多集群写入S3上的Delta Lake存储
虽然Delta Lake自诞生以来就支持多集群并发读取,但在多集群写入Amazon S3方面存在限制。请注意,这并非Azure ADLSgen2或Google GCS的限制,因为S3目前缺乏“put-If-Absent”(不存在则写入)一致性保证。因此,为了在S3上保证ACID事务,需要并发写入源自同一个Apache Spark™驱动。这是社区最常请求的问题之一,我们很高兴地宣布Delta Lake 1.2(发布说明,博客)现在支持从多个集群向S3写入数据,同时保持写入的事务性。
S3多集群写入
如前所述,由于S3不支持“put-if-absent”一致性保证,Delta Lake此前无法实现多集群S3写入。没有此保证,Delta Lake在跨集群写入时无法实现互斥,因为无法确保在任何给定时间只有一个写入器正在创建或重命名给定文件。让我们深入探讨为什么这对Delta Lake ACID事务保证至关重要,以及我们如何在Delta Lake 1.2中克服它。
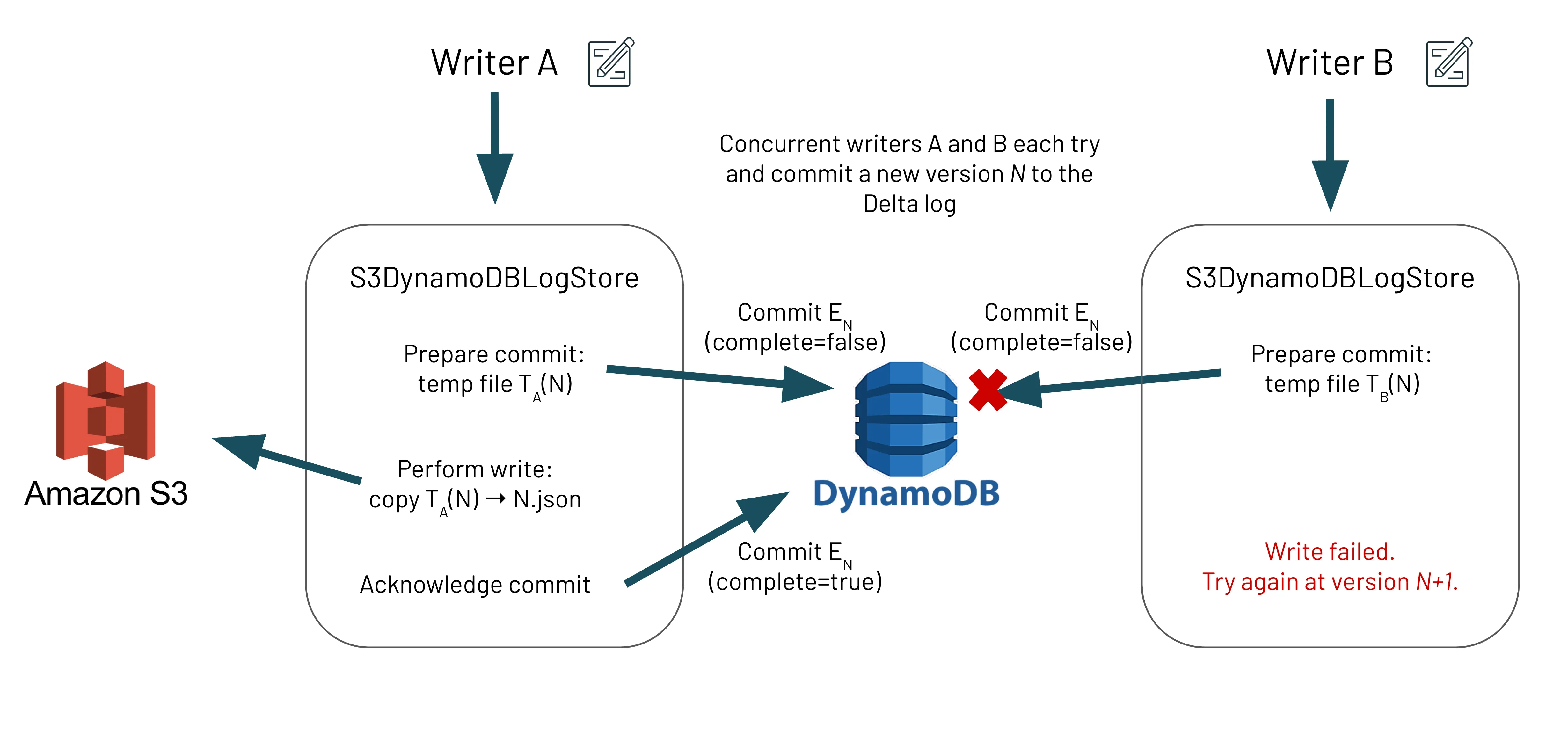
Delta Lake通过提交到事务日志来管理事务的原子性,事务日志仅在S3存储系统中不存在时才创建新的日志文件。然而,S3没有提供一种原子性地检查文件是否存在再写入的方法,这可能导致并发写入器多次提交相同版本的文件,从而覆盖文件中之前的更改。这可能导致数据丢失。借助新的S3DynamoDBLogStore LogStore API,Delta Lake现在允许来自多个集群和/或Spark驱动的所有写入器并发写入Delta Lake S3,同时确保每个事务只有一个写入器成功。这保持了原子性并防止文件内容被覆盖。
为了在S3之上构建这种互斥,Delta Lake维护一个DynamoDB表,其中包含哪些文件已尝试提交以及哪些文件已成功完成写入的信息。通过利用DynamoDB的原子更新操作,Delta Lake可以确保,对于任意数量的并发写入器和给定文件,只有一个写入器会胜出并被允许写入S3。
设计
让我们看看Delta Lake在底层是如何设计的,以保证从多个集群和/或Spark驱动向S3写入的ACID事务。需要注意的是,我们讨论的是事务日志写入_delta_log文件夹;我们不指代Parquet数据文件的写入。在S3DynamoDBLogStore内部的新写入算法确保写入器首先通过将元数据(约200字节)写入DynamoDB来准备文件提交,然后再将事务日志条目写入文件系统。对DynamoDB的写入使用PutItem操作,该操作确保只有当条目尚不存在时才将其添加到表中。由于这是原子操作,如果两个并发写入器都尝试写入同一版本,则只有一个会在DynamoDB提交期间胜出,从而实现ACID事务所需的互斥范例。
DynamoDB中可能存在不完整条目,并且其目标文件在文件系统中不存在。这通过两种方式解决:
- 读取器将尝试通过查询DynamoDB获取最新的不完整条目(根据我们的以下不变量,最多一个)并对其执行“恢复”操作来修复此问题。
- 写入器将始终检查文件系统中是否存在先前的事务日志文件,如果不存在,则在尝试当前提交之前执行相同的“恢复”操作。
为什么Samba TV需要S3多集群写入?
Samba TV是电视技术领域的全球领导者,提供实时洞察和受众定位,从而实现无与伦比的营销效率和效果。该公司拥有来自全球100多个国家/地区销售的20多个电视品牌中数千万选择加入的电视的专有第一方数据,为广告商和媒体公司提供整个消费者旅程的统一视图。
在Samba TV,我们从2019年在阿姆斯特丹Spark + AI Summit 2019推出之初就考虑使用Delta Lake。我们当时在Amazon EMR(弹性Map Reduce)的多集群环境中运行并行Spark作业来处理存储在S3上的数据,我们知道Delta Lake不适合我们,因为Delta Lake文档明确提到S3仅支持单集群场景。这被记录为Delta OSS社区的一个问题,引发了(双关语)许多关于可能解决方案的有趣讨论。
为了解决这个问题,我们开始在此PR(pull request)中使用DynamoDB实现这些想法。我们仔细测试了这种方法(例如,在重负载下执行了大量压力测试),并很快开始在我们的生产系统中使用它。如今,我们有许多高价值数据集(数十TB)存储在Delta Lake S3中。我们使用一个DynamoDB表来存储Delta日志条目(没有保留策略),总计近40万个事务。
重要的是,Delta Lake为我们提供了进一步的CCPA / GDPR合规性。我们是一家注重隐私的公司,Delta Lake帮助我们支持删除个人数据的请求。
实施 - 从多集群向S3中的Delta Lake表写入数据
从版本1.2开始,Delta Lake支持来自多个集群的并发读取和写入,并提供事务保证。这必须通过配置Delta Lake使用正确的LogStore实现来明确启用,该实现使用DynamoDB来提供S3所缺乏的互斥性。
确保多节点集群中的所有节点和/或Spark驱动程序都使用此LogStore实现以及相同的DynamoDB表和区域。如果某些驱动程序使用开箱即用的Delta Lake,而其他驱动程序使用此实验性LogStore,则可能存在数据丢失的风险。
要求
- S3凭证:IAM角色(推荐)或访问密钥
- DynamoDB操作权限
- 与相应Delta Lake版本关联的Apache Spark。
- Hadoop的AWS连接器 (hadoop-aws),用于Apache Spark编译所用的Hadoop版本。
- JAR文件:
delta-storage-s3-dynamodb artifact
设置配置
1. 创建DynamoDB表。
您可以选择自己创建DynamoDB表(推荐),或让系统自动为您创建。
选项1:自己创建DynamoDB表(推荐) 此DynamoDB表将维护多个Delta表的提交元数据,并且重要的是,它配置了适合您用例的读/写容量模式(例如,按需或预置)。因此,我们强烈建议您自己创建DynamoDB表。以下示例使用AWS CLI。要了解更多信息,请参阅create-table命令参考。
aws dynamodb create-table \
--region us-east-1 \
--table-name delta_log \
--attribute-definitions AttributeName=tablePath,AttributeType=S \
AttributeName=fileName,AttributeType=S \
--key-schema AttributeName=tablePath,KeyType=HASH \
AttributeName=fileName,KeyType=RANGE \
--billing-mode PAY_PER_REQUEST注意:一旦您选择表名和区域,您将必须在每个Spark会话中指定它们,以便此多集群模式正常工作。请参阅下表
选项2:自动创建DynamoDB表 尽管如此,在指定此LogStore实现后,如果默认的DynamoDB表尚不存在,则将自动为您创建。此默认表支持每秒5次强一致性读取和5次写入。您可以使用下表中详细说明的仅用于表创建的配置键来更改这些默认值。
2. 按照单集群设置的配置部分中列出的配置步骤进行操作。
3. 在类路径中包含delta-storage-s3-dynamodb和aws-java-sdk的JAR文件。
4. 在您的Spark会话中配置LogStore实现。
首先,为s3方案配置此LogStore实现。
spark.delta.logStore.s3.impl=io.delta.storage.S3DynamoDBLogStore接下来,指定实例化DynamoDB客户端所需的附加信息。您必须在每个Spark会话中用相同的tableName和region实例化DynamoDB客户端,此多集群模式才能正常工作。下面列出了每个会话的配置及其默认值
| 配置键 | 描述 | 默认值 |
|---|---|---|
spark.io.delta.storage.S3DynamoDBLogStore.ddb.tableName | 要使用的DynamoDB表名称 | delta_log |
spark.io.delta.storage.S3DynamoDBLogStore.ddb.region | 客户端要使用的区域 | us-east-1 |
spark.io.delta.storage.S3DynamoDBLogStore.credentials.provider | 客户端使用的AWSCredentialsProvider* | DefaultAWSCredentialsProviderChain |
spark.io.delta.storage.S3DynamoDBLogStore.provisionedThroughput.rcu | (仅限表创建**)读取容量单位 | 5 |
spark.io.delta.storage.S3DynamoDBLogStore.provisionedThroughput.wcu | (仅限表创建**)写入容量单位 | 5 |
- *有关AWS凭证提供商的更多详细信息,请参阅AWS文档。
- **这些配置仅在给定DynamoDB表尚不存在且需要自动创建时使用。
讨论
在这篇博客文章中,我们解释了Delta Lake由于缺乏“put-if-absent”一致性保证而无法向AWS S3进行多驱动/集群/JVM写入的原因。为了解决这个热门问题,我们利用了我们最初的问题(#41)和拉取请求(#339)来构建本文描述的当前解决方案。有关更多信息,请参阅此拉取请求(#1044)和设计文档:[2021-12-22] Delta OSS S3多集群写入[公开]。如果您有任何问题,请通过Dela Users Slack、Google Groups、LinkedIn加入我们,或参加我们的每两周一次的办公时间。