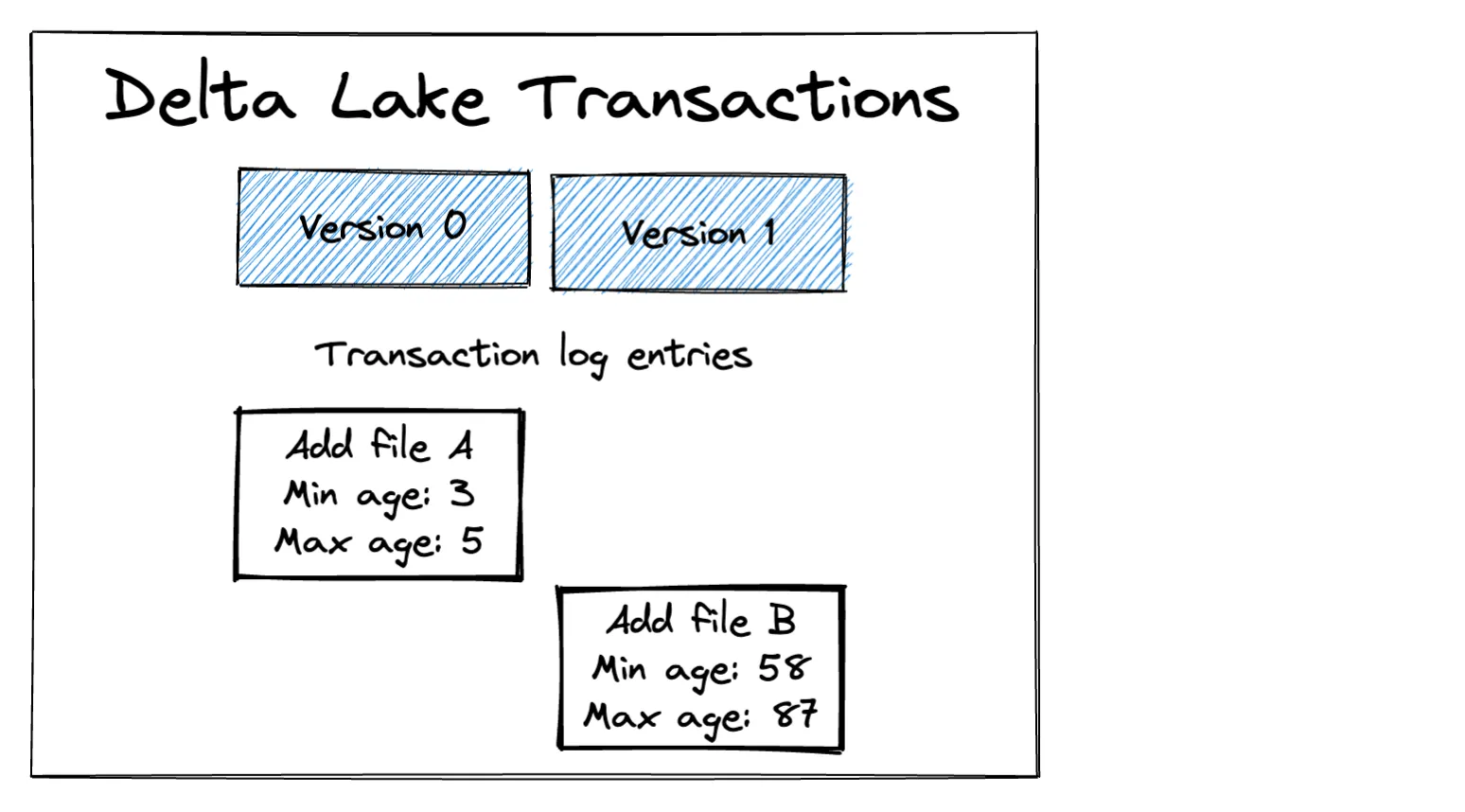
请注意 Delta 事务日志如何存储每个文件中每个列的最小/最大值。此元数据用于优化删除操作。
删除所有年龄大于 75 的行。
import delta
import pyspark.sql.functions as F
dt = delta.DeltaTable.forPath(spark, "tmp/sunny-table")
dt.delete(F.col("age") > 75)读取 Delta 表的内容并确保行已删除。
spark.read.format("delta").load("tmp/sunny-table").show()
+----------+---+
|first_name|age|
+----------+---+
| ingrid| 58|
| bob| 3|
| sue| 5|
+----------+---+Delta Lake 可以轻松地从 Delta 表中删除行。让我们看看 Delta Lake 如何在底层实现删除事务。
Delta Lake 如何在事务日志中记录删除事务
让我们看看 Delta Lake 如何在事务日志中记录删除操作。Delta Lake 删除操作会添加一个新事务,该事务会标记所有包含应删除数据的文件,并添加已过滤掉已删除行的新文件。
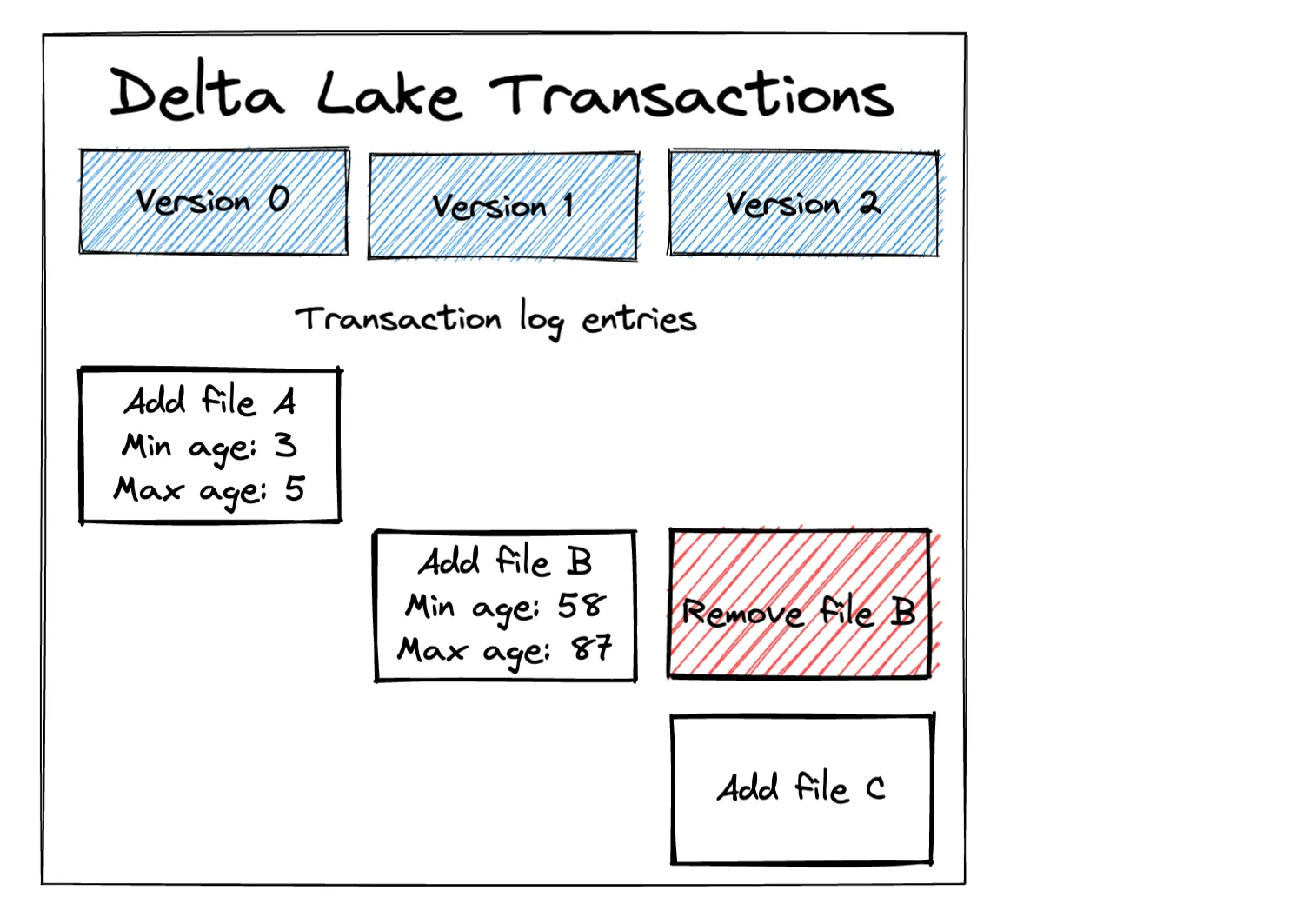
文件 C 包含文件 B 的所有数据,除了已删除的行。
文件 A 未更改,因为 Delta Lake 知道它不包含任何应删除的行(基于文件级元数据)。文件 A 中的最高年龄仅为 5,因此它显然不包含任何年龄大于 75 的数据行。Delta Lake 最大限度地减少了重写的文件数量,这比重写所有数据要快。
下图说明了每个文件中的数据
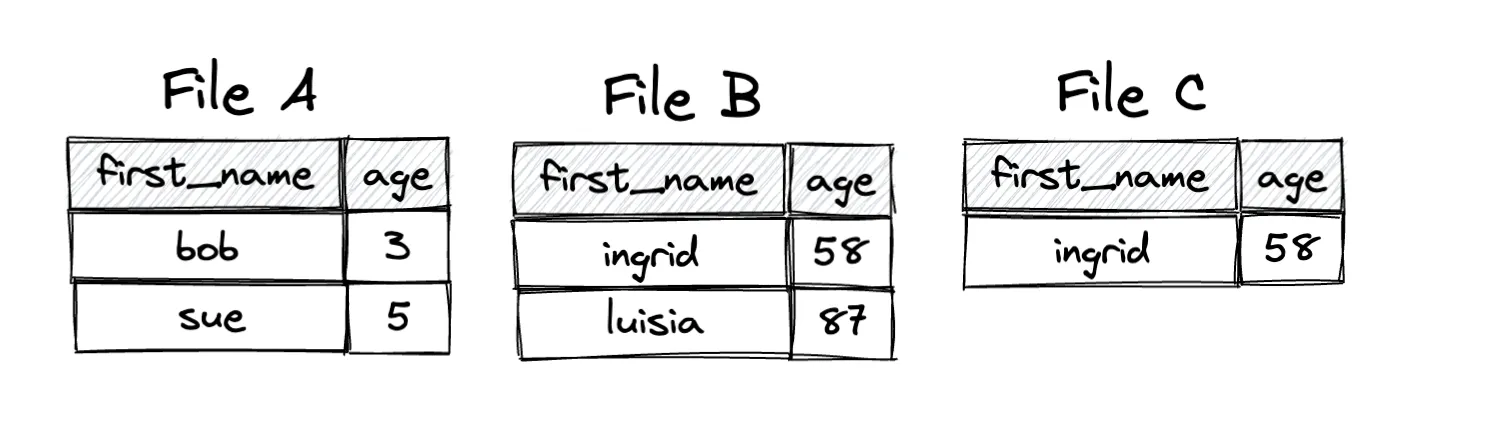
让我们看看 Parquet 文件格式的一些限制,以便更好地理解为什么必须以这种方式实现事务,而不是修改文件 B。
由于 Parquet 导致的 Delta Lake 删除限制
Delta Lake 由事务日志和存储在 Parquet 文件中的数据组成。
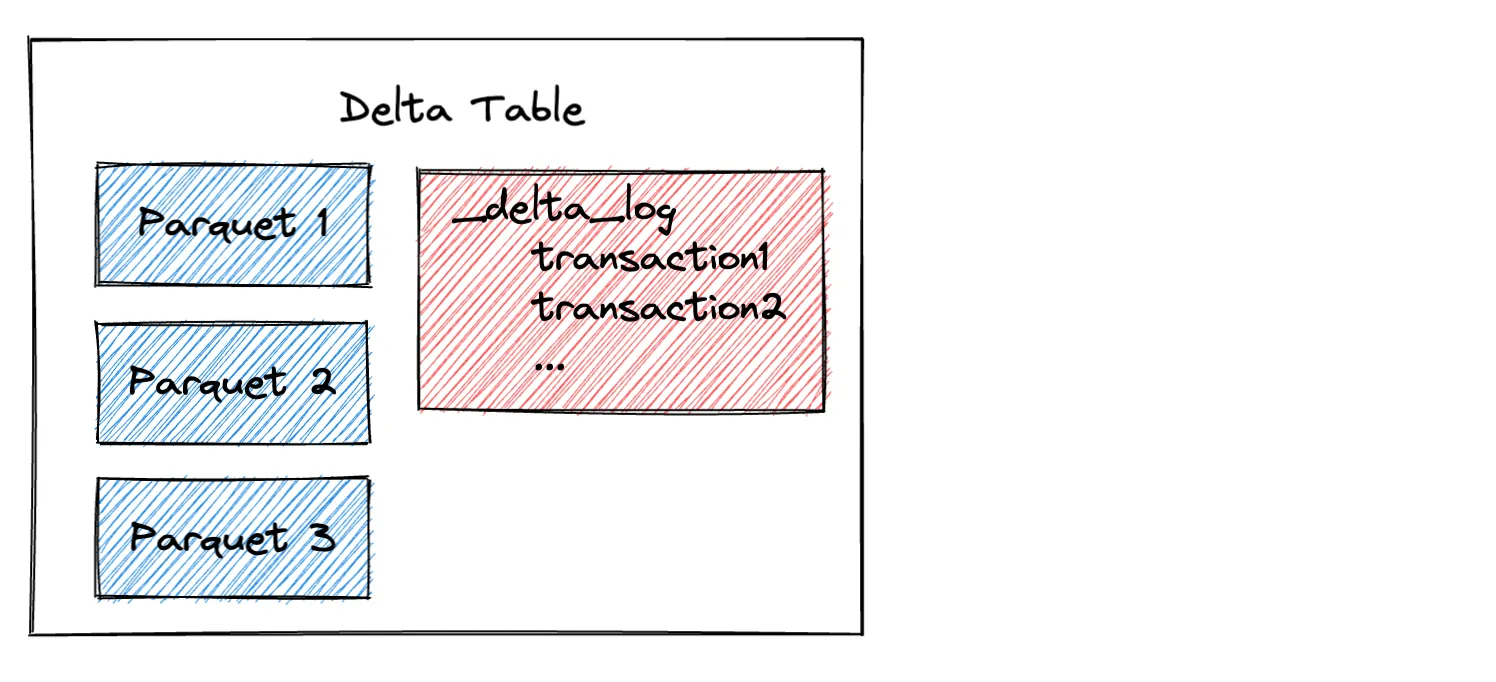
Parquet 文件是不可变的,这意味着它们不允许您添加或删除行。如果您想从 Parquet 文件中“删除”行,您需要将数据读入内存,过滤掉不需要的行,然后创建一个新的 Parquet 文件。
由于 Parquet 文件的不可变性,Delta Lake 在删除行时必须写入新文件。
Delta Lake 删除操作与数据湖
您已经了解了如何从 Delta Lake 中删除行 - 让我们回顾一下该命令
dt.delete(F.col("age") > 75)让我们想象尝试在 Parquet 数据湖上复制相同的操作。您可以将整个 Parquet 表读入内存,进行缓存(确保它完全适合内存且没有溢出到磁盘),运行过滤操作,然后覆盖现有数据,但这很危险。如果您的集群在执行写入时出错,您将丢失数据。
您还可以迭代所有 Parquet 文件,找出需要更新的文件,将它们读入内存,过滤它们,追加新的数据文件,然后手动删除所有旧文件。这种方法的缺点如下
- 在执行此操作时,您的数据湖无法使用。没有事务隔离,因此读取器在添加新数据文件后会看到重复数据。
- 这是一个危险的操作。如果您不小心删除了错误的文件怎么办?
- 工作量很大。
Delta Lake 使删除行等常见数据任务变得高效和简单。这是 Delta Lake 在与数据湖打交道时为您节省大量时间和精力的又一个例子。
Delta Lake 从存储中物理删除数据
当您使用 Delta Lake 运行删除操作时,已删除的行不会立即从存储中物理删除。让我们回顾一下文件系统操作
删除操作将文件 B 标记为删除(逻辑操作),但它不会从存储中物理删除文件 B。
有时您确实希望从存储中删除文件,可能是为了节省存储成本或出于法规原因。在这种情况下,您需要确保在运行删除命令后清理数据,以从存储中物理删除文件。
重要提示:启用删除向量时,从存储中删除文件首先需要运行 PURGE 命令,更多信息请参阅删除向量博客文章。
结论
Delta Lake 使您能够轻松地从 Delta 表中删除数据行。Delta Lake 删除操作的执行效率很高,因为它只重写文件的最小子集。当启用删除向量时,删除操作运行得更快。
Delta Lake 删除操作是 ACID 事务,即使在执行删除事务时也能使您的 Delta 表保持可用状态。
删除操作在数据湖上运行起来非常麻烦。您需要编写大量自定义代码,承受表停机时间,并承担出错和丢失数据的风险。Delta Lake 对于删除操作来说要好得多,因为它们可靠且不需要手动操作。
请参阅这篇关于Delta Lake 与 Parquet 的博客文章,以了解有关 Delta Lake 相对于数据湖的优势的更多信息。