从 Apache Flink 写入 Delta Lake
作者:Fabian Paul 、Pawel Kubit 、Scott Sandre 、Tathagata Das 、Denny Lee
Delta Connectors 0.3.0 最令人兴奋的方面之一是增加了写入功能,并提供了新的 API 来支持在没有 Apache Spark™ 的情况下创建和写入 Delta 表。最新版本 0.4.0 的 Delta Connectors 引入了 Flink/Delta 连接器,它提供了一个 sink,可以从 Apache Flink 写入 Parquet 数据文件并将其原子地提交到 Delta 表。这个 sink 使用 Flink 的 DataStream API,并支持批处理和流处理。
在我们深入了解连接器的细节之前,先介绍一下 Apache Flink 和 Delta Lake 的背景。
Apache Flink - 用于有状态计算的分布式处理引擎
Apache Flink 是一个开源的分布式处理系统,用于流数据和批数据。它旨在在所有常见的集群环境中运行,以内存速度和任何规模执行计算,具有容错性和极低的延迟。您可以使用 Flink 在数据生成时以及数据存储在存储系统后处理大量实时数据流。这使得实时流应用程序和分析成为可能。
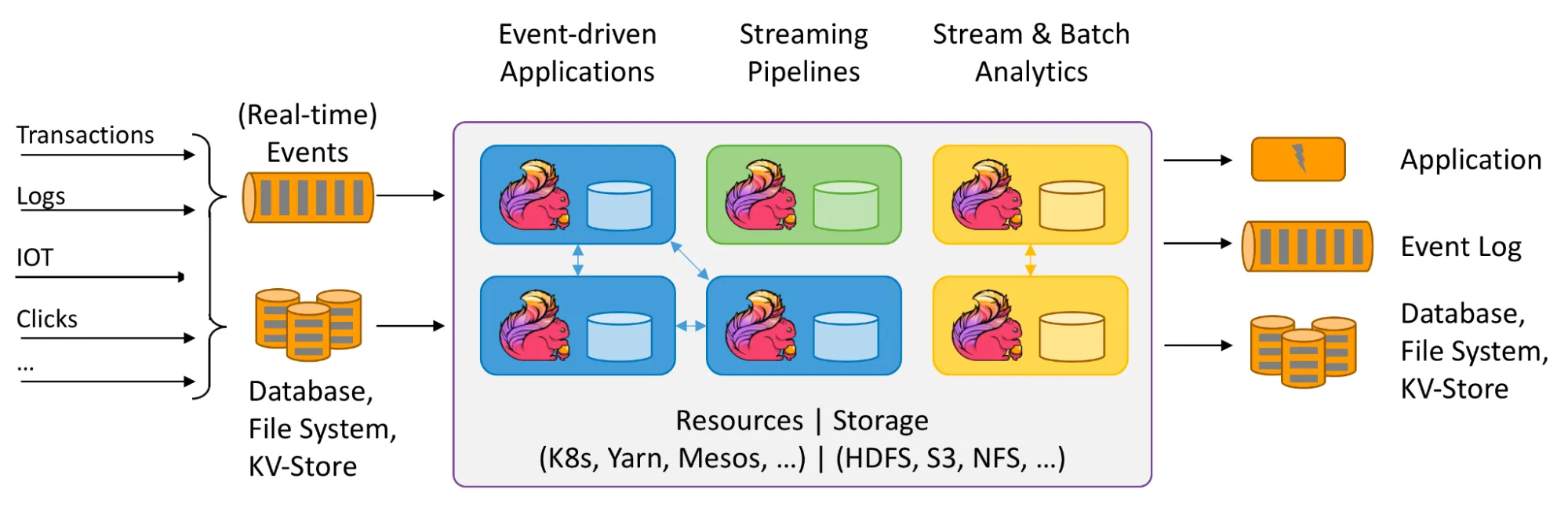
为了编写 Flink 程序,用户需要使用与 API 无关的连接器以及 FileSource 和 FileSink 来读取和写入数据到外部数据源,例如 Apache Kafka、Elasticsearch 等。所有连接器都位于提交给 Flink 的程序的通用部分。在这种情况下,程序要么是包含连接器依赖项(DataStream API、Table API)的 jar 包,要么是假定 Flink 集群可以相应地访问连接器依赖项的 SQL 查询。有关 Flink 的更多信息,请参阅 Apache Flink 文档。
Delta Lake - 开源数据湖存储标准
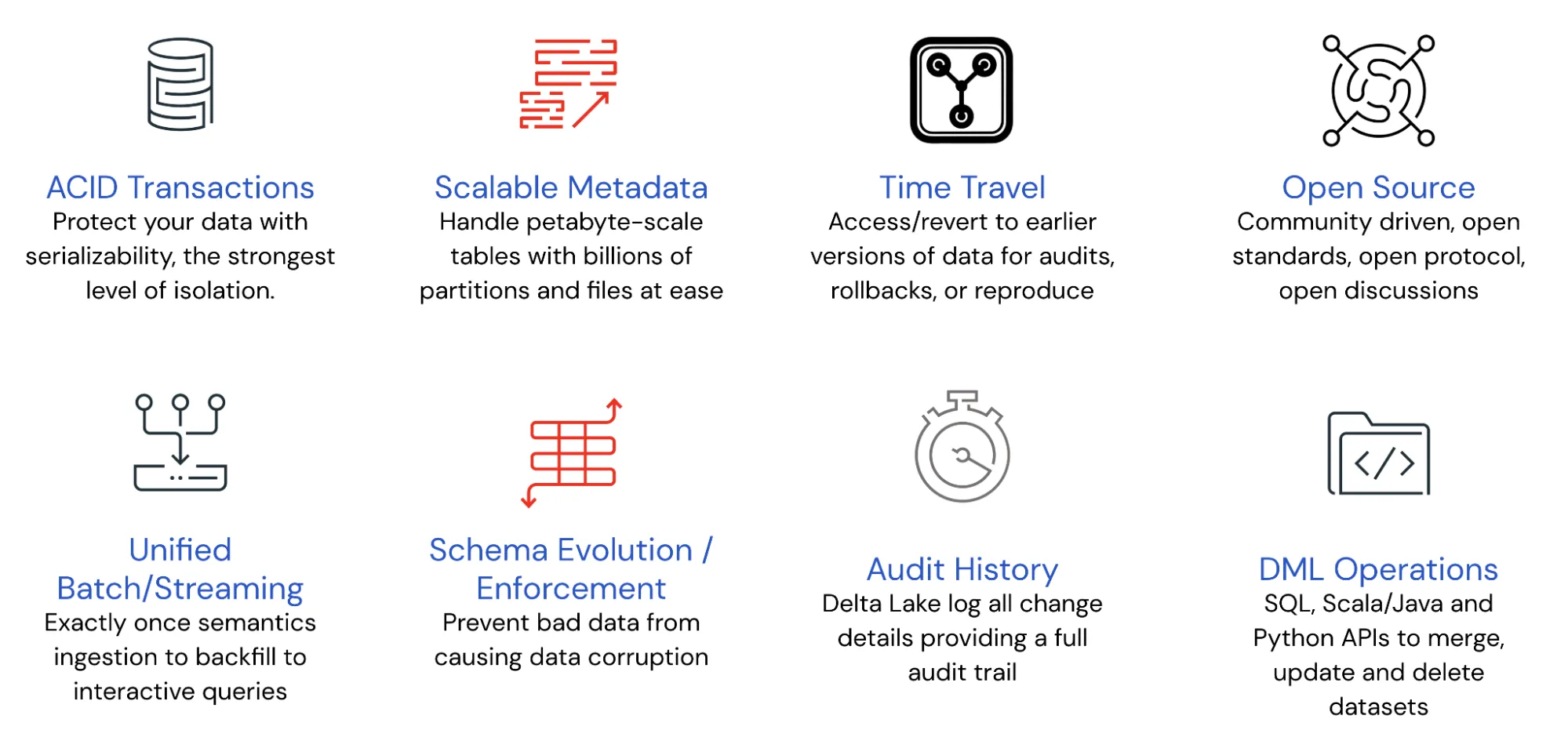
Delta Lake 是一个开源项目,旨在为数据 湖屋 构建,支持包括 Spark、PrestoDB、Flink 和 Hive 在内的计算引擎,并提供 Scala、Java、Rust 和 Python 的 API。它是一个数据存储层,通过提供 ACID 事务、轻松处理 PB 级分区元数据以及统一现有云数据存储之上的流式和批处理事务,为数据湖带来了可靠性和性能提升。
Delta Lake 本质上是一个高级存储系统,它将数据存储在带有分区的 parquet 文件中,并维护一个丰富的事务日志,以便提供 ACID 事务和时间旅行等功能。此外,日志还包含每个数据文件的最小/最大统计信息等元数据,使得元数据搜索比“对象存储中的文件”方法快一个数量级。有关更多信息,请参阅 VLDB 白皮书 Delta Lake:云对象存储上的高性能 ACID 表存储。
下图列出的功能使 Delta Lake 成为构建数据湖屋的最佳解决方案。
Delta 使用乐观并发协议在底层对象存储中存储元数据和事务状态。这意味着 Delta 表可以维护状态而无需任何主动运行的服务器,而只需要用于执行查询的服务器,从而利用了独立扩展计算和存储的优势。
原生 Flink Delta Lake 连接器
对于那些利用 Flink 构建实时流应用程序和/或分析的人,我们很高兴宣布新的 Flink/Delta 连接器,它使您能够将数据存储在 Delta 表中,从而利用 Delta 的可靠性和可伸缩性,同时保持 Flink 的端到端 exactly-once 处理。
Flink/Delta 连接器旨在为批处理和流处理用例在追加模式下创建 Flink 的 DataStreams API sink。该连接器确保 Flink 中的数据以幂等方式写入 Delta 表,即使 Flink 管道从其检查点信息重新启动,管道也将保证数据不丢失或重复,从而保留 Flink 的 exactly-once 语义。如果管道在没有检查点的情况下重新启动,则无法保证 exactly-once 处理。
Flink Delta Sink 连接器由以下关键组件组成
DeltaWriter
DeltaWriter 的目标是管理分区表的桶写入器,并将传入事件传递给正确的桶写入器。一个写入器可以同时将数据写入多个桶(也称为分区),但每个桶只能有一个文件处于进行中(即“打开”)状态。如果 Delta 表未分区,则一个 DeltaWriter 将只有一个桶写入器,该写入器将写入表的根路径。
Delta 文件可以有 3 种不同的状态
- 进行中:写入器当前正在追加新记录的文件,也称为“打开”文件。
- 待定:已关闭并等待在下一次检查点期间提交到 Delta 日志的文件。这些文件处于最终状态,将不再追加,只在
DeltaCommitter.commit操作期间重命名。 - 已完成:已写入、关闭并成功提交到 Delta 表的文件。
DeltaCommittable
此可提交项要么用于提交一个待处理文件,要么用于清理一个进行中的文件。此外,它包含已写入文件的元数据、应用程序唯一标识符 (appId) 和此可提交项所属的 checkpointId。
DeltaCommitter
DeltaCommitter 负责提交“待定”文件并将其移动到“已完成”状态,以便下游应用程序或系统可以消费它们。它从 DeltaWriter 接收各种 DeltaCommittables,并在本地提交文件,将它们置于“已完成”状态,以便在全局提交期间将它们提交到 Delta 日志。
DeltaGlobalCommitter
全局提交器结合从多个 DeltaCommitter 接收到的多个 DeltaCommittables 列表,并将所有文件提交到 Delta 日志。
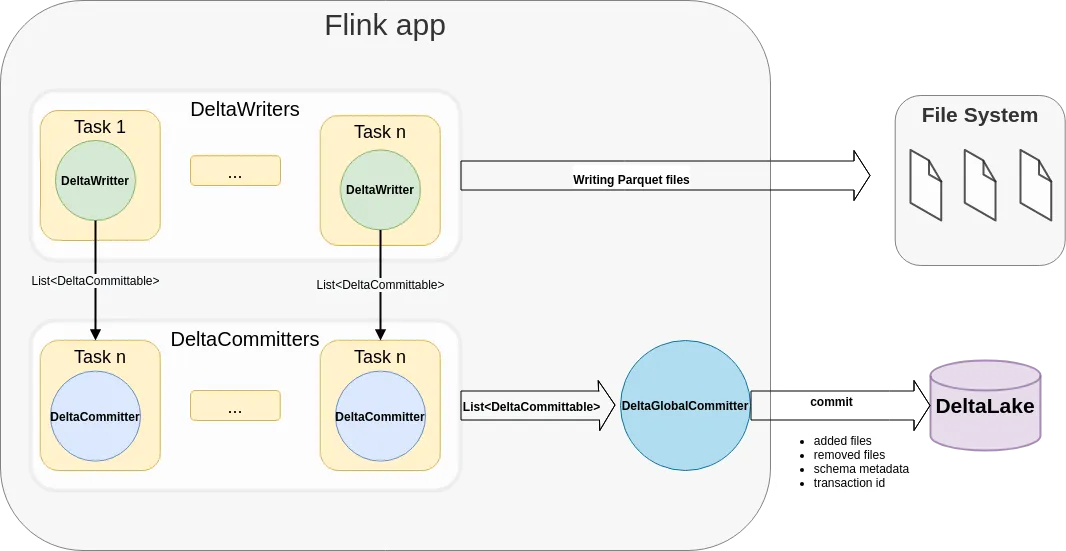
架构
以下架构图说明了数据如何从 Flink 应用程序写入 Delta Lake 表。每个 Flink 作业可以有多个并行 DeltaWriter、DeltaCommitter,并且只有一个 DeltaGlobalCommitter。对于每个检查点,DeltaWriter 将来自多个桶写入器的 DeltaCommittables 列表组合起来,并将其发送到 DeltaCommitter 实例,然后 DeltaCommitter 实例负责本地提交文件并将其标记为准备提交到 Delta 日志。DeltaGlobalCommiter 结合所有 DeltaCommitter 的 DeltaCommittables,并将文件提交到 Delta 日志。
实现 - 将数据从 Flink 写入 Delta Lake 表
Flink/Delta Lake 连接器 是一个 JVM 库,用于利用 Delta Standalone JVM 库 从 Apache Flink 应用程序读取和写入 Delta Lake 表。它包括
- 用于将数据从 Apache Flink 写入 Delta 表的 Sink (#111, 设计文档)
- 请注意,我们还在使用 Flink 的 Table API 创建
DeltaSink(PR #250)。
- 请注意,我们还在使用 Flink 的 Table API 创建
- 使用 Apache Flink 读取 Delta Lake 表的 Source (#110, 仍在进行中)
Flink/Delta Sink 旨在与 Flink >= 1.12 配合使用,并提供 exactly-once 交付保证。此连接器依赖于以下包
delta-standaloneflink-parquetflink-table-commonhadoop-client
1. 非分区表的 Sink 创建
在此示例中,我们展示了如何创建 DeltaSink 并将其插入到现有的 org.apache.flink.streaming.api.datastream.DataStream 中。
package com.example;
import io.delta.flink.sink.DeltaSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
public class DeltaSinkExample {
public DataStream<RowData> createDeltaSink(DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
}2. 分区表的 Sink 创建
在此示例中,我们展示了如何为 org.apache.flink.table.data.RowData 创建 DeltaSink,以使用一个分区列 surname 将数据写入分区表。
package com.example;
import io.delta.flink.sink.DeltaBucketAssigner;
import io.delta.flink.sink.DeltaSink;
import io.delta.flink.sink.DeltaSinkBuilder;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
public class DeltaSinkExample {
public static final RowType ROW_TYPE = new RowType(Arrays.asList(
new RowType.RowField("name", new VarCharType(VarCharType.MAX_LENGTH)),
new RowType.RowField("surname", new VarCharType(VarCharType.MAX_LENGTH)),
new RowType.RowField("age", new IntType())
));
public DataStream<RowData> createDeltaSink(DataStream<RowData> stream,
String deltaTablePath) {
String[] partitionCols = {"surname"};
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.withPartitionColumns(partitionCols)
.build();
stream.sinkTo(deltaSink);
return stream;
}
}有关如何构建和测试的更多信息请点击此处。
下一步是什么?
- 目前仅支持 DeltaSink,因此连接器仅支持写入 Delta 表。如 Apache Flink 的 Delta Source (#110) 中所述,正在开发读取 Delta 表的支持。
- Flink/Delta Sink 目前支持追加模式,对覆盖、upsert 等其他模式的支持将在即将发布的版本中添加。
- 当前版本仅支持 Flink Datastream API。如 扩展 Delta 连接器以支持 Apache Flink 的 Table API (#238) 中所述,计划支持 Flink Table API / SQL 以及用于将 Delta 表元数据存储在外部元数据存储中的 Flink Catalog 实现。