Delta 2.0 – 数据湖屋的基础已开放
我们很高兴地宣布,Delta Lake 2.0(pypi、maven、发行说明)已在 Apache Spark™ 3.2 上发布,包含但不限于以下功能:
- 支持变更数据流(change data feed),
- 对数据进行Z-Order 聚类以减少读取数据量,
- 支持对 Delta 表的幂等写入,
- 支持删除列,
- 支持动态分区覆盖,以及
- 对多部分检查点的实验性支持。
Delta Lake 2.0 的意义不仅仅是一个数字——尽管它与 Delta Lake 的三周年生日恰好重合。它重申了我们对 Delta Lake 开源的集体承诺,正如 2022 年数据 + AI 峰会上 Michael Armbrust 的第一天主题演讲所宣布的。
 2022 年数据 + AI 峰会上 Michael Armbrust 的第一天主题演讲
2022 年数据 + AI 峰会上 Michael Armbrust 的第一天主题演讲
Delta Lake 2.0 有哪些新功能?
在过去一年中,Delta Lake 1.0、1.2 和现在的 2.0 之间发布了许多新功能。本博客将回顾其中一些将对您的工作负载产生重大影响的特定功能。
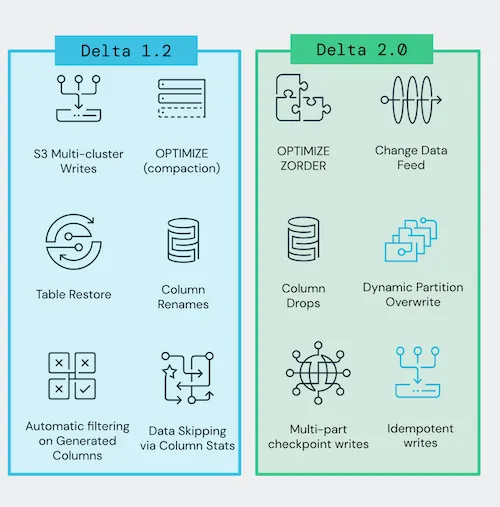
改进数据跳过
在探索或切分数据时,数据从业者通常会运行带有特定过滤条件的查询。结果,匹配的数据通常埋藏在一个大型表中,需要 Delta Lake 读取大量数据。通过列统计和 Z-Order 进行数据跳过,数据可以根据查询中最常用的过滤器进行聚类——对表进行排序以跳过不相关的数据,这可以显著提高查询性能。
通过列统计支持数据跳过
从 HDFS 或云对象存储查询任何表时,您的查询引擎默认会扫描构成表的所有文件。这可能效率低下,特别是当您只需要较小的数据子集时。为了改进此过程,作为 Delta Lake 1.2 版本的一部分,我们通过利用 Delta 表的列统计信息,增加了对数据跳过的支持。
例如,当运行以下查询时,您不希望不必要地读取 `year` 或 `uid` 范围之外的文件。

当 Delta Lake 写入表时,它会自动收集最小值和最大值,并将其直接存储到 Delta 日志(即列统计信息)中。因此,当查询引擎读取事务日志时,这些读取查询可以跳过超出最小值/最大值范围的文件,如下图所示。
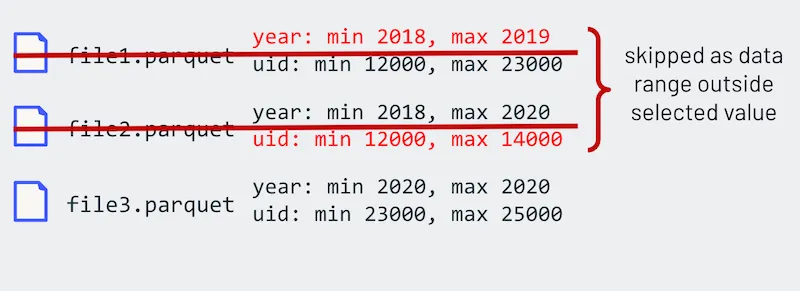
这种方法比 Parquet 文件内部的行组过滤更高效,因为您无需读取 Parquet 页脚。有关后者的更多信息,请参阅 Apache Spark™ 如何使用 Parquet 元数据执行快速计数。有关数据跳过的更多信息,请参阅 数据跳过。
支持数据 Z-Order 聚类以减少数据读取量
但使用列统计数据进行数据跳过只是解决方案的一部分。为了最大限度地提高数据跳过,还需要能够通过数据聚类进行跳过。如前所述,当文件的最小/最大范围非常小时,数据跳过最有效。虽然数据排序会有所帮助,但这在应用于单个列时最有效。
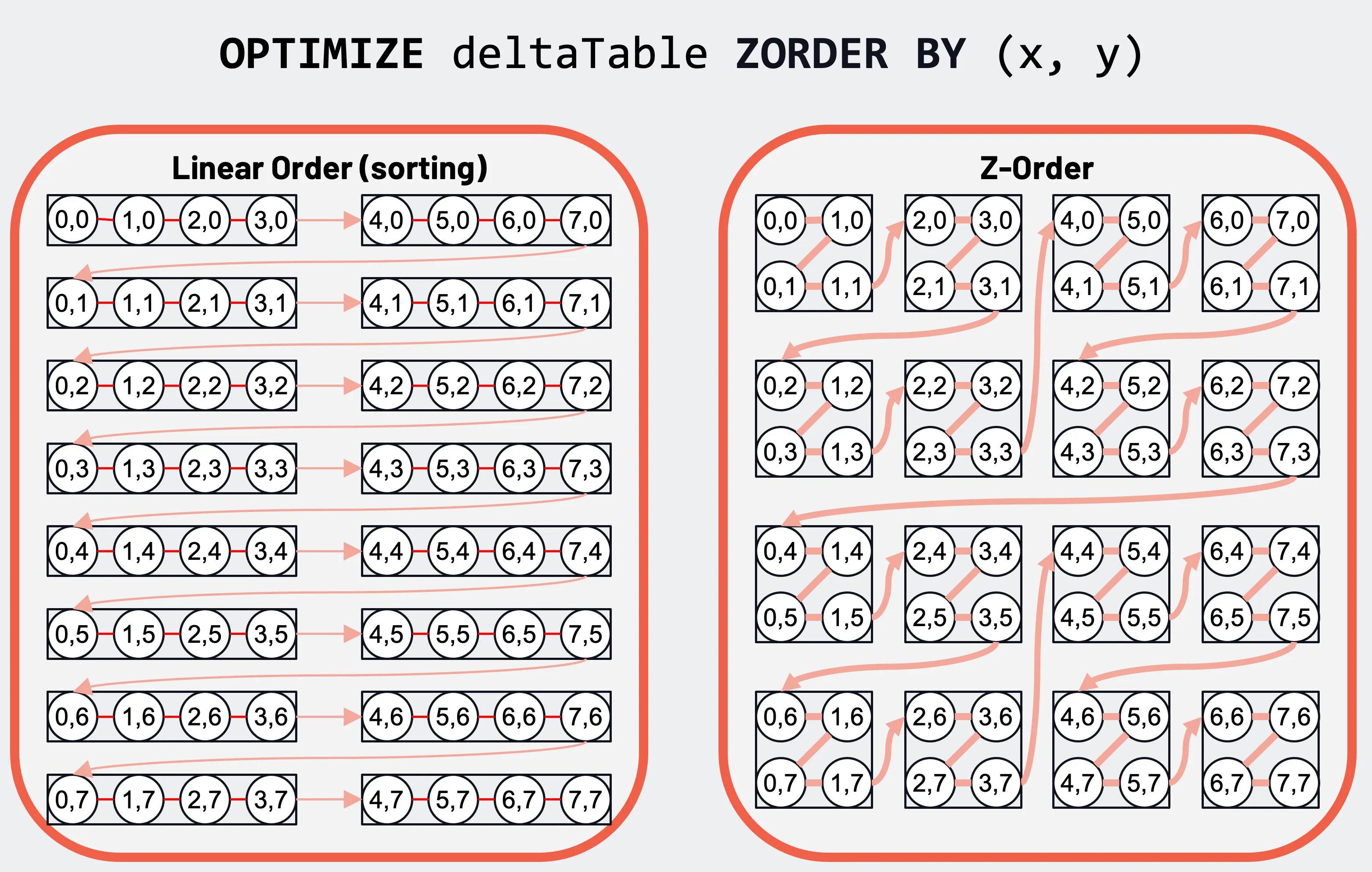
按主列和次列的常规数据排序(左)和两列的二维 Z-order 数据聚类(右)。
但有了 Z-order,其空间填充曲线提供了更好的多列数据聚类。这种数据聚类使得列统计数据在根据查询中的过滤器跳过数据方面更有效。有关更多详细信息,请参阅文档和此博客。
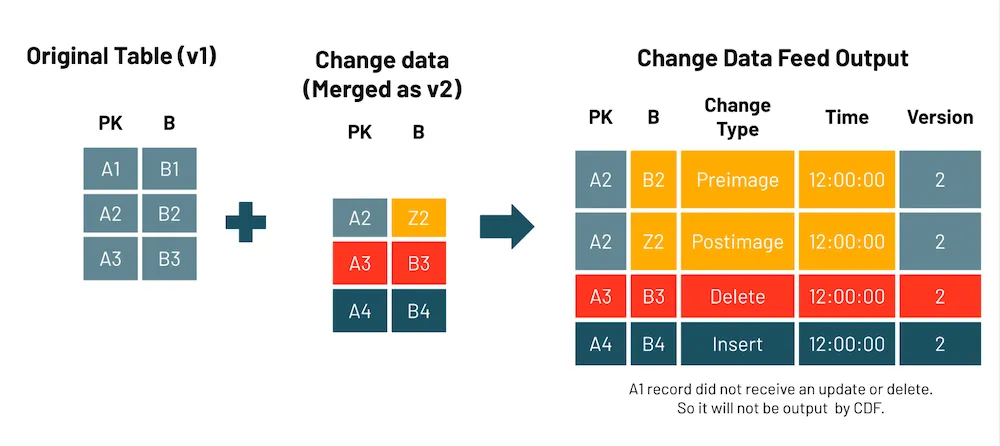
支持 Delta 表的变更数据流
Delta Lake 最大的价值主张之一是它能够在数据流带来记录变更的情况下保持数据可靠性。然而,这需要扫描和读取整个表,从而产生显着的开销,这会降低性能。
通过变更数据流(CDF),您现在可以按行级读取 Delta 表的变更流,而不是读取整个表,以捕获和管理用于最新白银和黄金表的变更。这提高了您的数据管道性能并简化了其操作。
要启用 CDF,您必须明确使用以下方法之一:
-
新建表:在 `CREATE TABLE` 命令中设置表属性 `delta.enableChangeDataFeed = true`。
CREATE TABLE student (id INT, name STRING, age INT) TBLPROPERTIES (delta.enableChangeDataFeed = true) -
现有表:在 `ALTER TABLE` 命令中设置表属性 `delta.enableChangeDataFeed = true`。
ALTER TABLE myDeltaTable SET TBLPROPERTIES (delta.enableChangeDataFeed = true) -
所有新表
set spark.databricks.delta.properties.defaults.enableChangeDataFeed = true;
需要记住的重要一点是,一旦您为表启用了变更数据流选项,您就不能再使用 Delta Lake 1.2.1 或更早版本向该表写入数据。但是,您始终可以读取该表。此外,只有在您启用变更数据流之后所做的更改才会被记录;对表的过去更改不会被捕获。
**那么您何时应该启用变更数据流?**以下用例应指导您何时启用变更数据流。
- 银表和金表:当您希望通过流式传输行级更改来更新银表和金表,从而提高 Delta Lake 性能时。这在遵循 `MERGE`、`UPDATE` 或 `DELETE` 操作时尤其明显,它们可以加速和简化 ETL 操作。
- 传输更改:将变更数据流发送到下游系统,例如 Kafka 或 RDBMS,这些系统可以使用该流来逐步处理数据管道的后续阶段。
- 审计追踪表:将变更数据流作为 Delta 表捕获,提供永久存储和高效查询能力,以查看随时间变化的所有更改,包括何时发生删除以及进行了哪些更新。
有关更多详细信息,请参阅文档。
支持删除列
对于 Delta Lake 1.2 之前的版本,Parquet 文件要求存储与表架构相同列名的数据。 Delta Lake 1.2 引入了 Parquet 文件中逻辑列名和物理列名之间的映射。虽然物理名称保持唯一,但逻辑列重命名变成了对映射的简单更改,并且逻辑列名可以包含任意字符,而物理名称仍符合 Parquet 规范。
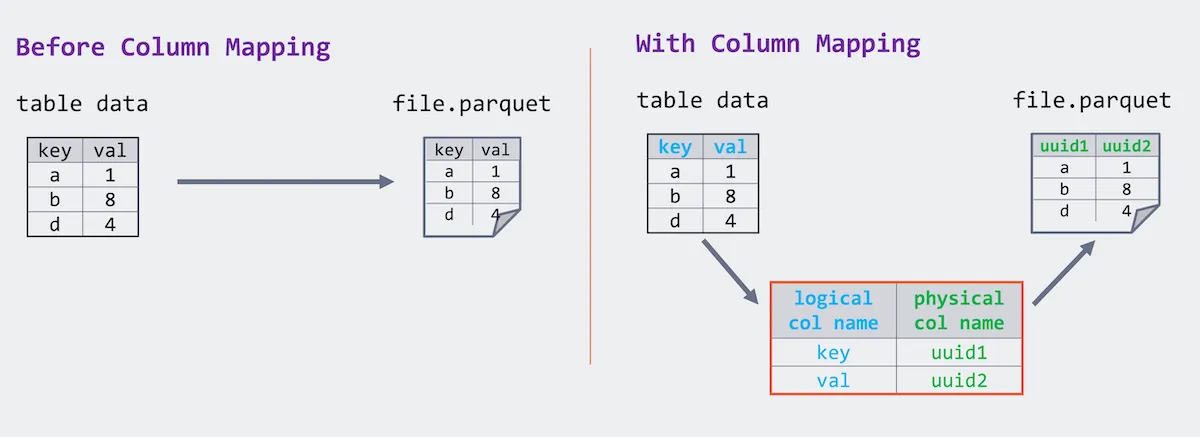
作为 Delta Lake 2.0 发布的一部分,我们利用了列映射,因此删除列是一种元数据操作。因此,与其物理修改底层表的所有文件来删除列,这可以是对 Delta 事务日志的简单修改(即元数据操作)以反映列的删除。运行以下 SQL 命令来删除列
ALTER TABLE myDeltaTable DROP COLUMN myColumn更多详情请参见文档。
支持动态分区覆盖
此外,Delta Lake 2.0 现在支持分区表的 Delta 动态分区覆盖模式;也就是说,只覆盖运行时写入数据的分区。
在动态分区覆盖模式下,我们将覆盖每个逻辑分区中所有现有数据,写入将提交新数据。写入不包含数据的任何现有逻辑分区将保持不变。此模式仅适用于数据以覆盖模式写入时:无论是 SQL 中的 `INSERT OVERWRITE`,还是使用 `df.write.mode("overwrite")` 的 DataFrame 写入。在 SQL 中,您可以运行以下命令
SET spark.sql.sources.partitionOverwriteMode=dynamic;
INSERT OVERWRITE TABLE default.people10m SELECT * FROM morePeople;请注意,动态分区覆盖与分区表的 `replaceWhere` 选项冲突。有关更多信息,请参阅文档了解详细信息。
Delta Lake 2.0 中的其他功能
本着性能优化的精神,Delta Lake 2.0.0 还包括以下额外功能:
- 支持对 Delta 表的幂等写入,以实现 Delta 表写入作业的容错重试,而无需多次写入数据。有关更多详细信息,请参阅文档。
- 多部分检查点实验性支持,将 Delta Lake 检查点拆分为多个部分,以加快检查点的写入和读取。有关更多详细信息,请参阅文档。
- 其他值得注意的更改
- 通过增加对嵌套列生成列的跳过支持,改进了生成列的数据跳过
- 通过阻止 Delta Lake 中不支持的数据类型,改进了表模式验证。
- 支持创建空模式的 Delta Lake 表。
- 更改了 `DROP CONSTRAINT` 的行为,当约束不存在时抛出错误。在此版本之前,该命令会静默返回。
- 修复了分区值中包含空格时符号链接清单生成的问题。
- 修复了收集到不正确提交统计信息的问题。
- 更多访问 Delta 表 OPTIMIZE 文件压缩命令的方式。
构建强大的数据生态系统
正如 Michael Armbrust 的第一天主题演讲和我们的 深入 Delta Lake 2.0 会议中所述,Delta Lake 的一个基本方面是其数据生态系统的健壮性。

随着数据量和种类持续增长,与最常见的摄取引擎集成变得至关重要。例如,我们最近宣布了与 Apache Flink、Presto 和 Trino 的集成——允许您直接从这些流行的引擎读写 Delta Lake。请访问 Delta Lake > 集成以获取最新集成。
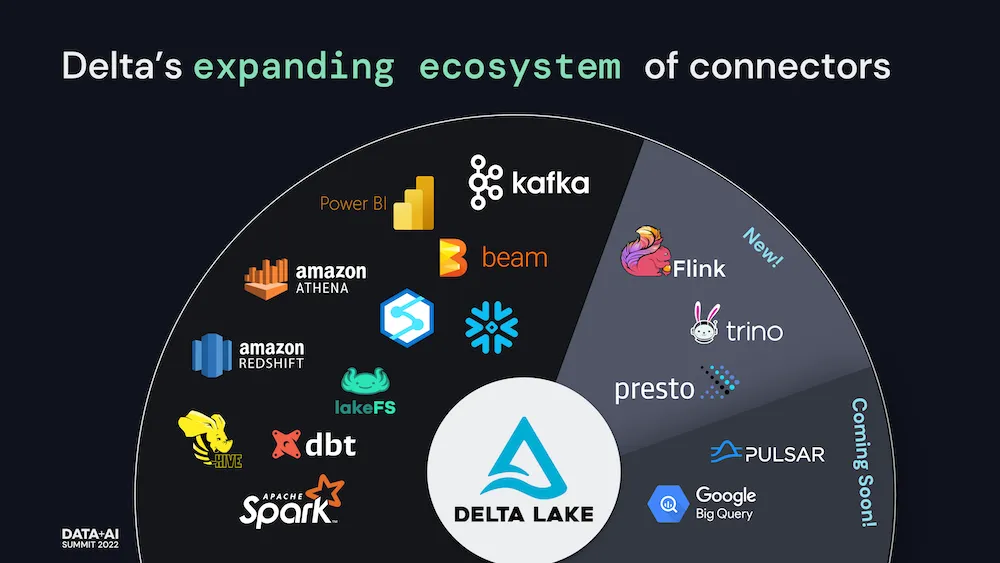
Delta Lake 将更多地被依赖,通过提供 ACID 事务并在现有云数据存储之上统一流式和批处理事务,为数据湖带来可靠性和改进的性能。通过与最流行的计算引擎和技术构建连接器,Delta Lake 的吸引力将持续增加——推动社区的更大增长以及该技术在世界上最具创新性和最大型企业中的快速采用。
社区扩展和增长的更新
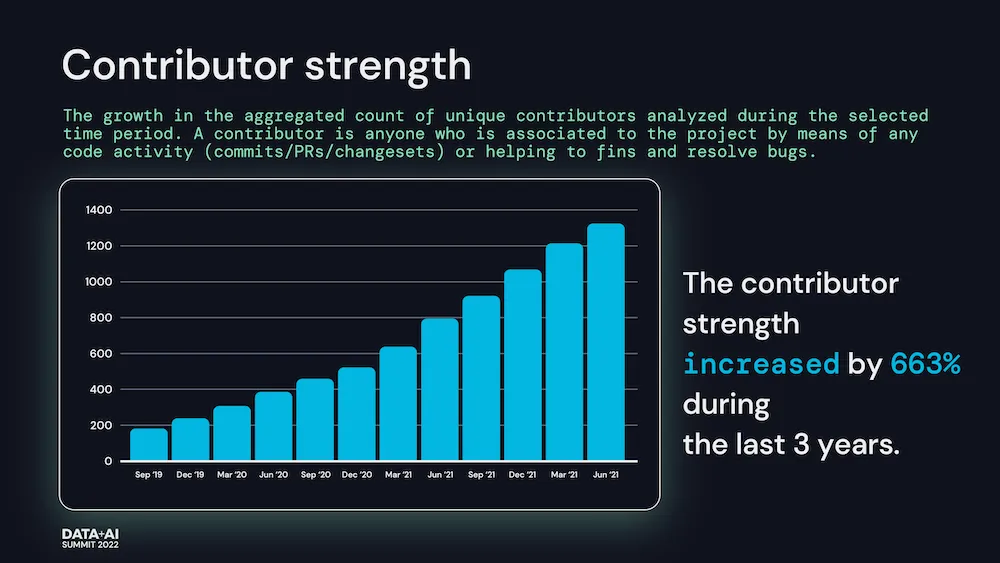
我们为社区以及多年来为数据湖屋提供最可靠、可扩展和高性能的表存储格式以确保始终如一的高质量数据所做的巨大努力感到自豪。这一切都离不开开源社区的贡献。在一年内,我们看到下载量从每月 68.5 万次猛增到每月超过 700 万次。如下图所示,这种增长很大程度上归因于快速扩展的 Delta 生态系统。
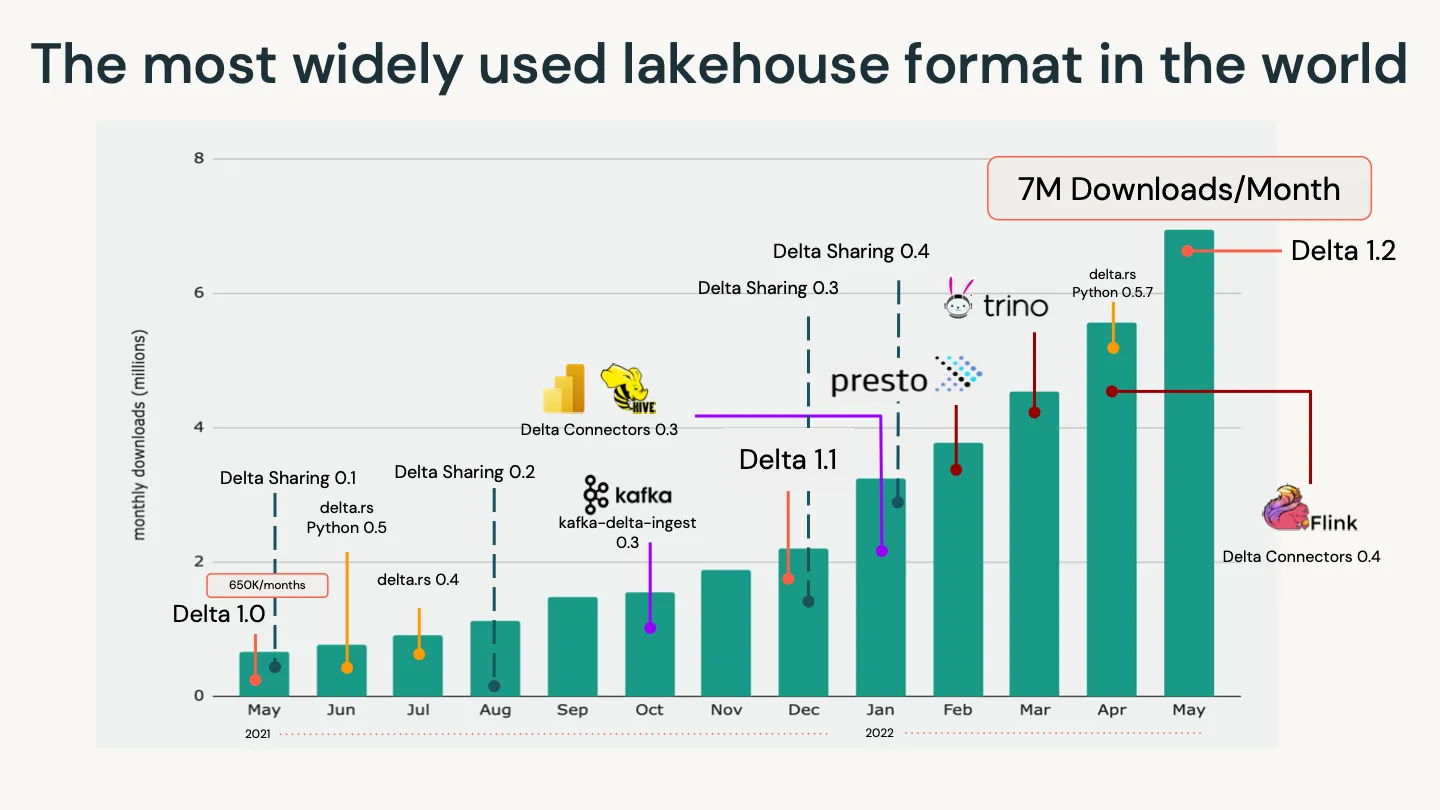
所有这些活动和独特贡献的增长——包括提交、PR、变更集和错误修复——在过去三年中使贡献者数量增加了 633%(来源:Linux 基金会洞察)。
但重要的是要记住,没有社区的贡献,我们不可能做到这一点。

致谢
在此,我们想向所有参与 Delta Lake 2.0 发布的人员表示衷心感谢:Adam Binford、Alkis Evlogimenos、Allison Portis、Ankur Dave、Bingkun Pan、Burak Yilmaz、Chang Yong Lik、Chen Qingzhi、Denny Lee、Eric Chang、Felipe Pessoto、Fred Liu、Fu Chen、Gaurav Rupnar、Grzegorz Kołakowski、Hussein Nagree、Jacek Laskowski、Jackie Zhang、Jiaan Geng、Jintao Shen、Jintian Liang、John O’Dwyer、Junyong Lee、Kam Cheung Ting、Karen Feng、Koert Kuipers、Lars Kroll、Liwen Sun、Lukas Rupprecht、Max Gekk、Michael Mengarelli、Min Yang、Naga Raju Bhanoori、Nick Grigoriev、Nick Karpov、Ole Sasse、Patrick Grandjean、Peng Zhong、Prakhar Jain、Rahul Shivu Mahadev、Rajesh Parangi、Ruslan Dautkhanov、Sabir Akhadov、Scott Sandre、Serge Rielau、Shixiong Zhu、Shoumik Palkar、Tathagata Das、Terry Kim、Tyson Condie、Venki Korukanti、Vini Jaiswal、Wenchen Fan、Xinyi、Yijia Cui、Yousry Mohamed。
我们还要感谢 Nick Karpov 和 Scott Sandre 对此帖子的帮助。
您如何提供帮助?
我们总是很高兴与现有和新的社区成员合作。如果您有兴趣帮助 Delta Lake 项目,请立即通过多种论坛加入我们的社区,包括 GitHub、Slack、Twitter、LinkedIn、YouTube 和 Google Groups。
