为什么T-Mobile数据科学和分析团队迁移到基于Delta Lake的数据湖仓?
我们面临的问题
T-Mobile建设全国最佳5G网络的使命极大地增加了每月计划的网络项目数量,并直接影响了企业的采购和供应链组织。T-Mobile需要高效的后台业务流程来支持这些激进的目标,因此对数据的需求急剧增加。
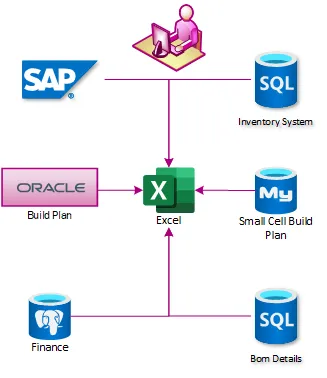
与许多企业一样,T-Mobile的数据分散在未集成的不同系统之间。整合网络计划状态、物料采购、供应链运营和现场服务极其复杂。在2018年初,企业依赖Excel和PowerPoint每周生成报告。这些报告建立在专用的SQL服务器上,每个服务器都从不同的系统获取数据。然后将报告拉取到企业数据仓库中进行合并,但这个过程通常需要12小时或更长时间才能完成。
我们渴望一个集中化的位置来构建报告,于是我们开始了云计算之旅。
V1 - 数据湖 (TMUS)
这种集中化工作的第一次迭代,一个名为TMUS的MPP(大规模并行处理)数据库,走了很多捷径。当时没有预料到会有多少用户希望访问这个系统,也没有预料到它最终会成为一个集成点——目标只是为了摆脱使用电子表格的分析师,并在同一个地方构建所有报告。创建了一个MPP实例,并使用基于云的数据集成工具进行填充。文件暂存在数据湖存储(DLS)中,并且有一个想法是数据湖最终会取代TMUS,但最初它只是一个华丽的概念验证。然而,TMUS很快就证明了它的价值,因为报告的生成速度快得多。这个系统现在平均可以比其他业务部门提前9小时生成报告。在这一点上,它只是生成操作报告。当然,这些是耗时的操作报告,但这只是系统的唯一角色。
报告扩展
在某个时候,决定让一些业务部门直接访问TMUS,以便尽早获取这些操作报告。访问权限没有严格控制,因此他们可以开始编写自己的查询,以直接适用于他们的方式改进或完善报告。这是这些数据首次被如此集中化,业务用户从能够从中生成自己的报告中获得了巨大的价值。这些报告很快被这些业务部门视为关键任务。他们还识别出与现有数据集互补的新数据源。将这些数据源导入企业数据仓库需要过长的时间,因此他们要求将这些数据源加载到TMUS中,在那里他们可以编写自己的转换。
第一次迭代中发现的问题
TMUS经历了快速的有机增长,并被认为是巨大的成功。任何成功的项目,你都一定会发现缺陷。让我告诉你,我们确实发现了。
没有系统集成计划
处理所有这些数据的唯一方法是将其加载到这个集中存储中。这导致人们纷纷要求更多访问权限,从而导致资源争用问题。也没有直接的系统集成控制。用户在没有明确的SLA或使用规定下获得访问权限。一些团队编写的查询运行了数小时。其他团队设置了自己的ETL流程来提取大量数据。这是一片混乱。
工作负载争用
操作和分析工作负载具有非常不同的配置文件。随着分析工作负载和用户生成的报告的增长并消耗更多资源,操作报告刷新变得不可靠。一个运行数小时的分析报告会消耗更新每小时刷新一次的操作报告所需的资源。
需要护栏
不幸的是,这些用户编写的报告没有得到严格控制。用户生成的报告和查询开始相互影响,并影响系统最初旨在支持的核心操作报告的性能。当这些性能影响变得无法忍受时,系统已经为从库存分配系统到高管仪表板的所有内容提供支持。
创新和以业务速度运行的愿望超越了对治理和结构的渴望。结果,TMUS成为了自身成功的受害者。
第一次迭代中哪些方面做得好
从最初的实施中可以讲述许多成功故事。简化的报告流程使我们能够跟上T-Mobile激进的建设步伐,但这只是众多故事之一。
从收割到核心
通常,业务用户会想出查询来解决不同系统之间数据如何关联的问题。然后,TMUS可以收集和整理这些查询,将该逻辑传播到整个业务。在许多情况下,TMUS是企业中唯一可以集成这些系统数据的地方。
安全
早期,我们根据源系统或工作负载垂直将数据分隔到不同的模式中。这使我们能够应用一个相对容易管理和审计的安全模型。
数据可访问性
TMUS成为了分析师处理不自然交叉的数据的地方,为识别工作流程中的缺陷和创建业务流程效率打开了大门。
V2 - 数据湖仓
TMUS最受瞩目的用例之一是每周两次为完成网络建设项目分配物料。分配信息决定了T-Mobile仓库中数十亿美元的库存如何调配。这在操作上至关重要,但由于工作负载争用,大约40%的时间会失败。于是决定将驱动该流程的逻辑从TMUS中提取出来,并将其放入Apache Spark™ Notebook中。这个流程从失败40%的时间变为完美运行。这成为了我们第二代架构的基础。
数据湖仓概述
数据湖仓仅仅是将数据仓库的原则应用于数据湖中的数据。数据通过Delta Lake表暴露,Delta Lake是一种开源协议,用于以ACID兼容的方式与湖中的数据交互。这带来了几个直接适用于我们问题的优势:
通过计算/存储分离解决工作负载争用
Delta表不会发生阻塞,并且可以在计算过程之间共享而不会产生争用。分离存储和计算的另一个好处是,用户使用的计算资源是隔离给该用户的,并且可以将其费用计入该用户的组织。
通过直接数据湖或Spark访问解决数据隔离
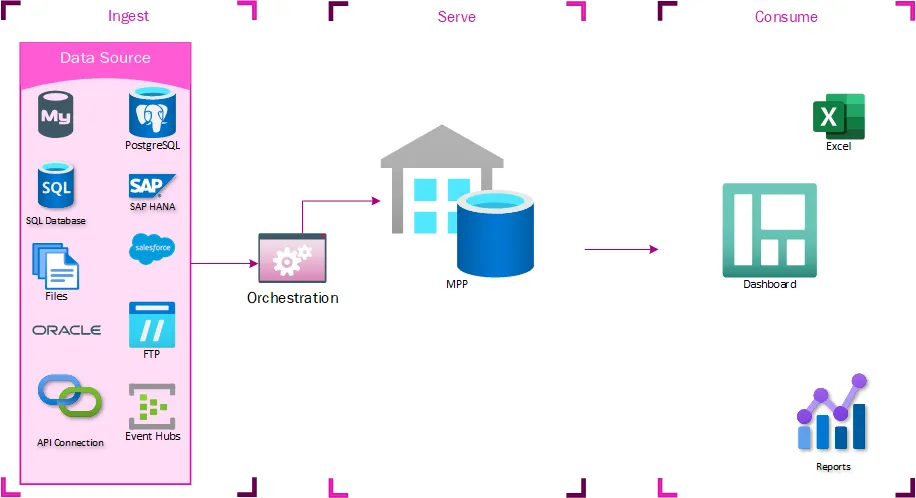
数据不再需要加载到集中式系统——如果用户有权访问数据湖中的数据,他们可以使用计算端点连接到该数据并进行分析。这简化或消除了那些唯一目的是移动数据而不进行转换的ETL的需求。
通过无服务器架构提供清晰的SLA和集成点
通过数据湖暴露数据可以实现清晰的集成点——如果你想给我们发送数据,只需将其放入数据湖。如果你想获取数据,只需使用任何能够从数据湖读取数据的客户端。无服务器SQL和Spark端点提供类似的体验。这还提供了清晰的SLA。无服务器SQL并不总是比查询SQL服务器快,但相同的查询将始终花费相同的时间,并且不会受到其他用户的影响。
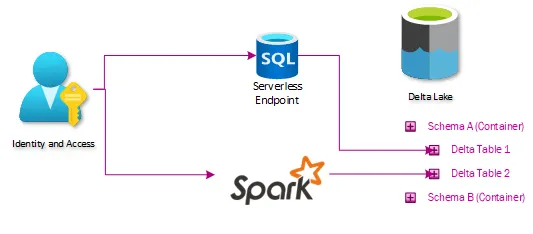
架构
我们的湖仓架构如下
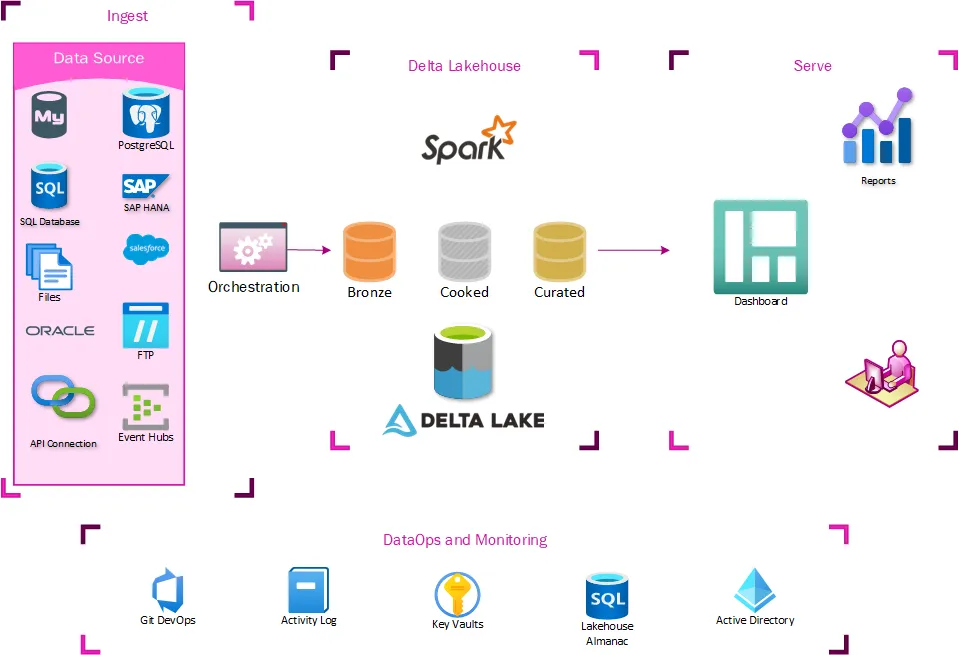
摄取
在摄取层面,不需要进行太多改变。提取过程已经将数据暂存在数据湖中,因此我们很容易开始基于这些位置构建表。我们摄取过程的主要新增功能是修改提取数据的日志记录方式。我们创建了一个新的审计数据库来控制我们湖仓的数据仓库方面,因此所有的编排管道都需要记录到该位置。
Delta Lakehouse
这是所需更改的核心——一系列Delta表,它们在湖仓中暴露的数据与用户通过TMUS获得的数据相同。这是通过一系列标记为Bronze、Silver和Curated(Gold)的表来摄取数据完成的。Bronze表基本上像缓慢变化维度Type 2一样工作,如果发生任何更改,则会创建新行。Silver表仅存储数据的最新状态,镜像源系统中的表。Curated表是进行任何高级ETL和数据塑形以进行仓库存储的地方。
Bronze和Silver表由一系列通用笔记本维护,并且完全是元数据驱动的。在这一点上,大多数数据提取也是通用且元数据驱动的。这使得新数据集的上线变得微不足道。Curated数据集由通用编排引擎编排的自定义笔记本维护。
展示
如果湖仓架构不能以一种易于迁移现有报告、仪表板和提取生态系统的方式暴露数据,那么它所有的好处都将毫无用处。任何以前连接到TMUS的消费者现在都可以连接到无服务器SQL端点,并访问数据的湖仓版本,而无需进行任何进一步的转换。这意味着现有的SSRS、PowerBI、Excel或自定义ETL只需切换连接字符串即可工作。
过渡到湖仓
最初的设计包括将数据以Parquet文件的形式暂存在数据湖中,然后将其加载到我们的TMUS MPP中。由于数据已经存在于数据湖中,我们很容易编写一个标准化工作簿将数据加载到我们的Bronze和Silver表中。很快,需要集成的基础系统数据就可以在我们的无服务器和MPP端点中使用了。然而,许多驱动报告的逻辑已经作为视图或存储过程嵌入到我们的MPP系统中。所有这些嵌入式逻辑都需要经过优先级划分过程,然后进行迁移,在那里可以将视图和存储过程逻辑转换为Spark笔记本。这意味着,至少在可预见的未来,一些ETL逻辑仍将锁定在我们的MPP仓库中。一些用户仍需要连接到该MPP实例才能获取他们的精选数据。然而,随着越来越多的团队认识到湖仓架构的优势,他们已经开始将自己的报告逻辑转换为Spark笔记本。
正在发挥作用的方面
你如何在旨在鼓励探索未定义解决方案的系统中建立护栏?
安全模型
初始迭代中的安全性围绕SQL Server模式展开。模式作为业务领域和权限要求的交叉点,然后创建Active Directory组并与每个模式关联。这对于每个人来说都容易理解,也易于管理和审计。这意味着扩展我们的安全模型只需将数据放入我们存储账户中命名相似的容器中。授予相同的Active Directory组对这些容器的访问权限,使无服务器SQL、Spark、SQL和数据湖之间的权限保持一致。
环境
创建了开发和测试环境,以避免在生产环境中进行开发。我们还锁定了生产环境,禁止生产开发,从而大大提高了可靠性。
DevOps 和 CI/CD
为了减轻运营团队的负担并提高测试自动化,我们实施了CI/CD和DevOps实践。在平台的每个环境和部分中自动化发布管道有助于实现可靠的部署节奏。发布管道还提供了运行构建和集成测试的能力。这在平台的每个部分都可用。集成测试现在结合了平台的多个部分,减少了中断。
SQL部署框架
一个自主开发的框架,用于执行可重复运行的SQL查询/DDL,以部署我们SQL数据库中的更改。它使用AAD进行身份验证,因此不会破坏我们的安全模型。过去使用DACPAC的个人经验影响了我们决定使用自主解决方案而不是开箱即用实现。
编排引擎
我们相信我们在编排引擎上实施CI/CD应被视为最佳实践。所有拉取请求都部署到开发环境,以便工程师可以可靠地测试和验证更改,从而消除生产事故。此外,所有合并到主分支的更改都部署到测试环境,以验证合并成功且可重复。然后,它以与部署到测试相同的代码库推送到生产。
Spark
Spark有一个名为Repos的功能,可以将git仓库克隆到工作区。此功能可以轻松与DevOps管道集成,并允许我们将CI/CD实践扩展到所有Spark工作区。
拉取请求用于签入
这是一个相当标准的同行评审流程。没有自我评审,并且审查者需要遵循一些检查清单。任何签入或批准破坏构建的签入的工程师都会带来甜甜圈。
我们发现并克服的障碍
与任何新产品一样,我们发现了一些需要解决的功能。
报告演进
无服务器SQL端点被宣传为报告的预测性性能解决方案。虽然不一定是最快的,但它是一致的,因为在等待计算资源时没有争用或排队。这需要对我们的业务合作伙伴进行教育宣传,以了解如何高效地使用这项技术。
结论
从BI到ML再到AI,数据是未来的货币。这种架构允许相对简单的基础设施,将以业务的速度暴露数据。它允许无阻塞地读取和写入数据,并线性扩展。业务合作伙伴可以轻松采用高级分析并获得新的见解。这些新见解促进了不同工作流的创新,并巩固了T-Mobile采取的去中心化分析方法。