Delta Lake 1.2——速度、效率和可扩展性空前提升
作者:Venki Korukanti、Scott Sandre、Tathagata Das、Allison Portis、Denny Lee、Vini Jaiswal
Delta Lake 的持续创新是整个开源社区共同努力的直接结果。本次发布中的最新亮点包括但不限于:来自 SambaTV 的 Mariusz Kryński 贡献的 S3 多集群写入功能,来自 Ververica 的 Fabian Paul 协助设计的 Flink/Delta Lake 连接器,以及 Maksym Dovhal 对 RESTORE 功能的贡献。基于我们出色的社区在 Delta Lake 1.1.0 中实现的显著改进,我们很高兴地宣布在 Apache Spark™ 3.2 上发布 Delta Lake 1.2(1.2.0、1.2.1)。
Delta Lake 1.2(1.2.0、1.2.1)引入了侧重于优化性能和操作效率的功能,包括小文件合并、高级数据跳过、Delta 表的版本控制、对 schema 演进操作的支持、对列名中任意字符的扩展支持等等。此外,与 Apache Flink、Presto 和 Trino 等第三方工具的新集成提供了更高的可扩展性和灵活性,可充分释放 Delta Lake 中所有数据的潜力。
本文将介绍本次发布中的主要变化和一些值得关注的功能。有关完整的更改列表,请参阅 Delta Lake 1.2(1.2.0、1.2.1)发布说明。此外,请查看项目的 Github 仓库以获取详细信息。在随后的博客文章中,我们将深入探讨每个关键功能及其提供的价值。
我们将在本博客中重点介绍 Delta 1.2 版本中的以下功能
性能:
- 支持将 Delta 表中的小文件(优化)合并为大文件
- 支持数据跳过
- 支持 S3 多集群写入
用户体验:
- 支持将 Delta 表恢复到早期版本
- 支持 schema 演进操作,例如 RENAME COLUMN
- 支持 Delta 表列名中的任意字符
本次发布中还包含了 Delta 基准测试,这是一个用于编写基准测试以衡量 Delta 性能的基本框架。它目前旨在 EMR 集群上运行 Apache Spark™ 的 TPC-DS 基准测试。请查看基本的 OSS 框架:https://github.com/delta-io/delta/tree/master/benchmarks。
继续阅读以了解更多信息!
想立即开始使用 Delta Lake 吗?了解更多关于 Delta Lake 的信息,并使用此指南使用 Delta Lake 构建数据湖屋。
将 Delta 表中的小文件(优化)合并为大文件
数据湖屋中的数据通常会遇到小文件问题。不同的文件大小会影响性能并浪费宝贵的资源。因此,正确布局数据对于实现最佳查询性能至关重要。为了提高查询速度,Delta Lake 支持优化存储中数据布局的能力。有多种方法可以优化布局。目前,仅支持装箱优化。Delta Lake 可以通过将小文件合并为大文件来提高从表中读取查询的速度。
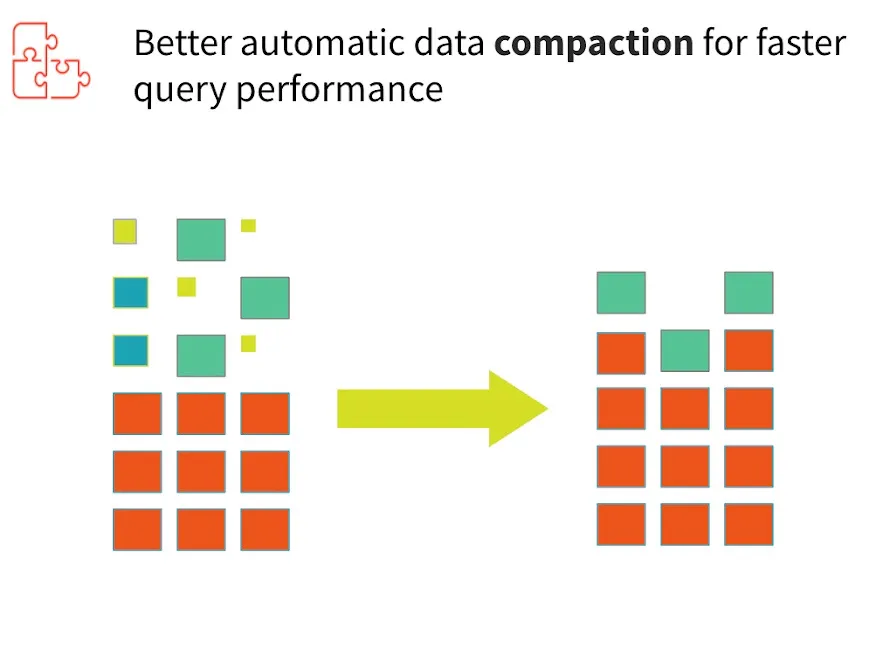
通过减少摄取的数据文件数量,将 Delta 表中的小文件合并为大文件可以直接减少元数据大小以及每个文件的开销(例如文件打开开销和文件关闭开销),从而提高读取延迟。
OPTIMIZE delta_table_name; -- Optimizes Delta Lake table
OPTIMIZE delta.`/path/to/delta/table`; -- Optimizes the path-based Delta Lake table如果您有大量数据并且只想优化其中的一部分,您可以使用 WHERE 指定可选的分区谓词。
OPTIMIZE delta_table_name WHERE date >= '2017-01-01'您可能会问,装箱优化期间 Delta 表读取是否受到影响?答案是否定的。通过使用快照隔离,当装箱优化从事务日志中删除不必要的文件时,表读取不会中断。实际上没有对表进行任何数据相关的更改,因此所有读取将始终具有相同的结果。有关更多详细信息,请参阅文档。
支持自动数据跳过
当您将数据写入 Delta Lake 表时,会自动收集数据跳过信息。这些统计信息(每列的最小值和最大值)可以在读取 Delta 表时用于跳过读取与查询中过滤器不匹配的文件,从而实现更快的查询。
SELECT * FROM events
WHERE year=2020 AND uid=24000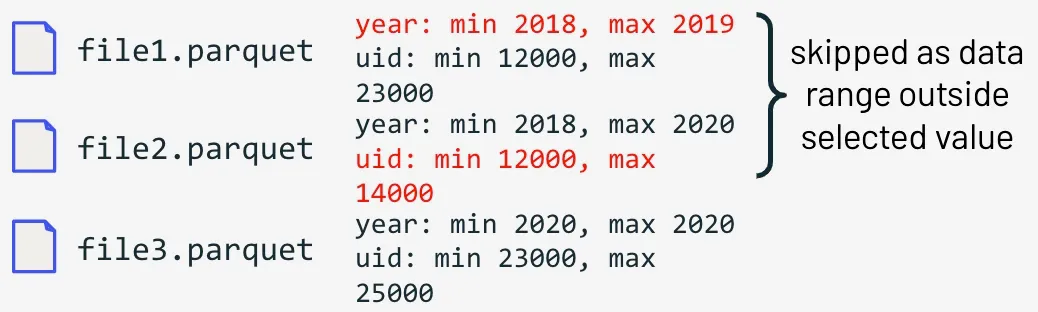
在上面的示例中,我们的查询正在寻找 2020 年由 uid “24000” 触发的事件。由于在写入时收集了数据跳过信息,Delta 可以轻松跳过不匹配查询条件(在本例中为 file1.parquet 和 file2.parquet)的记录,并在 file3.parquet 中查找匹配的记录。
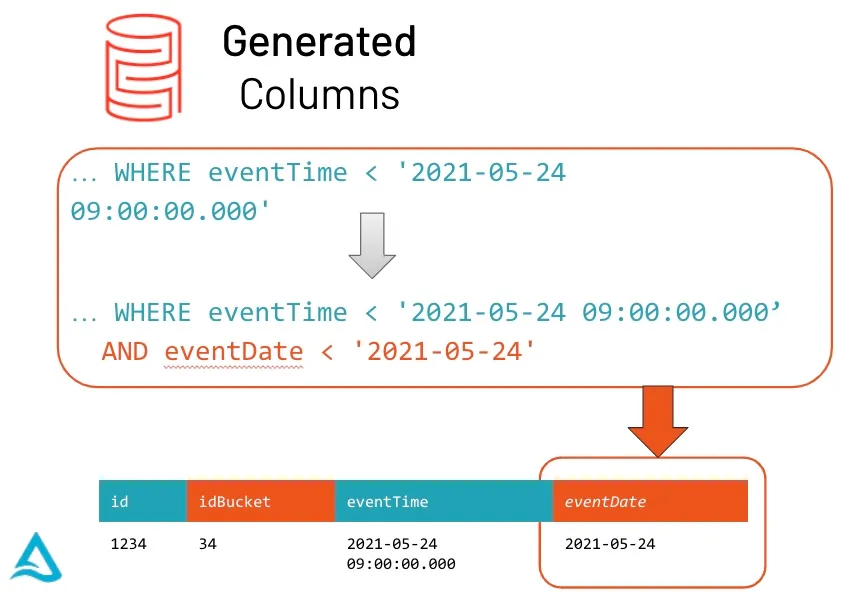
支持生成列
当用户在写入表时不提供生成列时,Delta Lake 将自动计算生成列;或者当用户提供生成列的值时,Delta Lake 将使用生成表达式自动检查约束。
对于具有生成表达式的分区列,如果可能,Delta Lake 会自动从其生成列上的任何数据过滤器生成分区过滤器。当查询中存在适用的谓词时,Delta Lake 会自动使用分区和统计信息读取最少量的数据。通过这种新的优化,返回的 DataFrame 会自动读取表的最新快照以进行任何查询;您永远不需要运行 REFRESH TABLE。
S3 多集群写入支持
Delta Lake 提供的一个关键功能是其在提供 ACID 保证的同时处理并发读写的能力。此功能本身取决于底层存储系统提供的保证,其中之一是互斥:确保一次只有一个写入器能够创建文件。
大多数存储系统都提供开箱即用的互斥。然而,S3 的一个已知限制是它不提供互斥,这意味着 Delta Lake S3 集成允许多集群读取,但历史上将 S3 写入限制为源自单个 Spark 驱动程序。
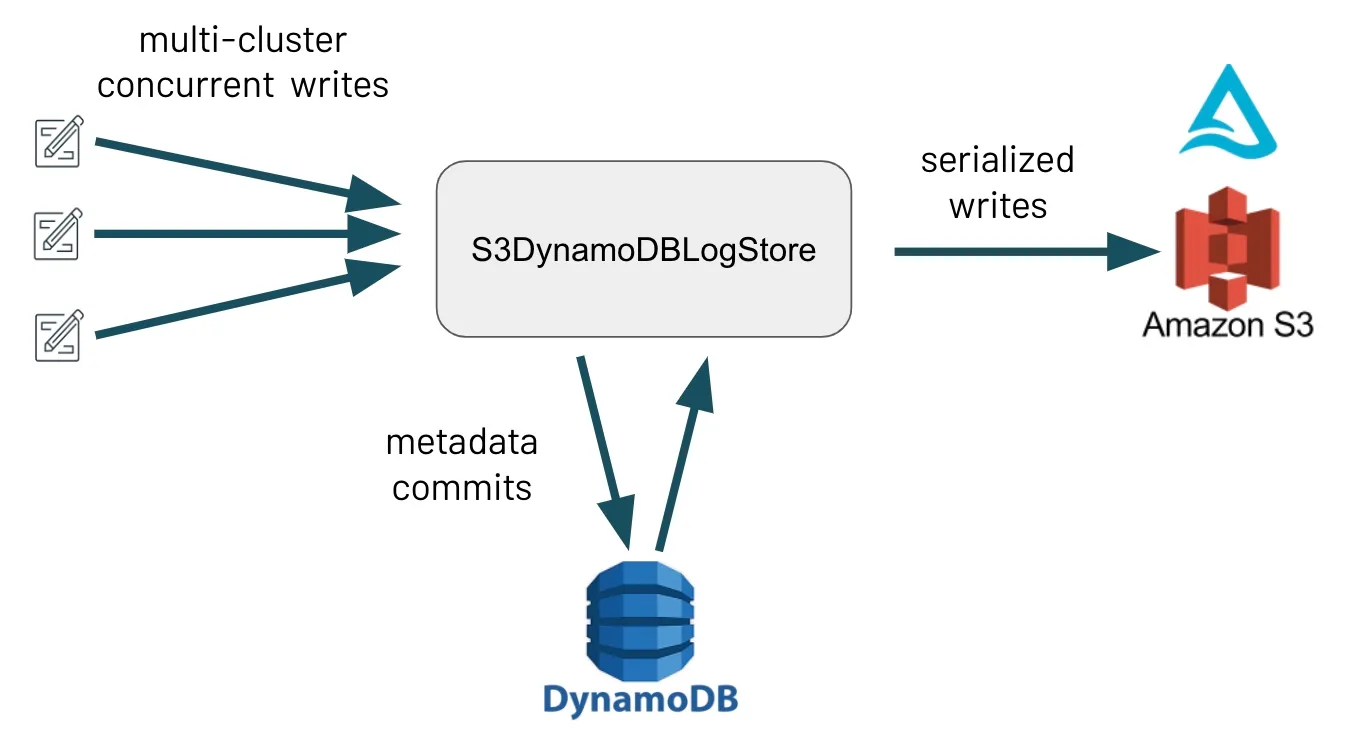
Delta Lake 1.2 的这些变化,使得 S3 的读写现在支持两种不同的模式:单集群和多集群。在多集群模式下,用户可以从多个集群并发写入同一个 Delta 表。此模式在内部使用 DynamoDB 来提供 S3 缺乏的互斥性,因为并发写入器首先尝试将元数据提交到 DynamoDB 表,然后再写入 S3。注意:多集群模式必须显式启用。请查看我们的贡献者 spotlight,以了解此功能。
支持将 Delta 表恢复到早期版本
糟糕的数据质量会毁掉任何数据分析或机器学习用例。有时,会发生诸如意外的错误写入或删除等错误。幸运的是,Delta Lake 支持使用 RESTORE 命令将 Delta 表恢复到早期状态,以解决此问题。
Delta 表在内部维护表的历史版本,使其能够恢复到早期状态。可以使用上述 SQL 命令、Scala API 或 Python API 支持与早期状态对应的版本或创建早期状态的时间戳。
RESTORE TABLE deltaTable TO VERSION AS OF <version>
RESTORE TABLE delta.`/path/to/delta/table` TO TIMESTAMP AS OF <timestamp>from delta.tables import *
deltaTable = DeltaTable.forPath(spark, <path-to-table>) # path-based tables, or
deltaTable = DeltaTable.forName(spark, <table-name>) # Hive metastore-based tables
deltaTable.restoreToVersion(0) # restore table to oldest version
deltaTable.restoreToTimestamp('2019-02-14') # restore to a specific timestamp恢复先前版本时,历史操作会返回数据湖中操作指标的集合。这些指标可以提供数据湖中操作洞察的可见性。有关按操作列出映射键定义的表,请参阅文档。
通过跟踪数据的历史版本,您可以简化数据工程,并确信您将始终能够在自己的云存储中使用干净、集中、版本化的大数据存储库进行分析和机器学习。
支持重命名列
构建用于下游分析的可靠数据管道的一个重要方面是模式演进。模式会随着时间的推移而演进,因此,对于那些处理所管理数据的人来说,无论模式何时定义或重新访问,都能够摄取数据非常重要。通过支持模式演进操作,Delta Lake 可以防止不良数据导致数据损坏。
从 Delta Lake 1.2 开始,现在支持重命名列。要在不重写任何列的现有数据的情况下重命名列,您必须为表启用列映射。以下是您如何在 Delta 表上启用列映射的方法。
ALTER TABLE <table_name> SET TBLPROPERTIES (
'delta.minReaderVersion' = '2',
'delta.minWriterVersion' = '5',
'delta.columnMapping.mode' = 'name'
)启用列映射后,您可以使用以下 SQL 命令重命名列
ALTER TABLE <table_name> RENAME COLUMN old_col_name TO new_col_name要了解更多受支持的其他模式演进操作,请参阅文档以获取更多详细信息。
支持 Delta 表列名中的任意字符
您可以在 Delta Lake 1.2 中进行的另一个模式更改是支持任意字符。
在 1.2 之前,支持的字符列表受到 Parquet 数据格式中相同字符支持的限制。当 Delta 表启用列映射时,您可以在表的列名中包含空格以及以下任何字符:,;{}()\n\t=。
重命名列
ALTER TABLE <table_name> RENAME COLUMN old_col_name TO new_col_name重命名嵌套字段
ALTER TABLE <table_name> RENAME COLUMN col_name.old_nested_field TO new_nested_field有关如何在模式中包含这些字符的示例,请参阅文档以获取更多详细信息。
我们希望您和我们一样对这些新的 Delta Lake 功能感到兴奋。请随意试用 Delta Lake 1.2。有任何工作负载需要迁移到 Delta Lake 吗?请查看此指南。最后,请向社区提供任何反馈或性能基准测试。
总结
Delta Lake 正在迅速成为构建基于数据湖屋架构的转型数据公司的事实开源存储框架。随着数据量和复杂性不断增加,以大规模更快、更可靠地摄取数据至关重要。借助 Delta Lake 1.2,开发人员可以充分利用为提高生产力而设计的性能优化和操作效率。
接下来
我们已经为 Delta Lake 的下一个版本准备了许多新功能。您可以在GitHub 里程碑中跟踪所有即将发布的版本和计划的功能。
对开源 Delta Lake 感兴趣?请访问Delta Lake了解更多信息,您可以通过 Slack 和 Google Group 加入 Delta Lake 社区。
致谢
我们要感谢以下贡献者在 Delta Lake 1.2 中进行的更新、文档更改和贡献:Adam Binford、Alex Liu、Allison Portis、Anton Okolnychyi、Bart Samwel、Carmen Kwan、Chang Yong Lik、Christian Williams、Christos Stavrakakis、David Lewis、Denny Lee、Fabio Badalì、Fred Liu、Gengliang Wang、Hoang Pham、Hussein Nagree、Hyukjin Kwon、Jackie Zhang、Jan Paw、John ODwyer、Junlin Zeng、Jackie Zhang、Junyong Lee、Kam Cheung Ting、Kapil Sreedharan、Lars Kroll、Liwen Sun、Maksym Dovhal、Mariusz Krynski、Meng Tong、Peng Zhong、Prakhar Jain、Pranav、Ryan Johnson、Sabir Akhadov、Scott Sandre、Shixiong Zhu、Sri Tikkireddy、Tathagata Das、Tyson Condie、Vegard Stikbakke、Venkata Sai Akhil Gudesa、Venki Korukanti、Vini Jaiswal、Wenchen Fan、Will Jones、Xinyi Yu、Yann Byron、Yaohua Zhao、Yijia Cui。