如何使用 pandas 和 Delta Lake 对数据进行版本控制
本文展示了如何使用 pandas 轻松地对数据集进行版本控制,以及由此带来的诸多优势。版本化的数据允许你进行时间旅行,撤销错误,并以安全的方式向现有数据集追加数据。它还允许你在不同时间点对同一数据集运行模型,以查看新数据如何影响模型准确性。
本文中的所有计算都在这个 Jupyter Notebook中,因此你可以在自己的机器上运行此代码并跟着操作。
安装 Delta Lake 和 pandas
你可以通过pip install deltalake安装 Delta Lake,并通过pip install pandas安装 pandas。
deltalake是delta-rs项目的 Python 接口。delta-rs 用 Rust 编写,但你可以通过 Python 绑定像使用任何其他 Python 库一样使用它。
Delta Lake 最初是为 Spark 构建的,但deltalake实现没有 Spark 依赖。delta-spark依赖于 Spark,deltalake不依赖。
使用 pandas 创建一个版本化的 Delta Lake
你可以轻松地将 pandas DataFrame 写入 Delta 表。
首先导入 pandas 并创建 pandas DataFrame。你可以在 Jupyter Notebook 或命令行中运行此命令
import pandas as pd
df = pd.DataFrame({"x": [1, 2, 3]})现在将 pandas DataFrame 写入 Delta 表。你需要创建将写入 Delta 表的目录。
import os
from deltalake.writer import write_deltalake
os.makedirs("tmp/some_delta_lake", exist_ok=True)
write_deltalake("tmp/some_delta_lake", df)Delta Lake 将数据存储在 Parquet 文件中,并维护一个记录对表执行的数据操作的事务日志。事务日志允许进行版本化数据和时间旅行。
将 Delta 表读入另一个 pandas DataFrame,以确保它易于访问
from deltalake import DeltaTable
dt = DeltaTable("tmp/some_delta_lake")
dt.to_pandas()
x
0 1
1 2
2 3现在让我们使用 pandas 向 Delta 表添加更多数据。
使用 pandas 追加到版本化数据集
创建另一个 pandas DataFrame 并将其追加到 Delta 表。
df2 = pd.DataFrame({"x": [9, 8, 10]})
write_deltalake("tmp/some_delta_lake", df2, mode="append")读取 Delta 表内容,以确保数据已正确追加
DeltaTable("tmp/some_delta_lake").to_pandas()
x
0 1
1 2
2 3
3 9
4 8
5 10我们的 Delta 表现在有两个版本。版本 0 包含初始数据,版本 1 包含追加的数据。
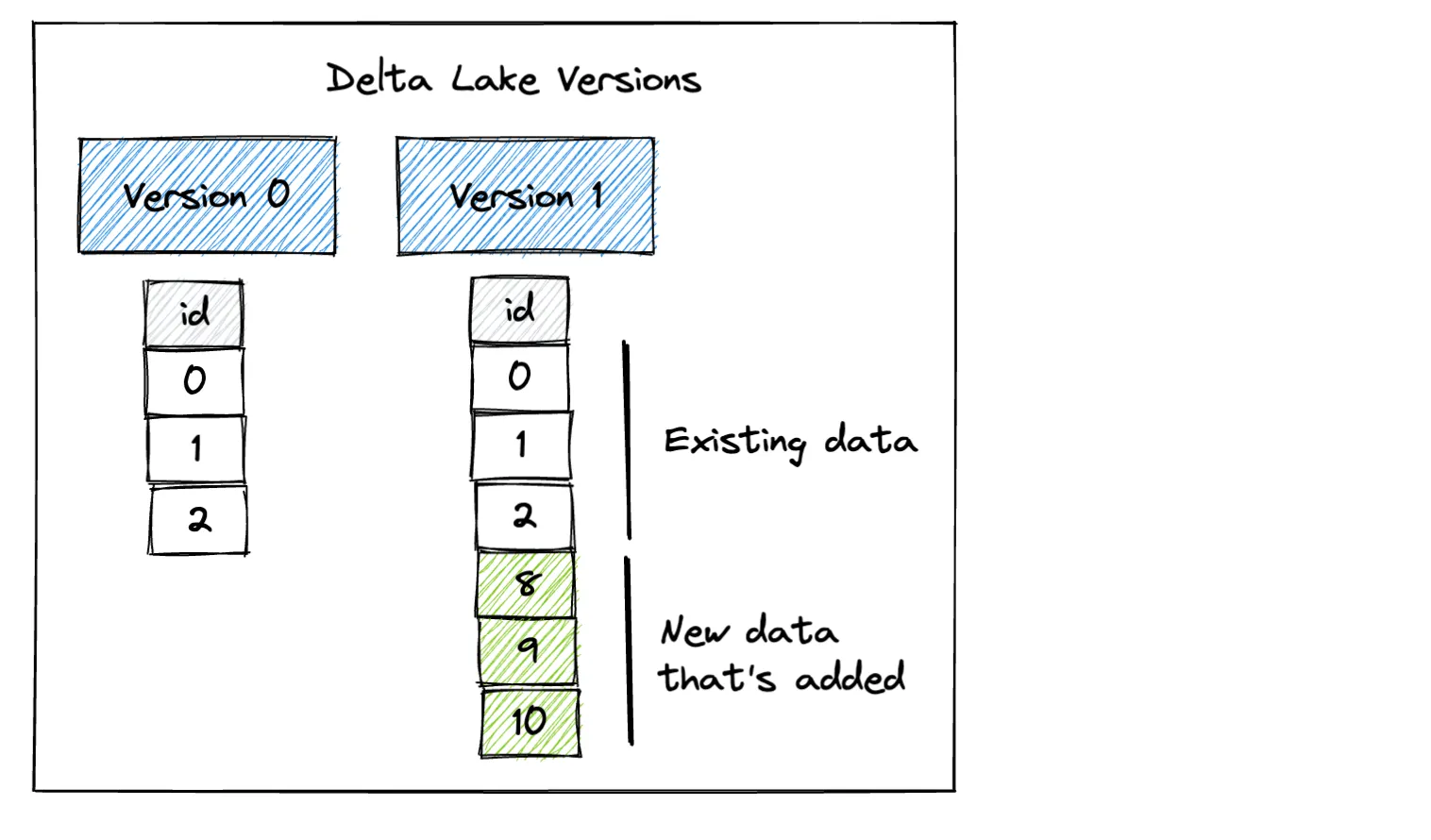
当你将数据追加到 CSV 或 Parquet 数据湖时,你总是只能读取数据集的最新版本。Delta Lake 提供了令人惊叹的灵活性,能够读取数据的先前版本。让我们看看如何读取数据集的版本 0。
使用 pandas 对版本化数据进行时间旅行
以下是如何使用 pandas 时间旅行到数据集的版本 0
dt = DeltaTable("tmp/some_delta_lake", version=0)
dt.to_pandas()
x
0 1
1 2
2 3如果你不指定版本,那么默认情况下你将读取 Delta 表的最新版本
DeltaTable("tmp/some_delta_lake").to_pandas()
x
0 1
1 2
2 3
3 9
4 8
5 10让我们执行另一个事务,用一个新的 DataFrame 覆盖 Delta 表的内容。
df3 = pd.DataFrame({"x": [55, 66, 77]})
write_deltalake("tmp/some_delta_lake", df3, mode="overwrite")以下是覆盖操作后 Delta 表的不同版本
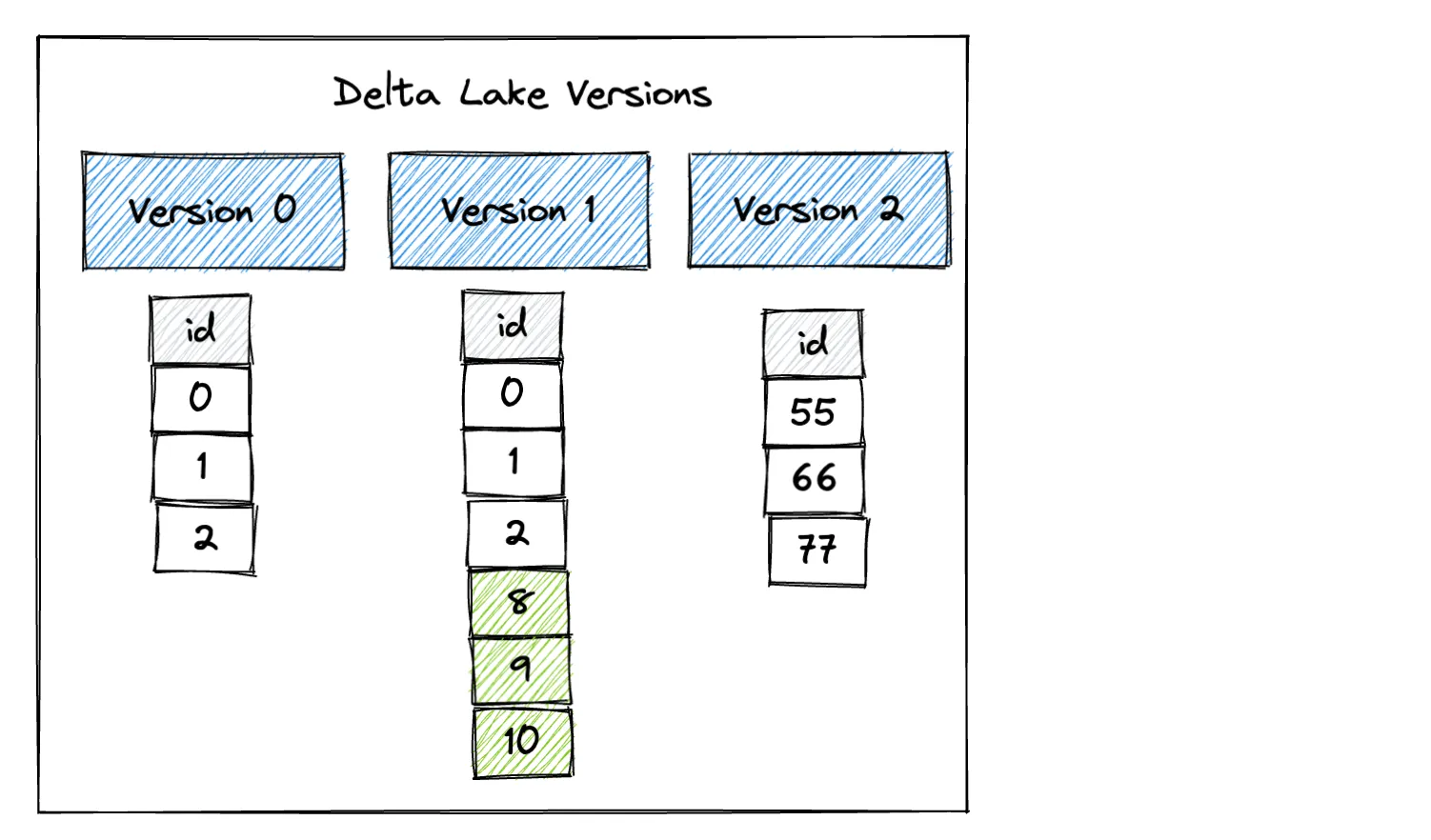
读入 Delta 表的最新版本以确认它已更新
DeltaTable("tmp/some_delta_lake").to_pandas()
x
0 55
1 66
2 77现在读入数据集的版本 0 以确认它仍然可访问
DeltaTable("tmp/some_delta_lake", version=0).to_pandas()
x
0 1
1 2
2 3还读入数据集的版本 1 以确认它仍然可访问
DeltaTable("tmp/some_delta_lake", version=1).to_pandas()
x
0 1
1 2
2 3
3 9
4 8
5 10即使在覆盖操作之后,数据集的所有版本仍然可访问。如果你使用的是 CSV 或 Parquet 数据湖,则无法访问数据的旧版本。
模式强制防止不良追加
Delta Lake 的另一个优点是,它会阻止你将具有不匹配现有数据模式的数据追加到 Delta 表。另一方面,Parquet、CSV 和 JSON 数据湖很容易损坏,因为它们允许你追加任何模式的数据。
我们一直使用的 Delta 表有一个单一的x列。让我们创建另一个只有y列的 DataFrame,看看当我们尝试将其追加到现有 Delta 表时会发生什么。
df4 = pd.DataFrame({"y": [111, 222]})
write_deltalake("tmp/some_delta_lake", df4, mode="append")你会得到以下错误
ValueError: Schema of data does not match table schema
Table schema:
y: int64
-- schema metadata --
pandas: '{"index_columns": [{"kind": "range", "name": null, "start": 0, "' + 357
Data Schema:
x: int64Delta Lake 在这里帮了你一个大忙。它阻止你损坏数据湖。
可互操作的版本化数据集
Delta Lakes 可与各种其他技术互操作。你可以使用 Apache Flink、Apache Hive、Apache Kafka、PrestoDB、Apache Spark、Trino 以及 Rust、Python、Scala、Java 等编程语言读/写 Delta 表。
以下是 Delta Lake 和 pandas 在生产 ETL 管道中的一些用例
- 你可以使用 pandas 和 deltalake 构建一个数据摄取平台,该平台每小时增量更新一个数据集。此数据集可能太大,无法由 pandas 查询,因此你可能需要使用 Trino 查询数据。
- 或者你可以做相反的事情。也许你有一个可以使用 Spark 进行聚合和清理的大型数据集。如果 Spark 聚合将数据充分缩小,你可以让下游用户使用 deltalake 和 pandas 查询它。此工作流非常适合更熟悉 pandas 的数据科学家。
Delta Lake 是使用多种技术构建 ETL 管道的好方法。
结论
本文向你展示了如何使用 pandas 和 Delta Lake 创建版本化数据集。它演示了如何使用 pandas 轻松地在数据的不同版本之间进行时间旅行。
你还看到了 Delta Lake 如何提供模式强制,从而阻止你将具有不兼容模式的数据写入 Delta 表。这可以防止你损坏数据集。
未来的博客文章将讨论 Delta Lake 为 pandas 程序员提供的更多优势。与 CSV、Parquet 和 JSON 等文件格式相比,Delta Lake 提供了许多优势,通常是免费的。许多 pandas 用户可以切换到 Delta Lake,并立即开始享受一些显著的数据质量和性能优势。