Apache Flink Delta Lake 表源连接器
我们很高兴地宣布发布 Delta Connectors 0.5.0,它引入了新的 Flink/Delta Source 连接器,该连接器可在 Apache Flink™ 1.13 上运行,并可使用 Flink 的 DataStream API 直接从 Delta 表读取数据。Flink/Delta Source 和 Sink 连接器现在都作为单个 JVM 库提供,该库提供了使用 Delta Standalone JVM 库从 Apache Flink 应用程序读取和写入 Delta 表数据的能力。Flink/Delta Source 连接器支持将 Delta 表中的数据读取到 Flink 中进行批处理和流处理。
原生 Flink Delta Lake 源连接器
Flink/Delta Source 连接器基于 Flink 新的 统一源接口 API 构建,该 API 在版本 1.12 中引入,用于构建源连接器。我们的连接器使用了原始文件源的低级元素,以及用于读取 Delta 表的特定逻辑,例如读取 Delta 表日志。
工作模式
Flink/Delta Source 连接器可以以两种模式之一工作:有界(即批处理)或连续(即流处理)。
-
有界
此模式主要用于批处理作业,并提供读取 Delta 表最新版本的完整数据加载或加载特定快照版本的能力。
-
连续
此模式用于流处理作业,除了读取特定快照版本的 Delta 表内容外,它还持续检查 Delta 表是否有新的更新和版本。它还可以只读取更改。
Flink 定期拍摄所有状态的持久快照,并将其存储在分布式文件系统等持久存储中。如果发生故障,Flink 可以恢复应用程序的完整状态并从上次成功的检查点恢复处理。
模式发现
Flink Delta Source 连接器扫描 Delta 表日志以发现列和列类型。它支持使用 Delta Source 构建器方法读取所有列或指定的列集合。在这两种情况下,连接器都会发现表列的 Delta 数据类型,并将其转换为相应的 Flink 数据类型。连接器将使用 Delta 表日志自动检测分区列,无需任何额外配置。
架构
Delta Source 连接器已实现 Flink 统一源接口架构的核心组件。连接器为 Source 和 SplitEnumerator 等接口提供 Delta 特定的实现。此外,它还重用 Flink 文件系统支持和 Flink 文件源的低级组件,例如文件读取器和拆分分配器。
统一源接口
每个 Flink 数据源都有三个核心组件,它们以统一的方式支持从批处理和流处理源读取数据。
-
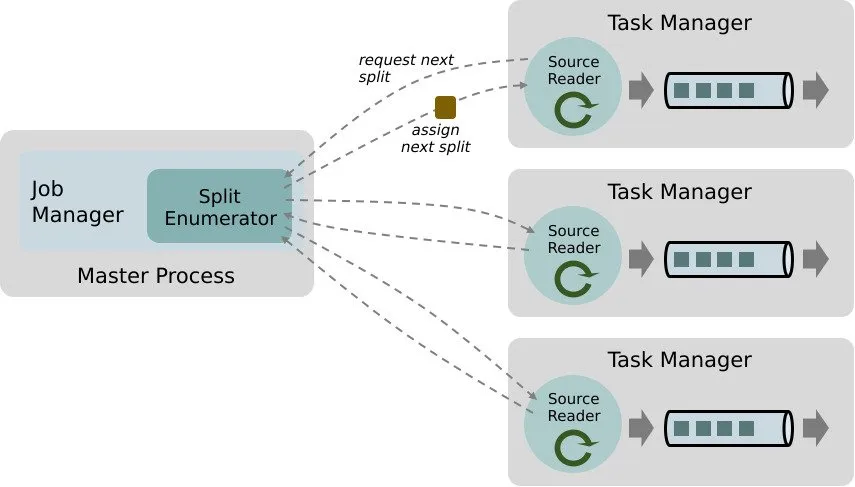
拆分
这是源连接器消耗、分配工作并并行从源读取数据的最小工作单元。拆分可以是整个文件、文件块、Kafka 分区或其他。
-
SourceReader
SourceReader 请求拆分并通过从数据源读取拆分来处理它们。一个示例是 SourceReader 发送读取文件或日志分区的请求。SourceReader 在 Task Manager 上并行运行,因此产生并行事件/记录流。
-
SplitEnumerator
SplitEnumerator 创建拆分,并在 SourceReader 请求拆分时将其分配给 SourceReader。它作为 Job Manager 进程上的单个实例运行,并维护给定数据源已分配和待处理拆分的列表。它负责在并行运行的各种 SourceReader 之间平衡拆分。
Flink 的 Source 类是一个 API 入口点,它将所有上述三个组件组合在一起。有关更多详细信息,请参阅 Flink 的文档。
源初始化
由 DeltaSource 类实现的 Source 接口是 Flink 运行时的入口点。Flink 的 SourceCoordinator 使用该 API 来初始化 Source 实例。初始化涉及创建 SplitEnumerator,在灾难恢复的情况下,从先前检查点的状态重新创建它。之后,文件读取器也在源初始化阶段创建。
Delta Source 实例使用 SplitEnumeratorProvider 根据使用的源选项构建具体的枚举器实现。SplitEnumeratorProvider 创建一个我们称之为 TableProcessor 的实例,它充当 Flink 和 Delta 表日志之间的桥梁。TableProcessor 实现为 Delta 表快照和表更改提供了一个入口点,这些快照和更改稍后可以转换为拆分,并由 DeltaSourceSplitEnumerator 分配给文件读取器
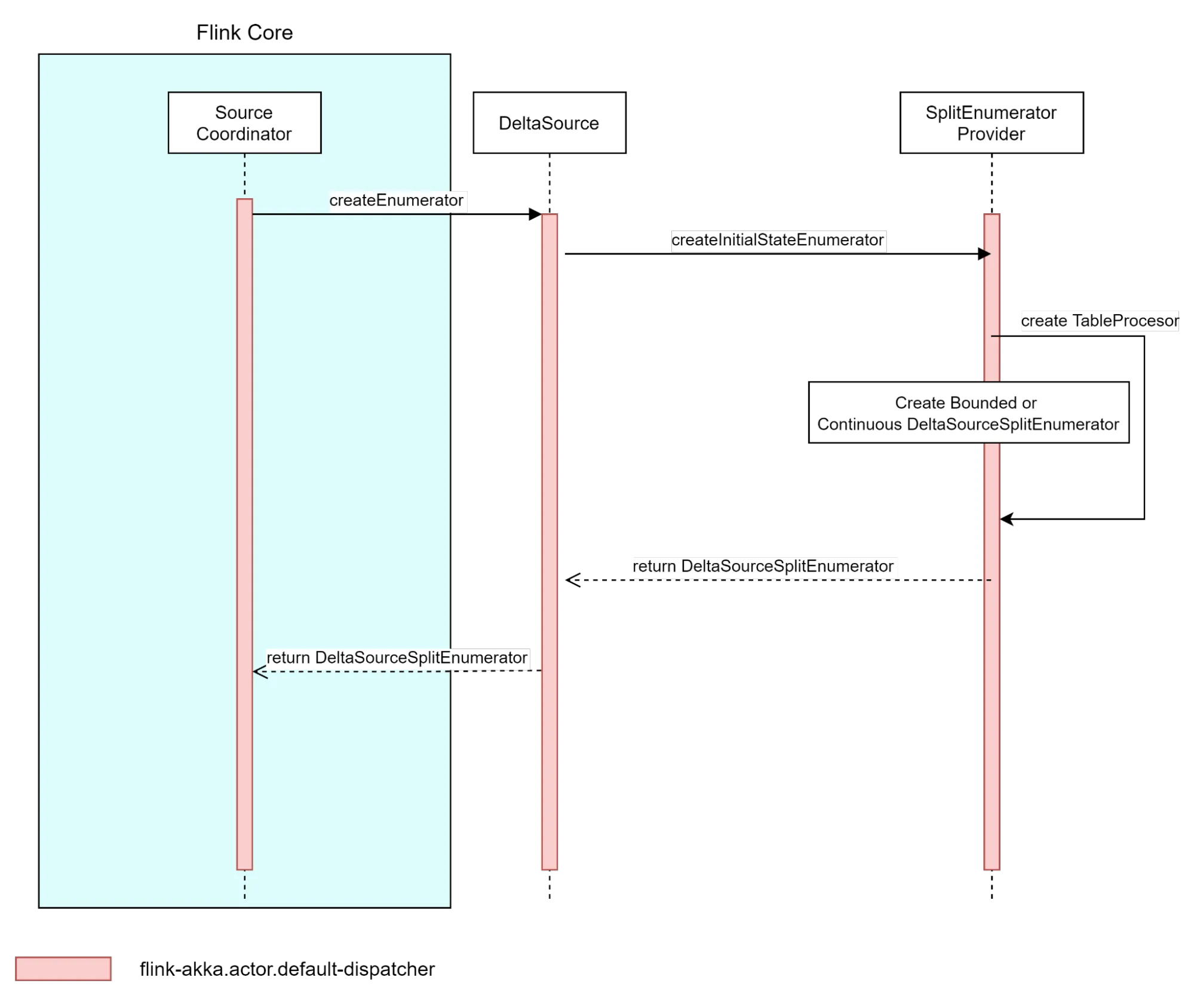
通过创建 DeltaSourceSplitEnumerator,Flink 可以通过 TableProcessor 处理数据,准备拆分并在将拆分分配给读取器之前获取任何 Delta 表更改。
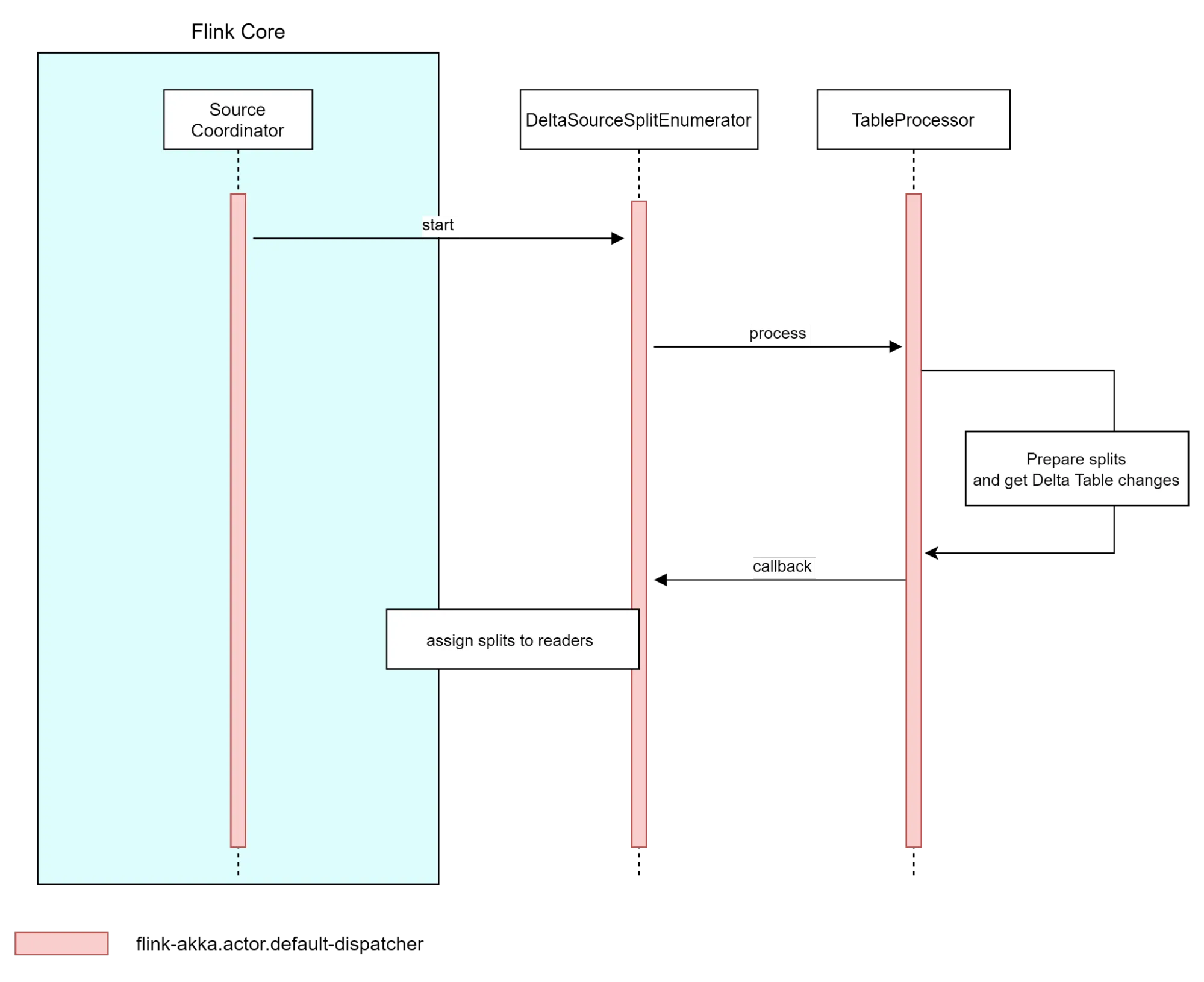
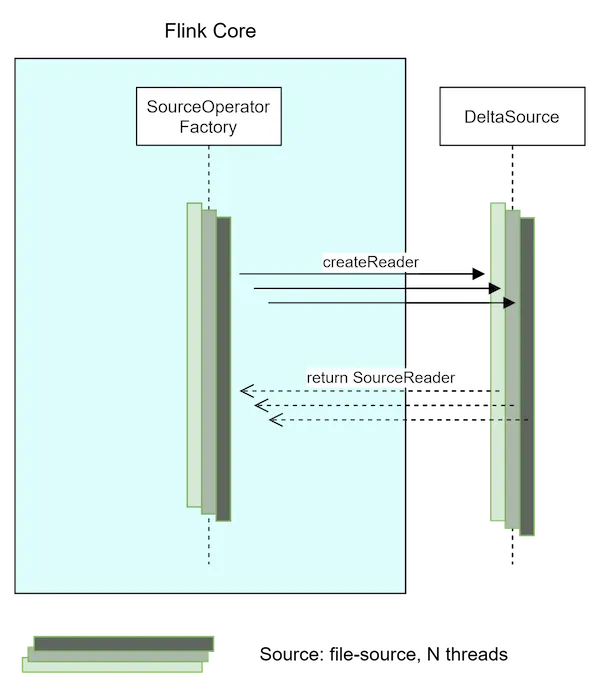
SourceReader 创建
每个 SourceReader 都由一个单独的线程创建,Flink 创建的源读取器数量由源或整个作业的并行度级别决定。
源启动
新创建的 SourceReader(每个在其自己的线程上)通过 Flink Core 向 SplitEnumerator 发送拆分请求,以表明它们已准备好处理新数据。SplitEnumerator 通过调用 sourceReaderContext::assignSplit 方法将新拆分分配给读取器来响应这些请求。然后,Flink Core 通过调用 SourceReader::addSplits(List<Split>) 方法将该拆分分配给 SourceReader。
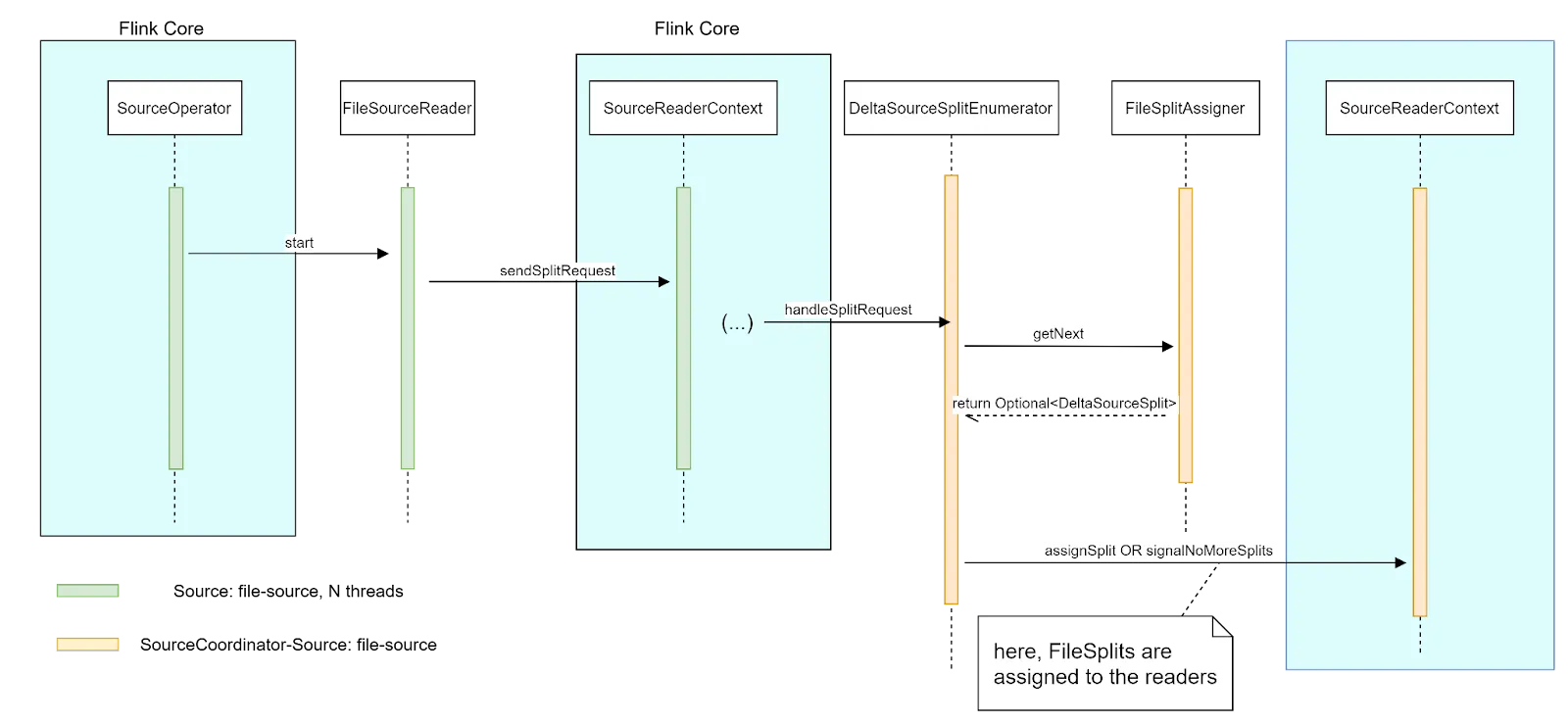
可以在Delta 连接器设计文档中找到更详细的信息。
实现 - 从 Delta Lake 表读取数据到 Flink
Flink/Delta Lake 连接器是一个 JVM 库,用于利用 Delta Standalone JVM 库从 Apache Flink 应用程序读取和写入 Delta Lake 表,并包括 Source 和 Sink 连接器。本节重点介绍 Source 连接器,并提供将数据直接从 Delta Lake 读取到 Flink 中进行批处理(有界)和流处理(连续)模式的示例。有关更多信息,请参阅#110。
Flink/Delta Source 设计用于 Flink 1.13.0 <= Flink <= 1.14.5,并提供精确一次交付保证。此连接器依赖于以下软件包
delta-standaloneflink-parquetflink-table-commonhadoop-client
批处理(或有界)模式
- 从 Delta 表的最新版本读取所有列
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
public DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}- 使用时间旅行从 Delta 表的特定历史版本读取所有列
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
public DataStream<RowData> createBoundedDeltaSourceWithTimeTravel(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
// could also use `.versionAsOf(314159)`
.timestampAsOf("2022-06-28 04:55:00")
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}- 从 Delta 表的最新版本读取用户定义的列
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
public DataStream<RowData> createBoundedDeltaSourceUserColumns(
StreamExecutionEnvironment env,
String deltaTablePath,
String[] columnNames) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.columnNames(columnNames)
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}流处理(或连续)模式
- 从历史版本开始读取 Delta 表的所有列。使用 Delta 的时间旅行,它加载历史版本及之后的所有更改,而不是完整的表状态。
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
org.apache.flink.streaming.api.functions.sink.filesystem.DeltaBulkPartWriter
public DataStream<RowData> createContinuousDeltaSourceWithTimeTravel(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forContinuousRowData(
new Path(deltaTablePath),
new Configuration())
// could also use `.startingVersion(314159)`
.startingTimestamp("2022-06-28 04:55:00")
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}- 从 Delta 表的最新版本读取所有列,并持续监控表更新
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
public DataStream<RowData> createContinuousDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forContinuousRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}- 只从 Delta 表的最新版本读取用户定义的列,并持续监控表更新。
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
public DataStream<RowData> createContinuousDeltaSourceUserColumns(
StreamExecutionEnvironment env,
String deltaTablePath,
String[] columnNames) {
DeltaSource<RowData> deltaSource = DeltaSource
.forContinuousRowData(
new Path(deltaTablePath),
new Configuration())
.columnNames(columnNames)
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}有关如何构建和测试的更多信息在此处。
下一步是什么?
正如从 Apache Flink 写入 Delta Lake中所述,我们合作创建了最初的 Flink/Delta sink,现在又创建了 Flink/Delta source。但它们目前只支持 Flink DataStream API。对 Flink Table API/SQL 的支持,以及用于将 Delta 表元数据存储在外部元数据存储中的 Flink Catalog 的实现,正如扩展 Apache Flink 的 Table API 的 Delta 连接器(#238)中所述,已在计划中。
您如何提供帮助?
我们总是很高兴与现有和新的社区成员合作。如果您有兴趣帮助 Delta Lake 项目,请立即通过许多论坛加入我们的社区,包括 GitHub、Slack、Twitter、LinkedIn、YouTube 和 Google Groups。
