如何使用 Restore 将 Delta Lake 表回滚到以前的版本
当您使用普通的“香草”数据湖时,回滚错误可能极具挑战性,甚至不可能——特别是如果文件被删除。Delta Lake 为最终用户提供了撤销错误的能力,这是一个巨大的优势。与普通的 Parquet 表不同,Delta Lake 会保留您随时间所做更改的历史记录,存储不同版本的数据。使用 restore 命令将 Delta Lake 表回滚到以前的版本是撤销错误数据插入或撤销以意外方式修改表的优秀方法。
本文将向您展示如何回滚 Delta Lake 表,并解释在表已执行 vacuum 操作时无法回滚的情况。我们还将在此过程中了解 Delta Lake 的时间旅行功能。让我们从语法开始,然后深入到一个完整的示例来演示其功能。
TL;DR Delta Lake restore API
您可以使用 PySpark 中的 restoreToVersion 命令将 Delta Lake 表回滚到任何以前的版本
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/tmp/delta-table")
deltaTable.restoreToVersion(1)您还可以使用 SQL 回滚 Delta Lake 表
RESTORE TABLE your_table TO VERSION AS OF 1此外,您可以使用 restoreToTimestamp 将 Delta Lake 表恢复到不同的时间点。
Delta Lake 恢复用例
拥有版本控制的数据湖对于时间旅行来说非常棒,但对于撤销错误来说也同样宝贵。Delta Lake 的恢复功能提供了极大的灵活性。您可以使用它轻松回滚不必要的操作,同时保留完整的更改历史记录。
也许您的数据摄取过程出现故障,您加载了两次相同的数据——您可以使用一个命令撤销此操作。您可能还会决定将 Delta Lake 表回滚到以前的版本,因为您执行了一个具有意外后果的命令。或者,数据供应商错误地向您发送了一些信息,他们希望您从数据湖中删除它——您可以回滚到以前的版本,然后对表执行 vacuum 操作以永久删除数据,正如您将在本文后面看到的那样。简而言之,Delta Lake 的恢复功能是 Delta Lake 如何让您的开发人员生活更轻松的另一个例子。
示例设置:创建具有多个版本的 Delta Lake 表
为了演示恢复功能,让我们创建一个具有三个不同版本的 Delta Lake 表。我们将首先创建一个包含几行数据的简单表。这将存储为版本 0
df = spark.range(0, 3)
df.show()
+---+
| id|
+---+
| 0|
| 1|
| 2|
+---+
df.write.format("delta").save("/tmp/delta-table")现在我们将用一些其他数据覆盖该表。这将存储为版本 1
df2 = spark.range(4, 6)
df2.show()
+---+
| id|
+---+
| 4|
| 5|
+---+
df2.write.mode("overwrite").format("delta").save("/tmp/delta-table")最后,我们将再次用一些新数据覆盖以前的数据,从而创建版本 2
df3 = spark.range(7, 10)
df3.show()
+---+
| id|
+---+
| 7|
| 8|
| 9|
+---+
df3.write.mode("overwrite").format("delta").save("/tmp/delta-table")此图片显示了 Delta Lake 表的三个不同版本
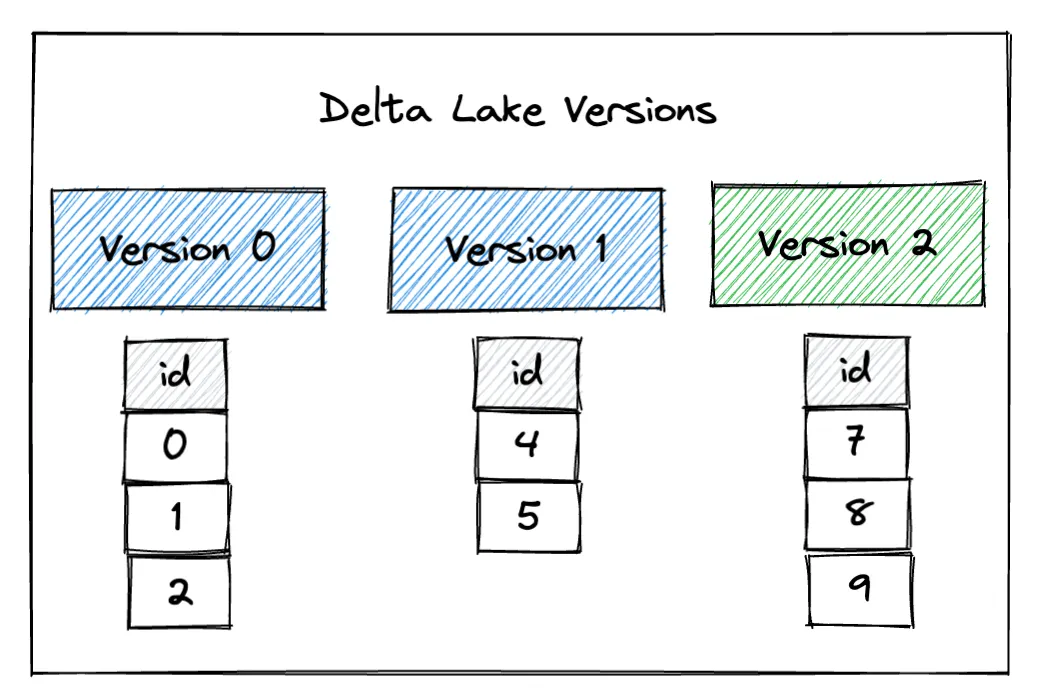
您可以看到,默认情况下,读取时 Delta Lake 包含最新版本的数据
spark.read.format("delta").load("/tmp/delta-table").show()
+---+
| id|
+---+
| 7|
| 8|
| 9|
+---+Delta Lake 中的时间旅行
Delta Lake 可以轻松访问您数据的不同版本。例如,您可以时间旅行回 Delta Lake 表的第 0 个版本,以查看创建时存储的原始数据。在时间旅行期间,我们将表加载到某个版本——在本例中,我们正在加载到初始版本。
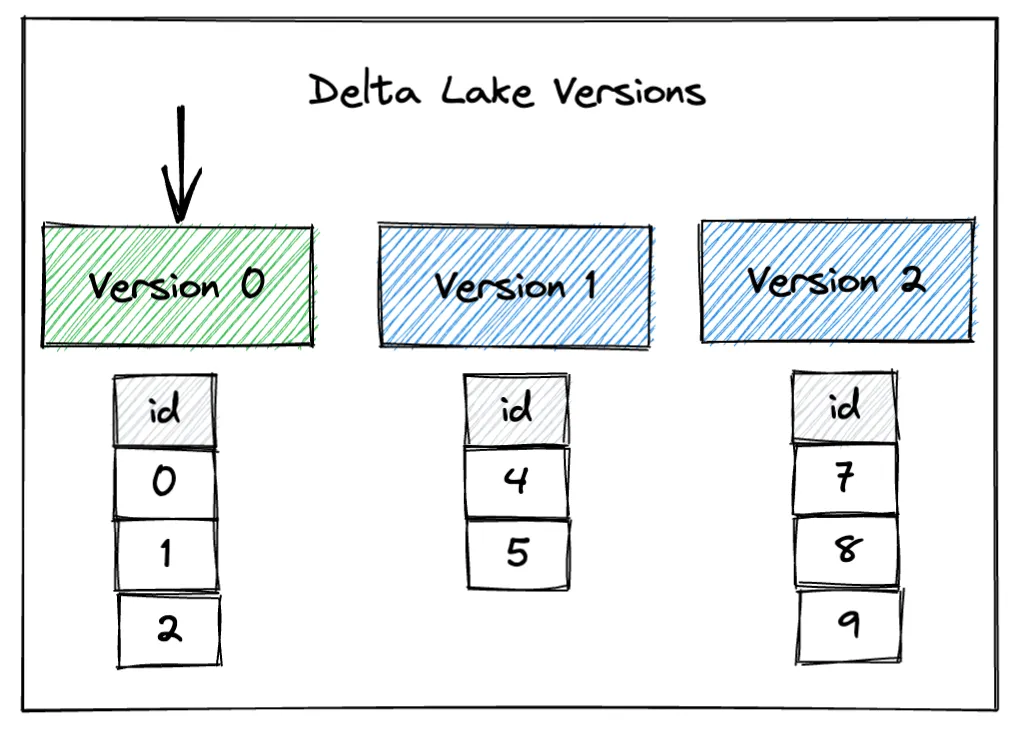
以下是如何时间旅行回我们的示例 Delta Lake 表的第 0 个版本
spark.read.format("delta").option("versionAsOf", "0").load("/tmp/delta-table").show()
+---+
| id|
+---+
| 0|
| 1|
| 2|
+---+以下是如何时间旅行回版本 1
spark.read.format("delta").option("versionAsOf", "1").load("/tmp/delta-table").show()
+---+
| id|
+---+
| 4|
| 5|
+---+时间旅行是一个临时读取操作,不过如果您愿意,可以将时间旅行操作的结果写入新的 Delta 表。如果您在执行上述命令之一后再次读取表的内容,您将看到最新版本的数据(在我们的例子中是版本 2);只有当您明确进行时间旅行时,才会返回更早的版本。
restore 命令允许一种更永久的时间旅行形式:您可以使用它将 Delta Lake 表恢复到以前的版本。
Delta Lake restore 幕后原理
让我们将示例 Delta Lake 表恢复到版本 1
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/tmp/delta-table")
deltaTable.restoreToVersion(1)现在当您读取表时,您可以看到它包含版本 1 的数据
spark.read.format("delta").load("/tmp/delta-table").show()
+---+
| id|
+---+
| 4|
| 5|
+---+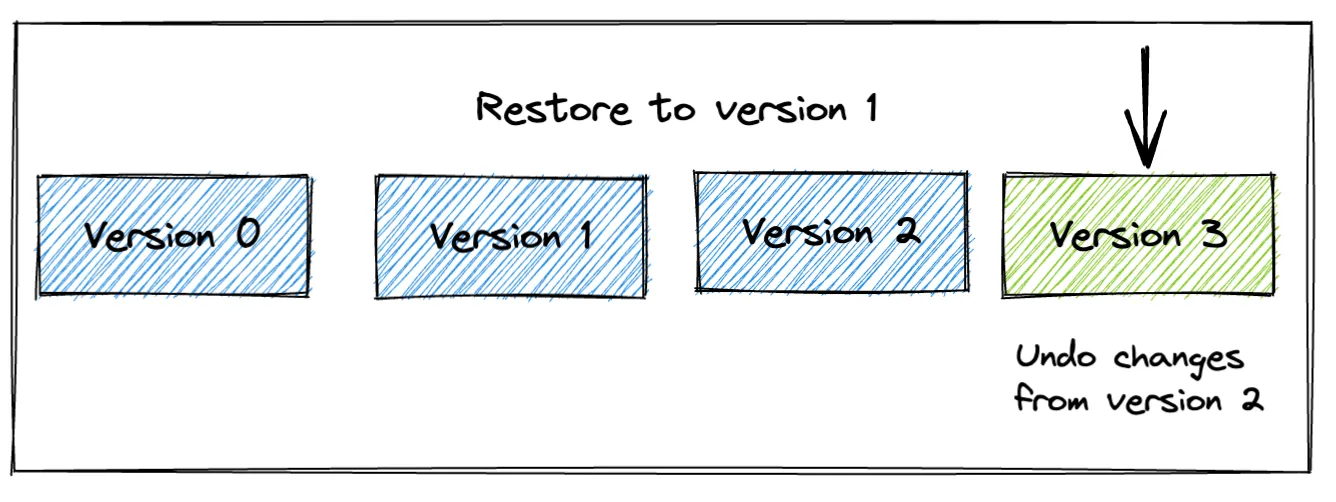
但是请注意,此更改不会擦除版本 2;相反,执行的是一个纯元数据操作,其中版本 2 中的更改被撤销。这意味着即使在运行 restoreToVersion 命令之后,您仍然可以时间旅行到 Delta Lake 表的版本 0、1 或 2。让我们时间旅行到 Delta Lake 表的版本 2 以演示数据已保留
spark.read.format("delta").option("versionAsOf", "2").load("/tmp/delta-table").show()
+---+
| id|
+---+
| 7|
| 8|
| 9|
+---+使用 restore 命令会将表的内容重置到早期版本,但不会删除任何数据。它只是更新事务日志以指示不应读取某些文件。下图提供了每个事务的事务日志条目的可视化表示。
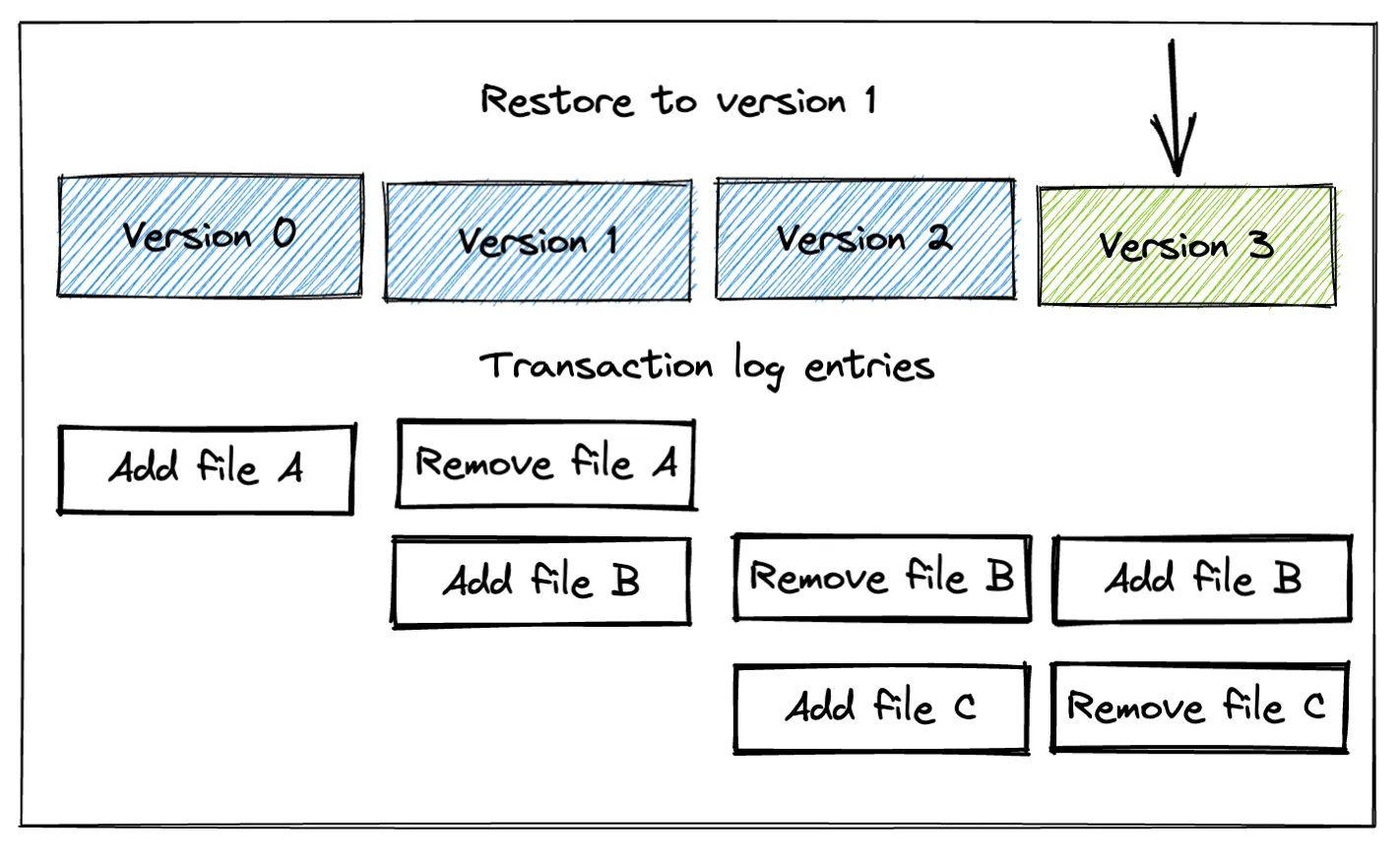
事务日志中的“添加文件”和“删除文件”并非指磁盘上的物理文件系统操作;它们是 Delta Lake 用于确定应读取哪些文件的逻辑元数据条目。
要在恢复到以前的版本后完全删除数据的更高版本,您需要运行 Delta Lake 的 vacuum 命令。我们接下来将介绍该命令及其效果。
Vacuum 后 Delta Lake 的恢复
vacuum 是一个广泛使用的命令,它删除表中最新版本不需要的文件。运行 vacuum 不会使您的 Delta Lake 操作更快,但它会删除磁盘上的文件,从而降低存储成本。
现在我们已将 Delta Lake 表恢复到版本 1,让我们运行 vacuum 命令看看会发生什么
deltaTable.vacuum(retentionHours=0)正如预期的那样,读取内容仍然返回表版本 1 的数据
spark.read.format("delta").load("/tmp/delta-table").show()
+---+
| id|
+---+
| 4|
| 5|
+---+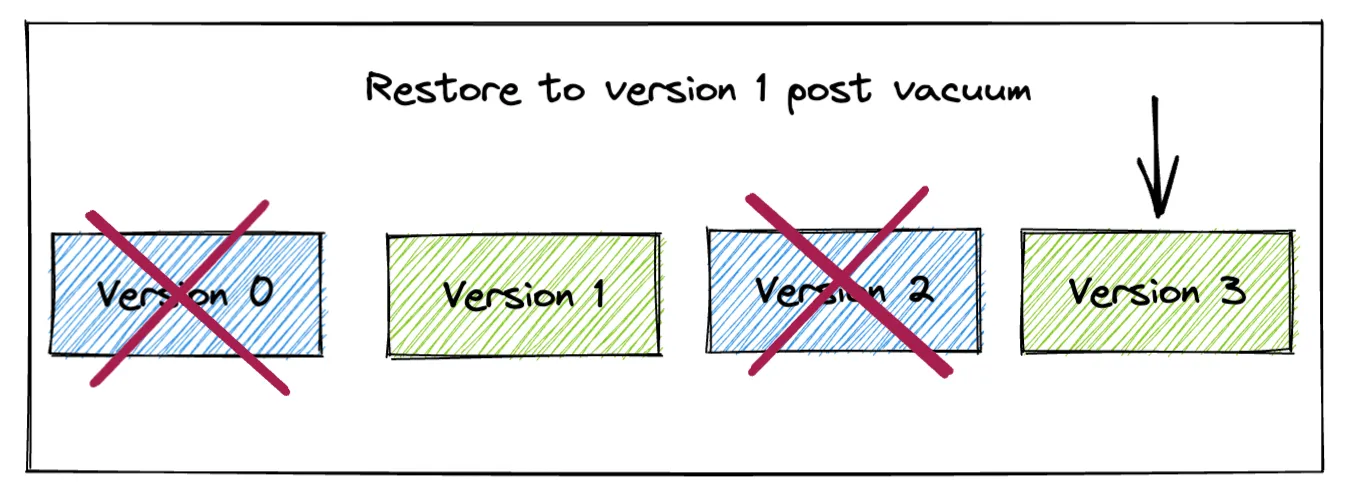
但现在我们已经执行了 vacuum 操作,我们无法再时间旅行到版本 2。vacuum 命令已删除了版本 2 的数据,因此我们无法再访问此版本。正如图表所示,我们也无法再访问版本 0。
假设我们尝试运行此代码以恢复到版本 2
spark.read.format("delta").option("versionAsOf", "2").load("tmp/delta-table").show()这是我们将收到的错误
22/09/30 14:51:20 ERROR Executor: Exception in task 0.0 in stage 180.0 (TID 12139)
java.io.FileNotFoundException:
File file:/Users/matthew.powers/Documents/code/my_apps/delta-examples/notebooks/pyspark/tmp/delta-table/part-00009-bdb964bc-8345-4d57-91e0-6190a6d1132e-c000.snappy.parquet does not exist
It is possible the underlying files have been updated. You can explicitly invalidate
the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by
recreating the Dataset/DataFrame involved.结论
本文向您展示了如何查看和恢复 Delta Lake 表的早期版本,并让您了解了一些代码的内部工作原理。与普通的 Parquet 数据湖相比,回滚更改并将数据恢复到以前版本的能力是 Delta Lake 的巨大优势。访问版本化数据让您的生活更轻松,并避免代价高昂的错误。
您可以在 LinkedIn 上关注 Delta Lake 项目,或加入 我们的 Slack 社区。我们有一个庞大、友好且不断壮大的社区,我们鼓励您加入。我们欢迎新成员,并乐意帮助您解决问题。