为什么 PySpark 在 Delta Lake 中的追加(append)和覆盖(overwrite)写入操作比在 Parquet 表中更安全
本文解释了 append 和 overwrite 这两种 PySpark 保存模式(save mode)的写入操作,以及它们在 Delta 表中是如何物理实现的。你将看到这些操作在 Parquet 表中的不同实现方式,并了解为什么 Delta Lake 的实现更优越。你还将了解 PySpark 的 errorifexists 和 ignore 保存模式写入操作在 Delta Lake 中是如何实现的。
以下是不同保存模式的逻辑解释:
- 追加(Append):向现有表添加额外数据
- 覆盖(Overwrite):删除表中现有数据,并用新数据替换
- 错误(Error)(即
errorifexists):如果表存在且包含数据,则抛出错误 - 忽略(Ignore):如果表已存在则不写入,但也不抛出错误
Delta Lake 对这些不同保存模式的实现支持 ACID 事务并提供出色的开发体验。
Parquet 表的限制使得开发体验不那么愉快,尤其是在覆盖事务方面。让我们比较一下 Parquet 和 Delta Lake 中不同写入模式的实现方式。
如果你想在自己的机器上重现这些计算,本文中涵盖的所有代码片段都可以在这个笔记本中找到。
Parquet 追加保存模式
让我们首先演示如何创建 DataFrame 并使用 append 保存模式添加额外数据。
以下是如何创建一个包含一行数据的 DataFrame 并以 Parquet 文件格式将其写入磁盘。
columns = ["singer", "country"]
data1 = [("feid", "colombia")]
rdd1 = spark.sparkContext.parallelize(data1)
df1 = rdd1.toDF(columns)
df1.repartition(1).write.format("parquet").save("tmp/singers1")看看写入磁盘的 Parquet 文件。
tmp/singers1
├── _SUCCESS
└── part-00000-ffcc616b-4009-462a-a60d-9e2bd7130083-c000.snappy.parquet我们使用了 repartition(1),因此只写入一个文件,这使得本示例的意图清晰。通常,您会希望将数据集并行写入多个文件,因此 repartition(1) 仅适用于非常小的数据集。
在下面的操作图中,我们将其称为“文件 A”。
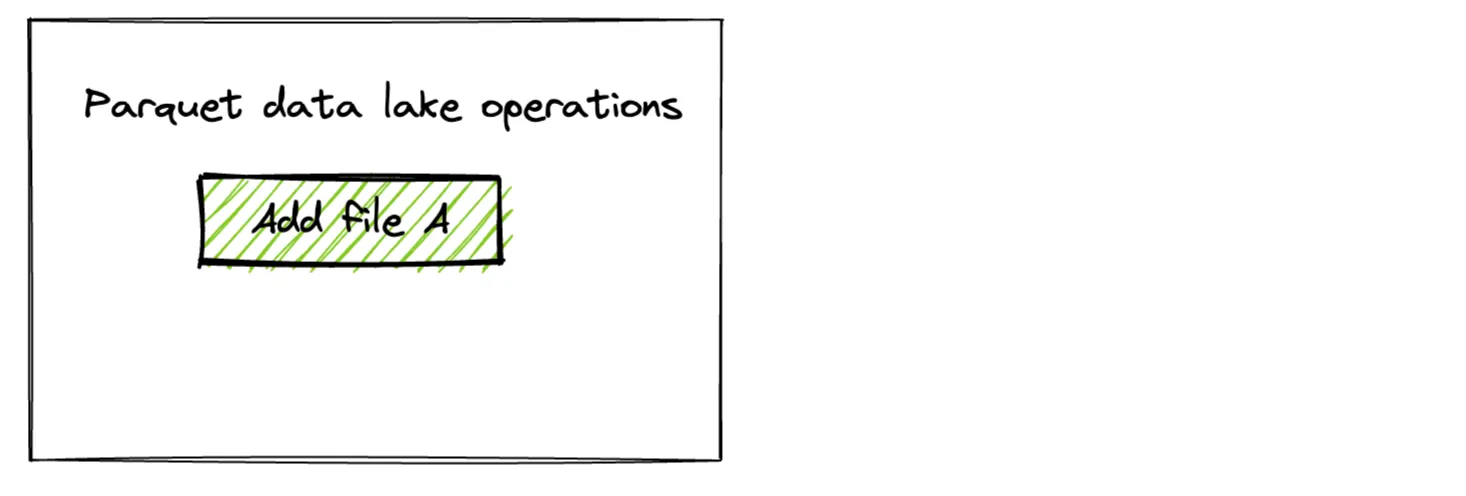
现在创建另一个 DataFrame 并将其追加到现有 Parquet 表中。
data2 = [("annita", "brasil")]
rdd2 = spark.sparkContext.parallelize(data2)
df2 = rdd2.toDF(columns)
df2.repartition(1).write.mode("append").format("parquet").save("tmp/singers1")以下是 Parquet 表的内容
spark.read.format("parquet").load("tmp/singers1").show()
+------+--------+
|singer| country|
+------+--------+
|annita| brasil|
| feid|colombia|
+------+--------+当保存模式设置为 append 时,新文件会添加到 Parquet 表中。
tmp/singers1
├── _SUCCESS
├── part-00000-49da366f-fd15-481b-a3a4-8b3bd26ef2c7-c000.snappy.parquet
└── part-00000-ffcc616b-4009-462a-a60d-9e2bd7130083-c000.snappy.parquet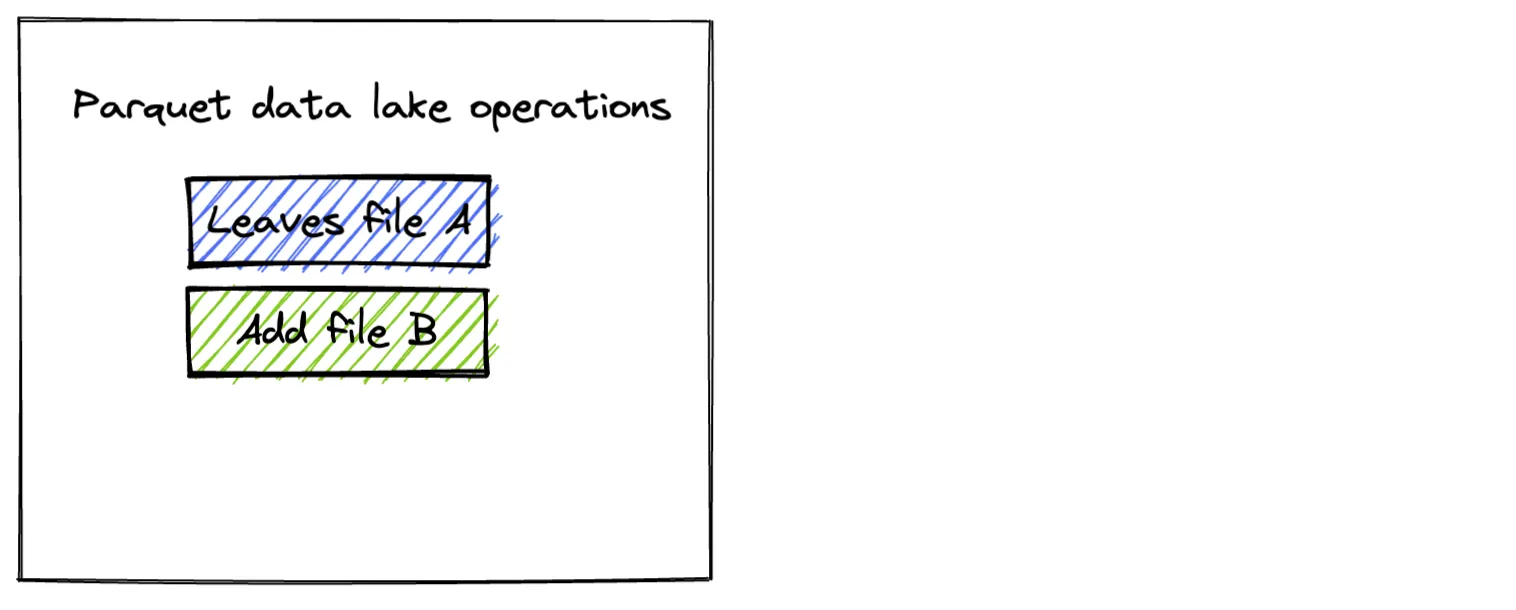
Parquet 覆盖保存模式
现在创建第三个 DataFrame,它将用于覆盖现有 Parquet 表。以下是创建 DataFrame 和覆盖现有数据的代码。
data3 = [("rihanna", "barbados")]
rdd3 = spark.sparkContext.parallelize(data3)
df3 = rdd3.toDF(columns)
df3.repartition(1).write.mode("overwrite").format("parquet").save("tmp/singers1")以下是覆盖操作后 Parquet 表的内容
+-------+--------+
| singer| country|
+-------+--------+
|rihanna|barbados|
+-------+--------+以下是存储中的新文件
tmp/singers1
├── _SUCCESS
└── part-00000-63531918-401d-4983-8848-7b99fff39713-c000.snappy.parquet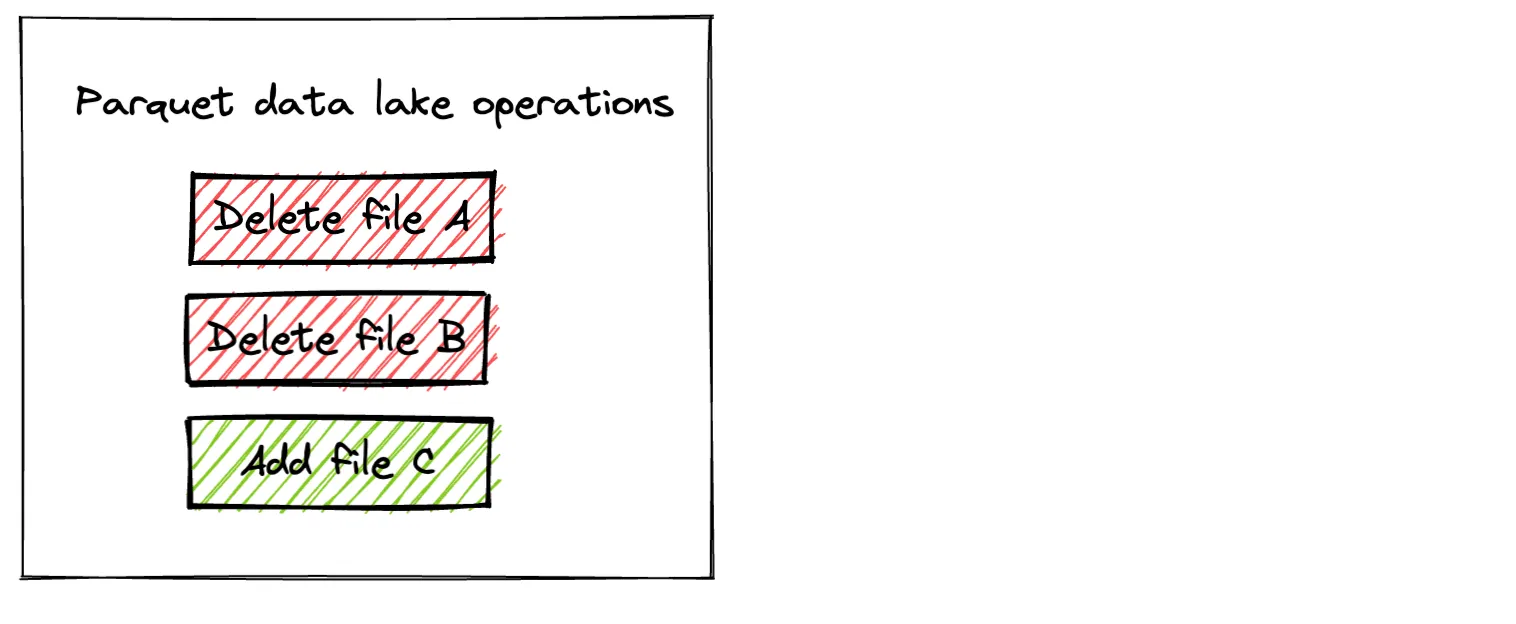
当保存模式设置为 overwrite 时,Parquet 将写入新文件并删除所有现有文件。这种实现有几个缺点:
- 旧数据被删除,因此如果您的存储格式不支持版本控制或未启用版本控制,则无法执行回滚并撤销错误。更改是永久性的。
- 在执行覆盖操作期间,Parquet 表对读取器处于不可用状态。例如,并发读取器可能会看到一个“计算中状态”:文件 A 被删除,但文件 B 仍然存在,这不是一个有效的表状态。
- 如果执行覆盖操作的计算集群在操作执行过程中崩溃,您的数据湖将处于“计算中状态”,并可能损坏。损坏类型取决于发生错误时覆盖操作已完成的程度。
让我们看看 Delta 表上的相同操作,看看它们如何更加健壮和用户友好。
Delta Lake 追加和覆盖保存模式
让我们对 Delta 表执行相同的操作,将保存模式设置为 append 和 overwrite,看看它们的实现有何不同。
使用前面相同的 df1 创建一个单独的 Delta 表。
df1.repartition(1).write.format("delta").save("tmp/singers2")以下是 Delta 表的内容。
+------+--------+
|singer| country|
+------+--------+
| feid|colombia|
+------+--------+以下是 Delta 表中的文件
tmp/singers2
├── _delta_log
│ └── 00000000000000000000.json
└── part-00000-946ae20f-fa5a-4e92-b1c9-49322594609a-c000.snappy.parquet现在将 df2 追加到 Delta 表中。
df2.repartition(1).write.mode("append").format("delta").save("tmp/singers2")以下是 Delta 表的内容
+------+--------+
|singer| country|
+------+--------+
|annita| brasil|
| feid|colombia|
+------+--------+以下是 Delta 表中的文件
tmp/singers2
├── _delta_log
│ ├── 00000000000000000000.json
│ └── 00000000000000000001.json
├── part-00000-946ae20f-fa5a-4e92-b1c9-49322594609a-c000.snappy.parquet
└── part-00000-adda870a-83a2-4f5c-82a0-c6ecc60d9d2e-c000.snappy.parquet现在使用 df3 覆盖 Delta 表。
df3.repartition(1).write.mode("overwrite").format("delta").save("tmp/singers2")以下是 Delta 表的内容
+-------+--------+
| singer| country|
+-------+--------+
|rihanna|barbados|
+-------+--------+以下是 Delta Lake 中的文件
tmp/singers2
├── _delta_log
│ ├── 00000000000000000000.json
│ ├── 00000000000000000001.json
│ └── 00000000000000000002.json
├── part-00000-2d176e2d-66e0-44b6-8922-6bc3a15a6b96-c000.snappy.parquet
├── part-00000-946ae20f-fa5a-4e92-b1c9-49322594609a-c000.snappy.parquet
└── part-00000-adda870a-83a2-4f5c-82a0-c6ecc60d9d2e-c000.snappy.parquet重要提示:请注意,Delta Lake 的覆盖操作不会删除任何底层 Parquet 文件。它只是在事务日志中创建一个条目以忽略现有文件(逻辑删除)。它实际上不会删除文件(物理删除)。请看下图,以了解与此 Delta Lake 上所采取的操作相对应的三个事务日志条目。
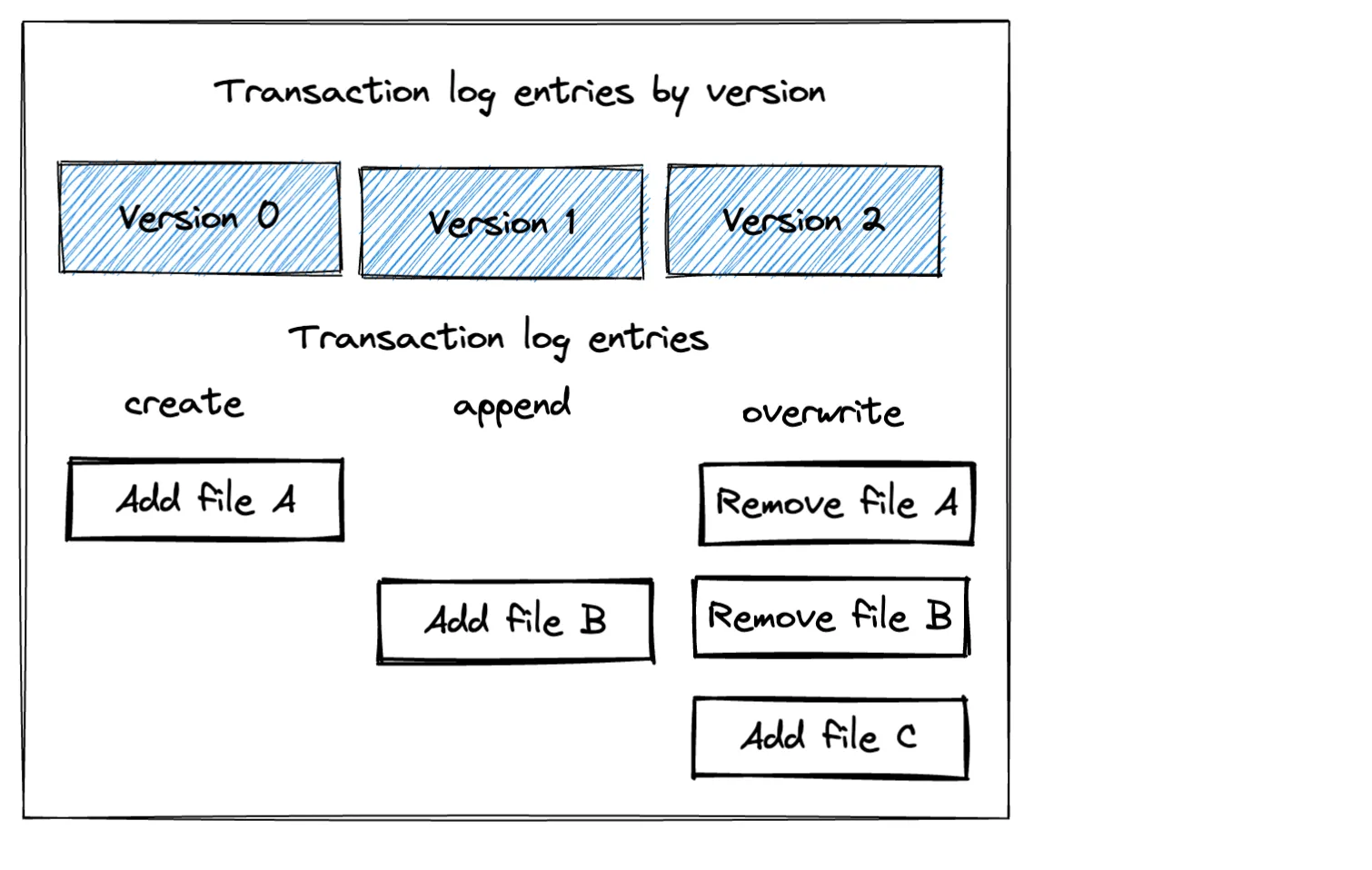
Delta Lake 覆盖数据的方法几乎总是更可取的!
为什么 Delta Lake 更安全
Delta Lake 覆盖操作不会从存储中物理删除文件,因此可以撤销。当您覆盖 Parquet 表时,旧文件会从存储中物理删除,因此如果您的存储不支持版本控制或未启用版本控制,则无法撤销该操作。即使您在存储上启用了版本控制,对 Parquet 表执行意外覆盖仍然是一个代价高昂的错误。
Delta Lake 的设计协议使版本化数据成为内置功能。时间旅行和使用 restore 命令恢复到以前的版本是 Delta Lake 轻松实现的功能,因为版本化数据是 Delta Lake 设计的核心方面。所有这些功能对数据从业者都非常有用。Parquet 表不提供这些功能,因此 Delta Lake 几乎总是更好。
为了完整性,让我们看看其他 PySpark 保存模式以及它们在 Delta Lake 中的实现方式。
Delta Lake 中的 PySpark 错误 / errorifexists 保存模式
默认的 PySpark 保存模式是 error,也称为 errorifexists。如果 Delta 表不存在,它将创建一个;如果 Delta 表已经存在,它将报错。
让我们使用 df1 创建另一个 Delta 表,并显式将保存模式设置为 error。
df1.repartition(1).write.mode("error").format("delta").save("tmp/singers3")这可行,因为 tmp/singers3 不存在。
现在让我们看看当我们将 df2 写入 tmp/singers3(现在存在的 Delta 表)时会发生什么。
该操作报错并显示以下消息
AnalysisException: Cannot write to already existent path file:/Users/…/tmp/singers3 without setting OVERWRITE = 'true'.我们已经确认,如果保存模式设置为 error,PySpark 在写入现有 Delta 表时会报错。
Delta Lake 中的 PySpark 忽略保存模式
如果 Delta 表尚不存在,PySpark 的 ignore 保存模式将创建该表。如果 Delta 表已存在,PySpark 的 ignore 保存模式将不执行任何操作(它既不会写入数据也不会报错)。
让我们将 df1 的内容写入一个新的 Delta 表,并将保存模式设置为 ignore。
df1.repartition(1).write.mode("ignore").format("delta").save("tmp/singers4")以下是 Delta 表的内容
spark.read.format("delta").load("tmp/singers4").show()
+------+--------+
|singer| country|
+------+--------+
| feid|colombia|
+------+--------+让我们将 df2 追加到这个 Delta 表中。回想一下 df2 包含以下数据
df2.show()
+------+-------+
|singer|country|
+------+-------+
|annita| brasil|
+------+-------+现在让我们将 df2 的内容写入一个新的 Delta 表,并将保存模式设置为 ignore。
df2.repartition(1).write.mode("ignore").format("delta").save("tmp/singers4")以下是保存模式设置为 ignore 写入后 Delta 表的内容。
+------+--------+
|singer| country|
+------+--------+
| feid|colombia|
+------+--------+当保存模式设置为 ignore 时,df2 中的数据不会被追加,也不会抛出错误。
这是保存模式设置为 ignore 的第二次写入操作所创建的事务日志条目。
{
"commitInfo":{
"timestamp":1664801261318,
"operation":"WRITE",
"operationParameters":{
"mode":"Ignore",
"partitionBy":"[]"
},
"readVersion":0,
"isolationLevel":"SnapshotIsolation",
"isBlindAppend":true,
"operationMetrics":{
},
"engineInfo":"Apache-Spark/3.3.0 Delta-Lake/2.1.0",
"txnId":"dcb6992b-24cb-4f3e-bcd3-203837c7986e"
}
}此事务日志条目不添加或删除文件。它是一个空操作(no-op)。
结论
PySpark 的保存操作在 Parquet 表和 Delta Lake 中的实现方式不同。特别是,Parquet 覆盖操作会从存储中物理删除文件,而 Delta Lake 覆盖操作只会在事务日志中标记文件为墓碑(tombstone)。
Delta Lake 支持版本化数据和时间旅行。它只在您运行 vacuum 命令以删除不需要的旧文件以节省存储成本时才从磁盘上物理删除文件。
PySpark 在 Parquet 表上的操作可能相当危险。假设您想将一个小的 DataFrame 追加到现有数据集,却意外地运行了 df.write.mode("overwrite").format("parquet").save("some/lake") 而不是 df.write.mode("append").format("parquet").save("some/lake")。这个相对较小的错误会导致您删除所有现有数据。您只有在数据已备份的情况下才能恢复数据,但这可能也是一个巨大的麻烦。
Delta Lake 提供了更好的用户体验,因为您可以通过恢复到 Delta Lake 的早期版本轻松撤销意外的覆盖命令。版本化数据让数据从业者的工作变得轻松许多。
了解 PySpark 写入操作在 Delta Lake 底层是如何实现的基本直觉是很有益的。从高层次理解 Delta Lake 的工作原理可以帮助您优化数据湖并构建更好的数据管道。